
During the 2024 OCP Global Summit, NVIDIA announced that it has contributed the NVIDIA GB200 NVL72 rack and compute and switch tray liquid cooled designs to the Open Compute Project (OCP).
This post provides details about this contribution and explains how it increases the utility of current design standards to meet the high compute density demands of modern data centers. It also explores how the ecosystem is building on top of the GB200 designs, reducing cost and implementation time for new AI data centers.
NVIDIA open-source initiatives
NVIDIA has a rich history of open-source initiatives. NVIDIA engineers have released over 900 software projects on GitHub and have open-sourced essential components of the AI software stack. The NVIDIA Triton Inference Server, for example, is now integrated into all major cloud service providers to serve AI models in production. Additionally, NVIDIA engineers are actively involved in numerous open-source foundations and standards bodies, including the Linux Foundation, the Python Software Foundation, and the PyTorch Foundation.
This commitment to openness extends to the Open Compute Project, where NVIDIA has consistently made design contributions across multiple generations of hardware products. Notable contributions include the NVIDIA HGX H100 baseboard, which has become the de facto baseboard standard for AI servers, and the NVIDIA ConnectX-7 adapter, which now serves as the foundation design of the OCP Network Interface Card (NIC) 3.0.
NVIDIA is also a founding and governance board member of the OCP SAI (Switch Abstraction Interface) project and is the second top contributor to the SONiC (Software for Open Networking in the Cloud) project.
Meeting data center compute demands
The compute power required to train autoregressive transformer models has exploded, growing by a staggering 20,000x over the last 5 years. Meta’s Llama 3.1 405B model, launched earlier this year, required 38 billion petaflops of accelerated compute to train, 50x more than the Llama 2 70B model launched only a year earlier. Training and serving these large models cannot be managed on a single GPU; rather, they must be parallelized across massive GPU clusters.
Parallelism comes in various forms—tensor parallel, pipeline parallel, and expert parallel, each of which provides unique benefits in terms of throughput and user interactivity. Often, these methods are combined to create optimal training and inference deployment strategies to meet user experience requirements and data center budget objectives. For a deeper dive into parallelism techniques for large models, see Demystifying Inference Deployments for Trillion Parameter LLMs.
