
As of March 18, 2025, NVIDIA Triton Inference Server is now part of the NVIDIA Dynamo Platform and has been renamed to NVIDIA Dynamo Triton, accordingly.
AI is transforming every industry, addressing grand human scientific challenges such as precision drug discovery and the development of autonomous vehicles, as well as solving commercial problems such as automating the creation of e-commerce product descriptions and extracting insights from legal contracts.
Today, every enterprise is exploring the potential of large language models (LLMs) to create a competitive advantage. NVIDIA Cloud Partners are stepping in to support enterprises with their AI journeys. For example, NexGen Cloud offers its customers the chance to run proofs-of-concept (PoCs) through its on-demand cloud platform, Hyperstack, before committing to large-scale supercloud contracts. You can immediately test-run the latest generation of NVIDIA GPUs, which enables the rapid adoption of additional service layers such as the NVIDIA AI platform.
Following successful pilot programs, many enterprises are now moving these initiatives into production to contribute to the bottom line. This raises an important question: how can enterprises maintain a strong return on investment while still delivering an excellent user experience?
LLMs generate tokens that are mapped to natural language and sent back to the user. Increasing the token throughput of your LLM deployment enables you to serve more users and thus maximizes ROI. A high throughput deployment, however, may result in low user interactivity, the speed at which readable words appear to the user, resulting in a subpar user experience.
As LLMs evolve, striking the right balance between throughput and user interactivity is becoming increasingly challenging, akin to finding a needle in a haystack.
In this post, we discuss different deployment considerations, such as batching, parallelization, and chunking. We analyze how these different deployments affect inference for a mixture of expert (MoE) models. For example, the GPT MoE 1.8T parameter model has subnetworks that independently perform computations and then combine results to produce the final output. We also highlight the unique capabilities of NVIDIA Blackwell and NVIDIA AI inference software, including NVIDIA NIM, that enhance performance compared to previous-generation GPUs.
The balancing act of deploying LLMs in production
Enterprises deploying LLMs in production aim to create new revenue streams or enhance their products’ appeal by integrating virtual assistant-like features. However, they must also prioritize ROI and ensure a compelling user experience.
Maximizing ROI entails serving more user requests without incurring additional infrastructure costs. Achieving this requires batching different user requests and processing them in tandem. This setup maximizes GPU resource utilization (tokens per GPU per second), enabling organizations to amortize their AI investments on the largest possible number of users.
User experience, on the other hand, is determined by the amount of time a user has to wait for a response back from the LLM. This is measured in tokens per second per user.
To maximize user interactivity, smaller batches of user requests are fed to the GPU maximizing the amount of GPU resources allocated to each request. The smaller the batch, the more GPU resources that can be allocated to each request. This method enables the parallelization of compute operations, speeding up the generation of output tokens, but it can result in the underutilization of GPU resources.
As is apparent, these two objectives require making tradeoffs. Maximizing GPU throughput results in lower user interactivity and the reverse.

LLM model evolution further complicates the trade-off problem
This trade-off gets harder with the latest generation of LLMs that have larger numbers of parameters and longer context windows, which enables them to perform more complex cognitive tasks across a larger knowledge base.
The first transformer model introduced in Oct 2018 (BERT) had 340M parameters, a short context window of 512 tokens, and a single feedforward network. This enabled it to fit onto a single GPU.
Some of the most recent models, however, have exceeded 1T parameters, have context windows that exceed 128K tokens, and have multiple feedforward networks (experts) that can operate independently. These models cannot fit on a single GPU, which means that the models must be chopped into smaller chunks and parallelized across multiple GPUs.
Exploring the inference space for trillion-parameter MoE models
For the example of the GPT 1.8T MoE model with 16 experts, assume a fixed budget of 64 GPUs, each with 192 GB of memory.
Using FP4 quantization, you need half a byte to store each parameter, requiring a minimum of 5 GPUs just to store the parameters. For a more optimal user experience, however, you have to split the work across a higher number of GPUs, requiring more than the minimum GPUs to run the workload.
Here are the primary ways to parallelize inference for large models that can’t fit on a single GPU, each of which affects GPU throughput and user interactivity differently:
- Data parallelism
- Tensor parallelism
- Pipeline parallelism
- Expert parallelism
Data parallelism
The data parallelism (DP) method hosts multiple copies of the LLM model on different GPUs or GPU clusters and independently process user request groups on each copy of the model.
This method requires the model to be duplicated on each GPU or GPU cluster, which doesn’t affect GPU throughput or user interactivity. The request groups require no communication between them, resulting in a linear scaling relationship between the number of user requests served and GPU resource allocated.
DP alone is usually not sufficient with the latest generations of LLMs, as their model weights don’t fit on a single GPU memory and require other parallelism methods to be used in tandem.

