NVIDIA TensorRT is a high-performance deep learning inference library for production environments. Power efficiency and speed of response are two key metrics for deployed deep learning applications, because they directly affect the user experience and the cost of the service provided. Tensor RT automatically optimizes trained neural networks for run-time performance, delivering up to 16x higher energy efficiency (performance per watt) on a Tesla P100 GPU compared to common CPU-only deep learning inference systems (see Figure 1).
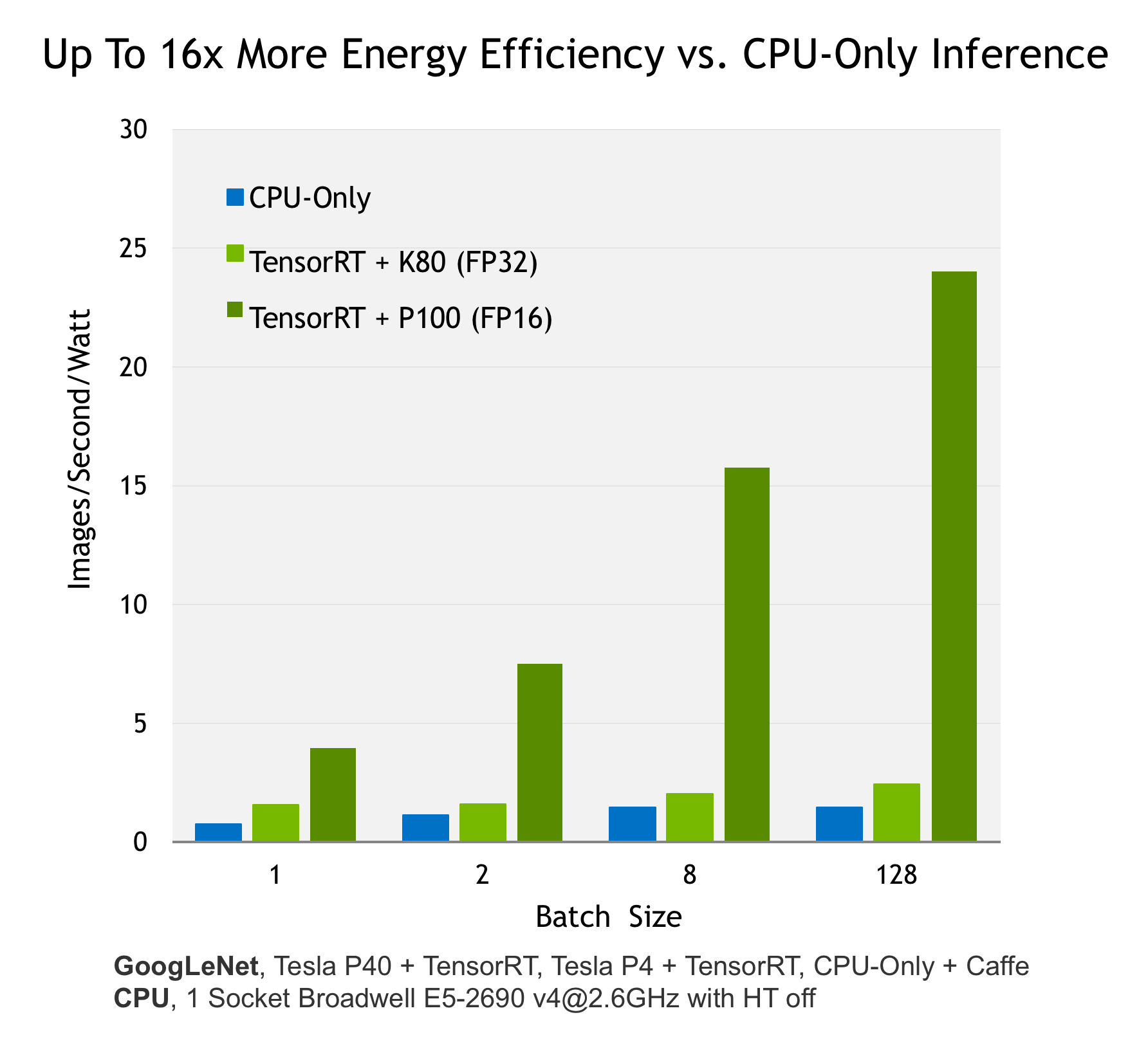
A new NVIDIA Parallel Forall blog post shows how you can use Tensor RT to get the best efficiency and performance out of your trained deep neural network on a GPU-based deployment platform.
Solving a supervised machine learning problem with deep neural networks involves a two-step process. The first step is to train a deep neural network on massive amounts of labeled data using GPUs. The next step–inference–uses the trained model to make predictions from new data. Tensor RT is a high-performance inference engine designed to deliver maximum inference throughput and efficiency for common deep learning applications such as image classification, segmentation, and object detection. Tensor RT optimizes your trained neural networks for run-time performance and delivers GPU-accelerated inference for web/mobile, embedded and automotive applications. NVIDIA TensorRT enables you to easily deploy neural networks to add deep learning capabilities to your products with the highest performance and efficiency. Moreover, TensorRT enables you to leverage the power of GPUs to perform neural network inference using mixed-precision FP16 data. Performing neural network inference using FP16 can reduce memory usage by half and provide higher performance on Tesla P100 and Jetson TX2 GPUs.
Read more >
Get the Best Performance for Your Neural Networks with TensorRT
Apr 03, 2017
Discuss (0)
AI-Generated Summary
- NVIDIA TensorRT is a high-performance deep learning inference library that optimizes trained neural networks for run-time performance in production environments.
- TensorRT delivers up to 16x higher energy efficiency on a Tesla P100 GPU compared to CPU-only deep learning inference systems, making it suitable for applications requiring power efficiency and speed.
- By using TensorRT, developers can easily deploy neural networks to add deep learning capabilities to their products with the highest performance and efficiency, leveraging the power of GPUs for mixed-precision FP16 data.
AI-generated content may summarize information incompletely. Verify important information. Learn more