
In our previous blog post, we demonstrated how reusing the key-value (KV) cache by offloading it to CPU memory can accelerate time to first token (TTFT) by up to 14x on x86-based NVIDIA H100 Tensor Core GPUs and 28x on the NVIDIA GH200 Superchip. In this post, we shed light on KV cache reuse techniques and best practices that can drive even further TTFT speedups.
Introduction to KV cache
LLM models are rapidly being adopted for many tasks, including question-answering, and code generation. To generate a response, these models begin by converting the user’s prompt into tokens, which are then transformed into dense vectors. Extensive dot-product operations follow to mathematically model the relationships between the tokens and build a contextual understanding of the user input. The computational cost of generating this contextual understanding increases quadratically with the length of the input sequence.
This resource-intensive process generates keys and values, which are cached to avoid recomputation when generating subsequent tokens. Reusing the KV cache reduces the computational load and time needed to generate additional tokens—leading to a faster and more efficient user experience.
When reusing the KV cache, careful attention must be given to how long it remains in memory, which components to evict first when memory is full, and when it can be reused for new incoming prompts. Optimizing these factors can lead to incremental performance improvements in KV cache reuse. NVIDIA TensorRT-LLM offers three key features that specifically address these areas.
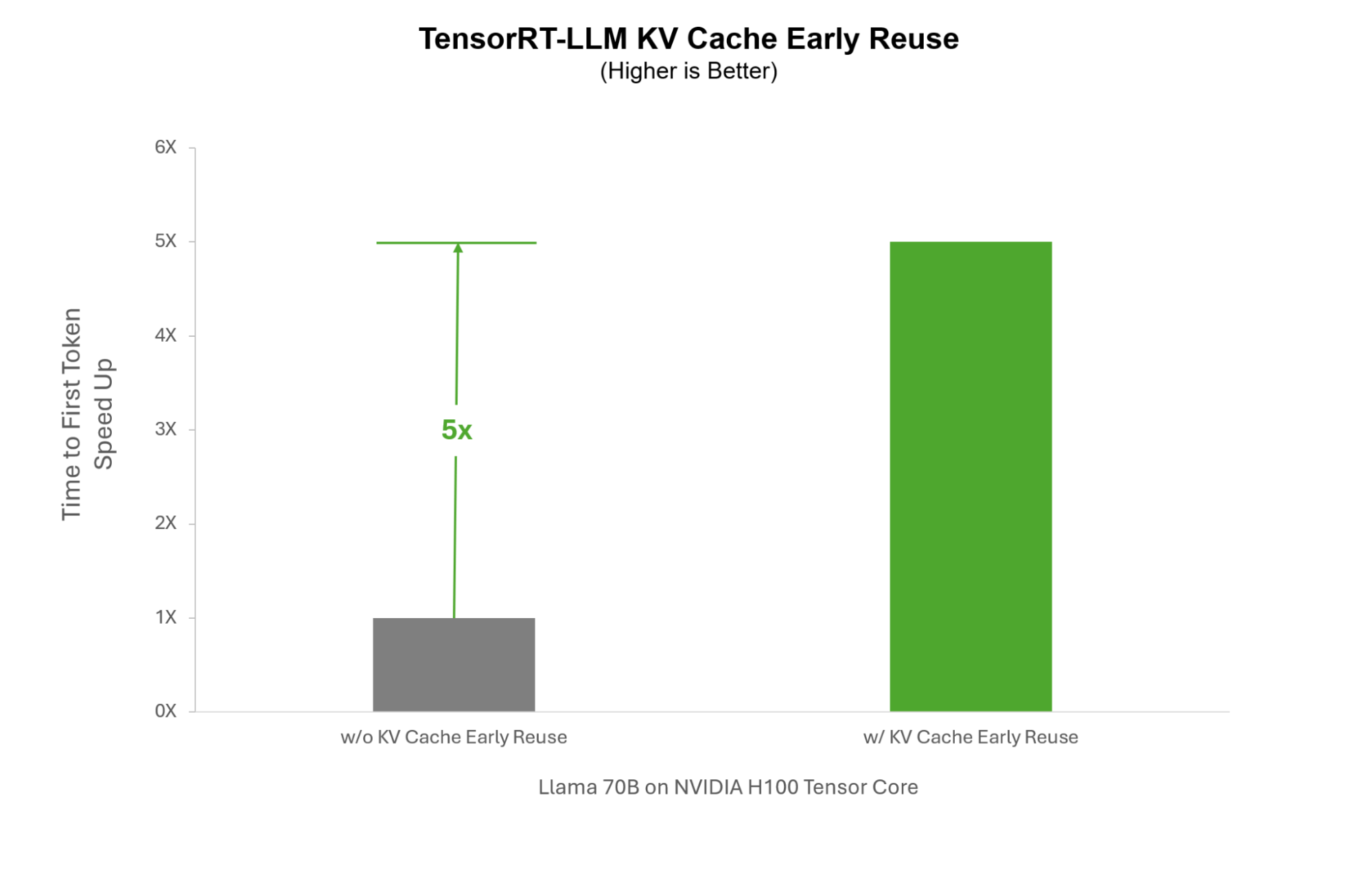
Early KV cache reuse
Traditional reuse algorithms require the entire KV cache computation to be completed before any portions of it can be reused with new user prompts. In scenarios such as enterprise chatbots, where system prompts—predefined instructions added to user queries—are essential to direct the LLM’s responses in line with enterprise guidelines, this method can be inefficient.
When a surge of users interacts with the chatbot simultaneously, each user would require a separate computation of the system prompt KV cache. With TensorRT-LLM, we can instead reuse the system prompt as it is being generated in real time, enabling it to be shared across all users during the burst, rather than recalculating it for each user. This can significantly accelerate inference for use cases requiring system prompts by up to 5x.
Flexible KV cache block sizing