Importance of multi-GPU interconnect
One common challenge that arises with model parallelism is the high volume of GPU-to-GPU communication. Tensor parallel GPU communication patterns highlight just how interconnected these GPUs are. For example, with AllReduce, every GPU has to send the results of its calculation to every other GPU at every layer of the neural network before the final model output is determined. Any latency during these communications can lead to significant inefficiencies, with GPUs left idle, waiting for the communication protocols to complete. This reduces overall system efficiency and increases the total cost of ownership (TCO).
To combat these communication bottlenecks, data centers and cloud service providers leverage NVIDIA NVSwitch and NVLink interconnect technology. NVSwitch and NVLink are specifically engineered to speed up communication between GPUs, reducing GPU idle time and increasing throughput.
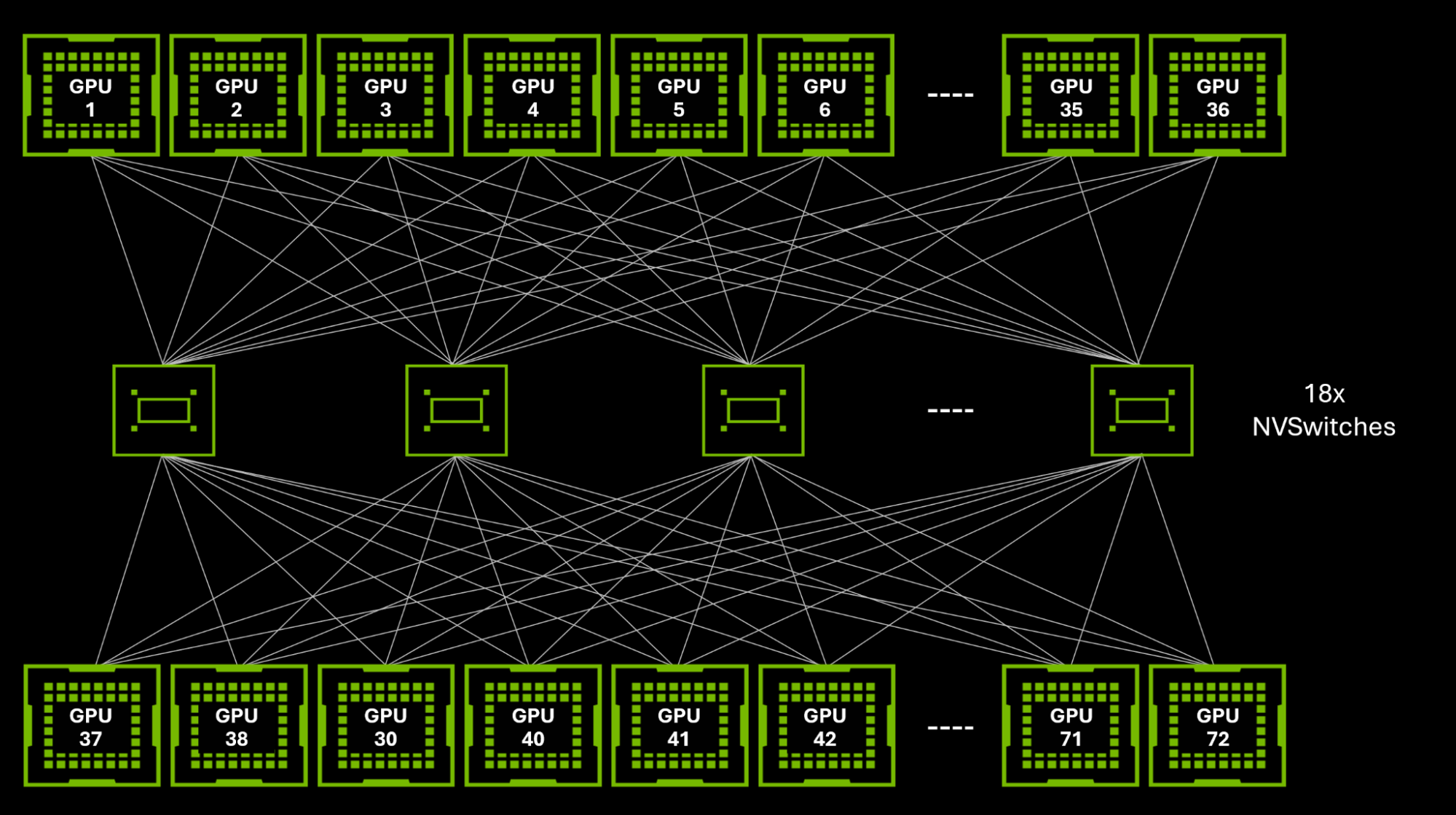
Prior to the introduction of the NVIDIA GB200 NVL72, the maximum number of GPUs that could be connected in a single NVLink domain was limited to eight on an HGX H200 baseboard, with a communication speed of 900 GB/s per GPU. The introduction of the GB200 NVL72 design dramatically expanded these capabilities: the NVLink domain can now support up to 72 NVIDIA Blackwell GPUs, with a communication speed of 1.8 TB/s per GPU, 36x faster than state-of-the-art 400 Gbps Ethernet standards.
This leap in NVLink domain size and speed can accelerate training and inference of trillion-parameter models, such as GPT-MoE-1.8T, by up to 4x and 30x, respectively.

Accelerating infrastructure innovations and contributions
Supporting the weight, mating force, and cooling requirements of such a large GPU NVLink domain in a single rack necessitates careful electrical and mechanical modifications to the rack architecture, along with the compute and switch chassis that house the GPUs and NVSwitch chips.
NVIDIA has worked closely with partners to build on top of existing design principles to increase their utility and support the high compute density and energy efficiency of the GB200 NVL72. The rack, tray, and internal component designs were derived from the NVIDIA MGX architecture. Today, we are excited to open and contribute these designs with OCP to establish a modular and reusable high-compute density infrastructure for AI.
