
Deploying large language models (LLMs) in production environments often requires making hard trade-offs between enhancing user interactivity and increasing system throughput. While enhancing user interactivity requires minimizing time to first token (TTFT), increasing throughput requires increasing tokens per second. Improving one aspect often results in the decline of the other, making it difficult for data centers, cloud service providers (CSPs), and AI application providers to find the right balance.
Leveraging the NVIDIA GH200 Grace Hopper Superchip can minimize these tradeoffs. This post explores how IT leaders and infrastructure decision makers can harness the converged memory architecture of NVIDIA GH200 Grace Hopper Superchip to boost TTFT in multiturn user interactions by up to 2x on the popular Llama 3 70B model, compared to x86-based NVIDIA H100 servers, without any tradeoffs to system throughput.
Key-value cache offloading
LLM models are rapidly gaining adoption across various use cases, including question answering, summarization, and code generation. Before responding to a user’s prompt, these models must build a contextual understanding of the input sequence and any additional information retrieved during the inference request, such as in the case of retrieval-augmented generation (RAG).
This process involves converting the user’s prompt to tokens, and then to highly dense vectors, followed by extensive dot product operations to build a mathematical representation of the relationship between all the token’s in the prompt. The operations are repeated across the different layers of the model. The amount of compute required to generate the contextual understanding of the prompt scales quadratically with the size of the input sequence length.
This compute-intensive process, which generates the key-value cache, or KV cache, is only required during the generation of the first token of the output sequence. Those values are then stored for later reuse when subsequent output tokens are generated, with new values appended as required. This dramatically reduces the amount of compute required to generate new tokens and, ultimately, the time it takes for the LLM to generate an output, improving the user experience.
Reusing a KV cache avoids the need to recompute it from scratch, reducing inference time and compute resources. However, in situations where user interaction with an LLM-based service is intermittent or if multiple LLM users need to interact with the same KV cache but at different times, storing the KV cache in GPU memory for long periods can waste valuable resources that could be better allocated to handle new incoming user requests, reducing overall system throughput.
To address this challenge, the KV cache can be offloaded from GPU memory to higher capacity and lower cost CPU memory, and then reloaded back to GPU memory once idle users resume their activity or new users interact with the same piece of content. This method, known as KV cache offloading, eliminates the need to recompute the KV cache without holding up valuable GPU memory.
Addressing challenges of multiturn user interactions
KV cache offloading benefits content providers integrating generative AI capabilities into their platforms by enabling multiple users to interact with the same content—like summarizing a news article—without recalculating the KV cache for each new user. By computing the KV cache for the news article once, caching it in CPU memory, and then reusing it across multiple users, significant cost and user experience optimizations can be achieved.
This technique is also useful during code generation use cases, particularly in integrated development environments (IDEs) that have incorporated LLM capabilities. In this scenario, one or more developers can submit multiple prompts interacting with a single code script over extended periods of time. Offloading the initial KV cache calculations onto CPU memory and then reloading it for subsequent interactions avoids repeated recalculations and saves valuable GPU and infrastructure resources. Check out the NVIDIA TensorRT-LLM documentation for a detailed how-to guide on offloading and reusing the KV cache.
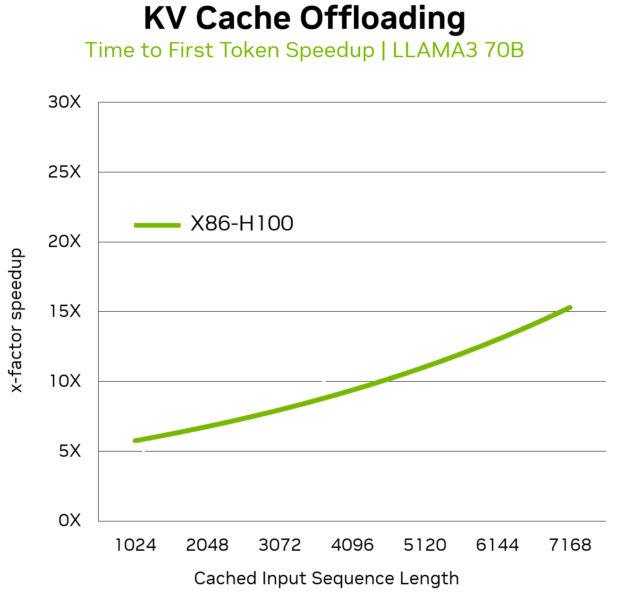
For the Llama 3 70B model running on a server with NVIDIA H100 Tensor Core GPUs connected through PCIe to an x86 host processor, KV cache offloading can accelerate TTFT by up to 14x. This makes it a compelling deployment strategy for data centers, CSPs, and application providers seeking to serve LLMs cost effectively while maintaining positive user experiences.