In reuse implementations, only entire cache memory blocks can be allocated for reuse. For example, if the cache memory block size is 64 tokens and KV cache is 80 tokens, only 64 tokens will be stored for reuse, while the remaining 16 tokens will need to be recomputed. However, if the memory block size is reduced to 16 tokens, all 64 tokens can be stored across five memory blocks, eliminating the need for re-computation.
This effect is most pronounced when the input sequences are short. For long input sequences, larger blocks can be more beneficial. As is clear, the more granular the control you have over the KV cache, the better you can optimize it for your specific use case.
TensorRT-LLM provides fine-grained control over KV cache memory blocks, giving developers the ability to chop them into smaller blocks between 64 to 2 tokens. This optimizes the usage of allocated memory, increases reuse rates, and improves TTFT. When running LLAMA70B on NVIDIA H100 Tensor Core GPUs, we can speed up TTFT up to 7% in multi-user environments by reducing KV cache block size from 64 tokens to 8 tokens.

Efficient KV cache eviction protocols
Partitioning the KV cache into smaller blocks and evicting unused ones can be effective for memory optimization, but it introduces dependency complexities. When a specific block is used to generate a response, and the result is stored as a new block, it can form a tree-like structure of dependencies.
Over time, the counters tracking the usage of the source blocks (the branches) may become stale as the dependent nodes (the leaves) are reused. Evicting the source block then requires the eviction of all dependent blocks, which would require recalculation of the KV cache for new user prompts, increasing TTFT.
To address this challenge, TensorRT-LLM includes intelligent eviction algorithms that can trace the dependent nodes from their source nodes and evict dependent nodes first, even if they have more recent reuse counters. This ensures more efficient memory management while preventing unnecessary evictions of dependent blocks.

Getting started with TensorRT-LLM KV cache reuse
Generating KV cache during inference requires a lot of compute and memory resources. Using it efficiently is critical to improving model response, accelerating inference, and increasing system throughput. TensorRT-LLM provides advanced reuse features for developers looking to further optimize TTFT response times for peak performance.
To start using TensorRT-LLM KV cache reuse check out our GitHub documentation.