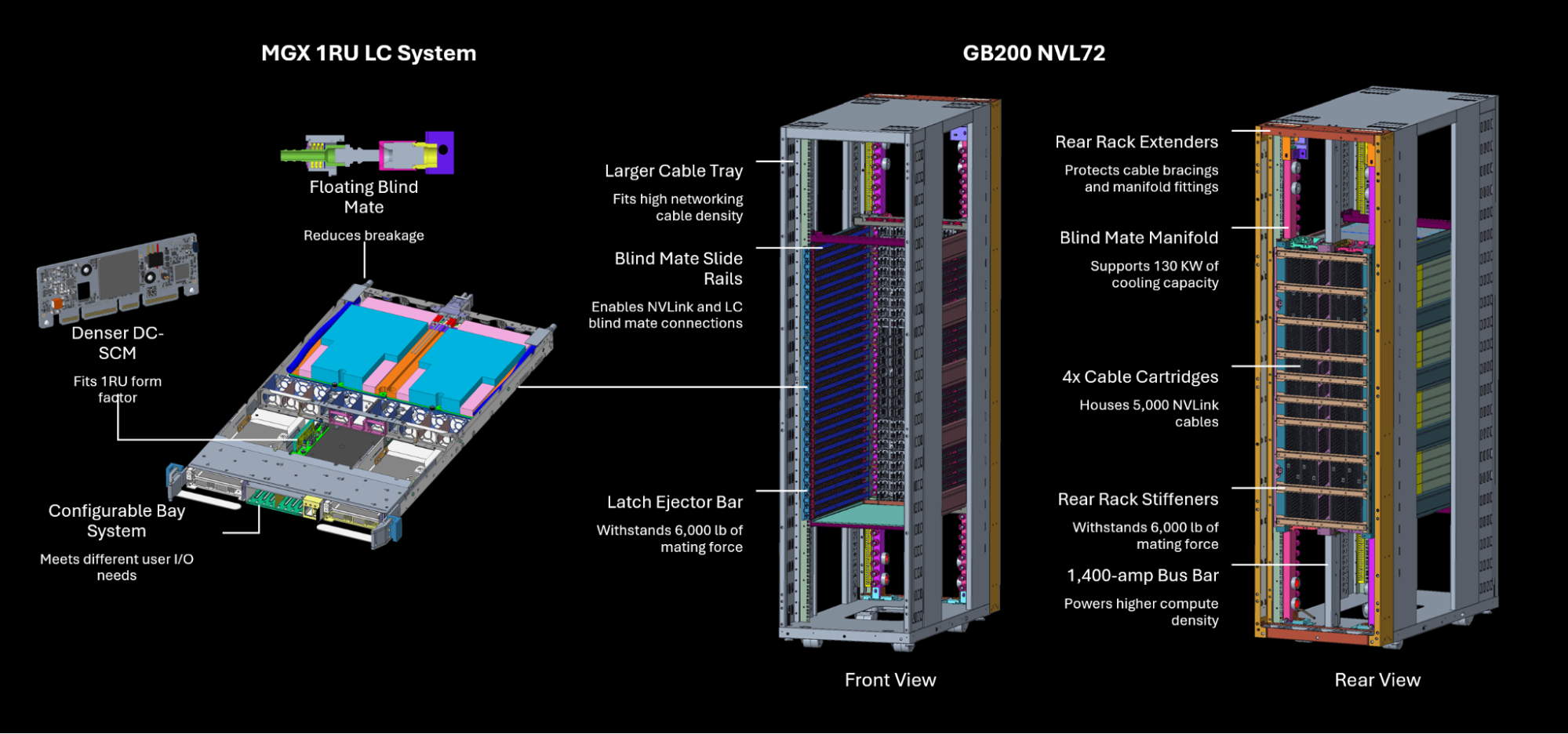
Design modification highlights that NVIDIA is making available include the following.
Rack reinforcements
To efficiently house 18 compute trays, nine switch trays, and four NVLink cartridges supporting over 5,000 copper cables in a single rack, NVIDIA implemented several key modifications to the existing rack designs, including:
- Adaptations to support 19” EIA gear in a 1 RU form factor within the rack to double the space available for IO cabling and improve tray density.
- Adding over 100 lbs of steel reinforcements, significantly increasing the rack’s strength and stability to withstand the 6,000 lbs of mating force generated between its components and frame.
- Incorporating rear rack extensions to safeguard cable bracings and manifold fittings, ensuring the longevity and proper functioning of these elements.
- Introducing blind mate slide rails and latching features to facilitate NVLink installations, liquid cooling system integration, and easier maintenance procedures using blind mate connectors. This rack redesign optimizes space utilization, enhances structural integrity, and improves overall system reliability and maintainability.
High capacity bus bar
To accommodate the high compute density and increased power requirements of the rack, we developed a new design specification for an enhanced high capacity bus bar. This upgraded bus bar maintains the same width as the existing ORV3 but features a deeper profile, significantly increasing its ampacity. The new design supports a substantially higher 1,400 amp current flow, offering a 2x increase in amperage compared to current standards. This enhancement ensures that the bus bar can effectively handle the elevated power demands of modern high-performance computing environments, without requiring additional horizontal space within the rack.
NVLink cartridges
To enable high-speed communication between all 72 NVIDIA Blackwell GPUs in the NVLink domain, we implemented a novel design featuring four NVLink cartridges mounted vertically at the rear of the rack. These cartridges accommodate over 5,000 active copper cables, delivering an impressive aggregate All-to-All bandwidth of 130 TB/s and 260 TB/s AllReduce bandwidth.
This design ensures that each GPU can communicate with every other GPU in the domain at 1.8TB/s, significantly enhancing overall system performance. As part of our submission, we are providing detailed information on the volumetrics and precise mounting locations for these NVLink cartridges, contributing to future implementations and improvements in high-performance computing infrastructure.