Accelerating KV cache offloading with NVIDIA GH200 converged CPU-GPU memory
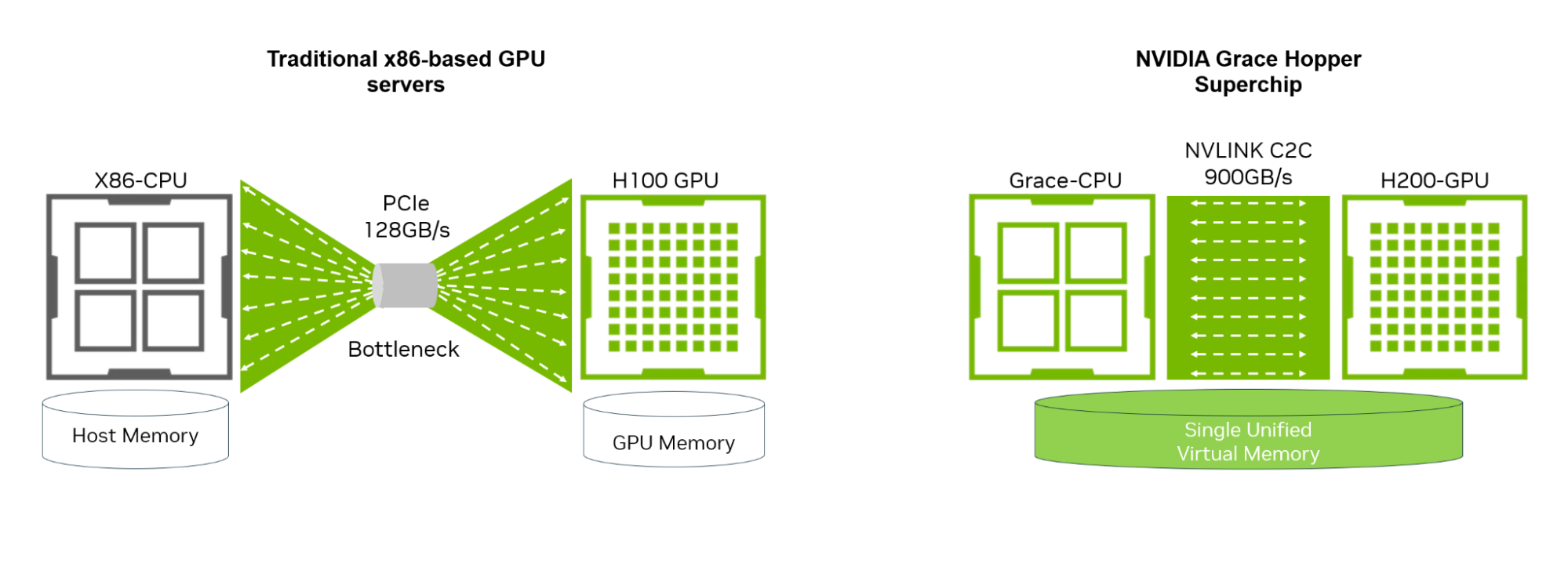
In traditional x86-based GPU servers, the KV cache offloading occurs over the 128 GB/s PCIe connection. For large batch sizes that include multiple multiturn user prompts, the slow PCIe interface can hamper performance, pushing TTFT above the 300 ms – 500 ms threshold typically associated with a realtime user experience.
The NVIDIA GH200 Grace Hopper Superchip overcomes the challenges of low speed PCIe interfaces. NVIDIA GH200 is a new class of superchip that brings together the Arm-based NVIDIA Grace CPU and NVIDIA Hopper GPU architectures using NVLink-C2C interconnect technology. NVLink-C2C delivers up to 900 GB/s total bandwidth between the CPU and the GPU. This is 7x higher bandwidth than the standard PCIe Gen5 lanes found in traditional x86-based GPU servers. Additionally, with GH200, the CPU and GPU share a single per-process page table, enabling all CPU and GPU threads to access all system-allocated memory that can reside on physical CPU or GPU memory.
Offloading KV cache for the Llama 3 70B model on GH200 delivers up to 2x more speedup for TTFT compared to offloading on x86-H100 in multiturn scenarios. This enables organizations deploying LLMs for where multiturn user interactions are frequent to increase user interactivity without any tradeoffs to overall system throughput.

Superior inference on Llama 3 with NVIDIA Grace Hopper and NVLink-C2C
KV cache offloading is gaining traction among CSPs, data centers, and AI application providers due to its ability to improve TTFT in multiturn user interactions without degrading overall system throughput. By leveraging the 900 GB/s NVLink-C2C on the NVIDIA GH200 Superchip, inference on the popular Llama 3 model can be accelerated by up to 2x without any degradation to the system throughput. This enables organizations to improve user experience without additional infrastructure investments.
Today, NVIDIA GH200 powers nine supercomputers around the world, is offered by a wide array of system makers, and can be accessed on demand at cloud providers such as Vultr, Lambda, and CoreWeave. You can test NVIDIA GH200 for free through NVIDIA LaunchPad.