Liquid cooling manifolds and floating blind mates
To efficiently manage the 120 KW cooling capacity required for the rack, we’ve implemented direct liquid cooling techniques. Building upon existing designs, we’ve introduced two key innovations. First, we developed an enhanced Blind Mate Liquid Cooling Manifold design, capable of delivering efficient cooling.
Second, we created a novel Floating Blind Mate Tray connection, which effectively distributes coolant to both compute and switch trays significantly improving the ability of the liquid quick disconnects to align and reliably mate in the rack. By leveraging these enhanced liquid cooling solutions, we are able to address the high thermal management demands of modern high-performance computing environments, ensuring optimal performance and longevity of the rack components.
Compute and switch tray mechanical form factors
To accommodate the high compute density of the rack we introduced 1RU liquid-cooled compute and switch tray form factors. We also developed a new, denser DC-SCM (Data Center Secure Control Module) design that’s 10% smaller than the current standard. In addition, we implemented a narrower bus bar connector to maximize available rear panel space. These modifications optimize space utilization while maintaining performance.
Additionally, we created a modular bay design for the compute tray that flexibly adapts to diverse user I/O requirements. These enhancements collectively support 1 RU liquid-cooled form factors for both compute and switch trays, significantly increasing the rack’s computational density and networking capabilities while ensuring efficient cooling and adaptability to various user needs.
New joint NVIDIA GB200 NVL72 reference architecture
At OCP, NVIDIA also announced a new joint GB200 NVL72 reference architecture with Vertiv, a leader in power and cooling technologies and expert in designing, building and servicing high compute density data centers. This new reference architecture will significantly reduce implementation time for CSPs and data centers deploying the NVIDIA Blackwell platform.
The new reference architecture eliminates the need for data centers to develop their own power, cooling, and spacing designs for GB200 NVL72 from scratch. By leveraging Vertiv’s expertise in space saving power management and energy efficient cooling technologies, data centers can deploy 7MW GB200 NVL72 clusters globally reducing implementation time by up to 50%, all while reducing power space footprint and increasing cooling energy efficiency.
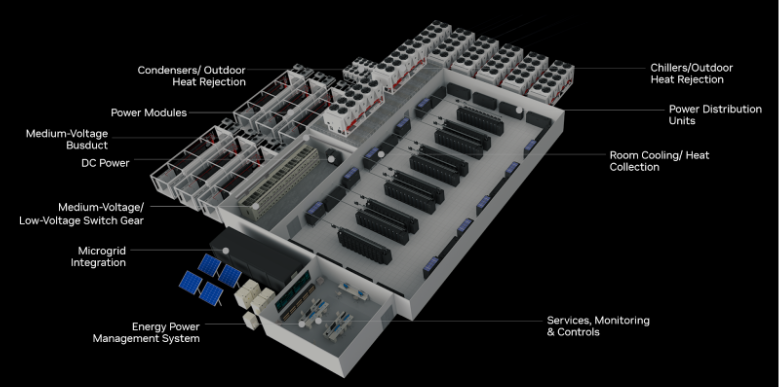
Vertiv is a great example of how data center infrastructure (DCI) providers are building on top of the NVIDIA Blackwell platform. Over 40 DCIs are now building and innovating on top of the Blackwell platform including Amphenol, Auras, Astron, AVC, Beehe, Bellwether, BizLink, Boyd, Chenbro, Chengfwa, CoolIT, Cooler Master, CPC, Danfoss, Delta, Envicool, Flex, Foxconn, Interplex, JPC, Kingslide, Lead Wealth, LiteOn, LOTES, Luxshare, Megmeet, Molex, Motivair, Nidec, Nvent, Ourack, Parker, Pinda, QCT, Refas, Readore, Repon, Rittal, Sanyo Denki, Schneider Electronic, Simula, Staubli, SUNON, Taicheng, TE Connectivity, and Yuans Technology.
Additionally, system partners such as AsRock Rack, ASUS, Dell Technologies, GIGABYTE, Hewlett Packard Enterprise, Hyve, Inventec, MSI, Pegatron, QCT, Supermicro and Wiwynn are creating a wide range of servers based on Blackwell products.
Conclusion
The NVIDIA GB200 NVL72 design represents a significant milestone in the evolution of modern high compute density data centers. By addressing the pressing challenges of training and serving growing AI models and high GPU-to-GPU communication, this contribution accelerates the adoption of energy-efficient high compute density platforms in the data center while reinforcing the importance of collaboration within the open ecosystem. We’re excited to see how the OCP community will leverage and build on top of the GB200 NVL72 design contributions.
To learn more about the NVIDIA GB200 NVL72 OCP contribution, see the OCP specification documentation.