Tensor parallelism
With the tensor parallelism (TP) method, each layer of the model is split across multiple GPUs and user requests are shared across GPUs or GPU clusters. The results of each request’s GPU computations are recombined hierarchically over a GPU-to-GPU network.
For transformer-based models like GPT, TP can improve user interactivity because each request is allocated more GPU resources, speeding up processing time.
However, scaling TP to large GPU counts without the availability of an ultra-high bandwidth GPU-to-GPU networking fabric can result in networking bottlenecks negatively affecting user interactivity.


Pipeline parallelism
The pipeline parallelism (PP) method works by distributing groups of model layers across different GPUs. The processing pipeline starts on one GPU and continues on to the next with point-to-point communication, sequentially processing the requests across all GPUs in the cluster.
This method can lead to less efficient processing and does not enable the significant optimization of user interactivity. It does help distribute model weights that can’t fit on a single GPU.


Expert parallelism
The expert parallelism (EP) method routes requests to distinct experts in transformer blocks, reducing parameter interactions. Each request is routed to a small set of distinct experts.
This greatly reduces the number of parameters that each request must interact with, as some experts are skipped. Requests must be reconstituted back to their original GPUs after expert processing generating high networking all-to-all communication over the GPU-to-GPU interconnect fabric.
This method can be more efficient than TP because you don’t have to split operations into smaller chunks.
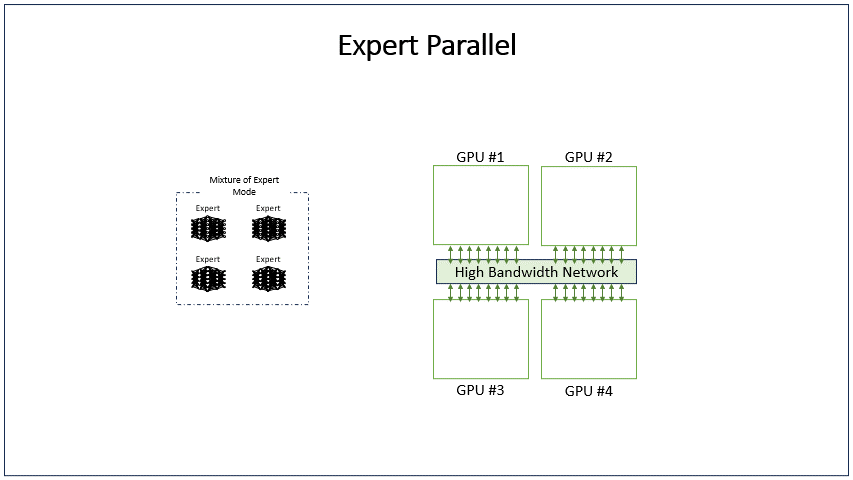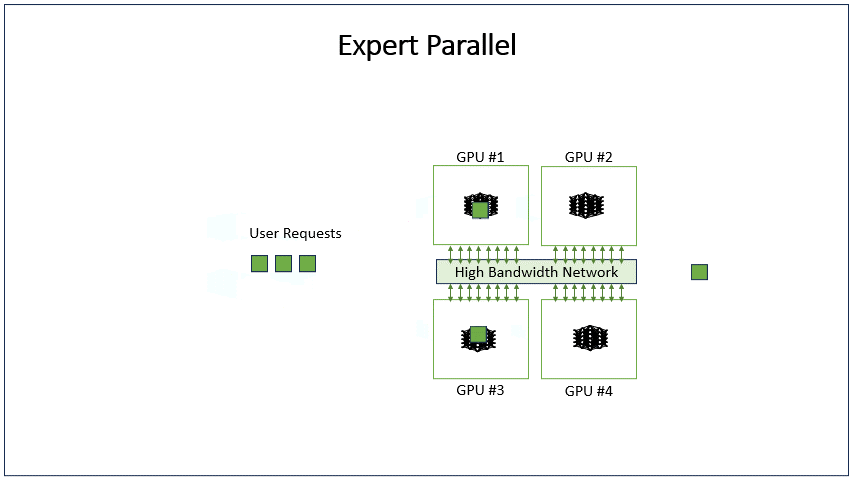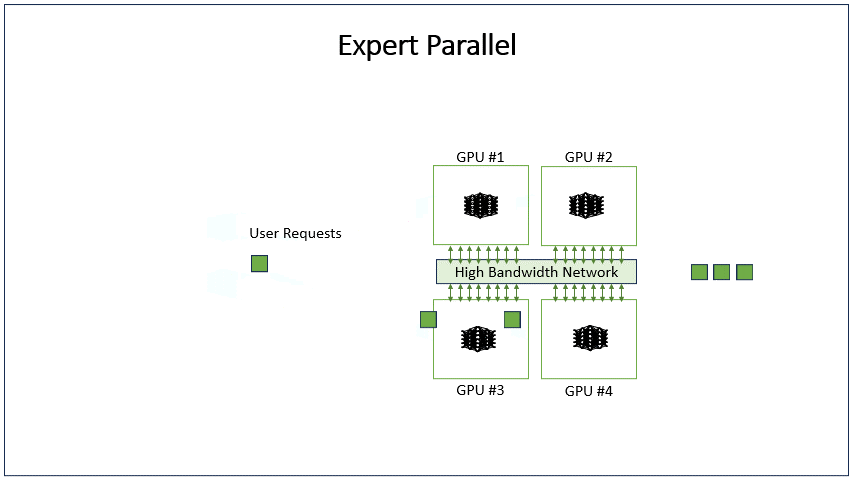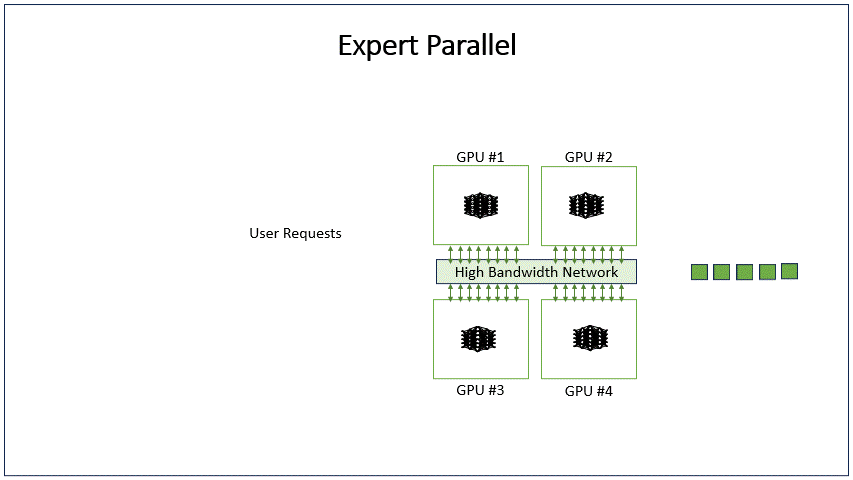
EP is limited by the number of experts in the model. GPT1.8T has 16 experts. Given that we are only considering expert and data parallelism, there are two possible configurations:
- EP8DP8: Load two experts on a single GPU and replicate the configuration eight times using DP.
- EP16DP4: Load a single expert on each GPU and replicate the configuration four times using DP.

Combining parallelism techniques
Parallelism methods can also be combined, which further complicates the tradeoff problem.
There are 73 parallelism configurations that you can build using the 64-GPU budget to serve the model, each of which has a different throughput and user interactivity tradeoff.


Combining different parallelism techniques, however, can yield major improvements in performance without significant tradeoffs.
For example, parallelizing the model using both expert and pipeline parallelism (EP16PP4) delivers 2x improvement in user interactivity with only around 10% loss in GPU throughput compared to expert-only parallelism (EP16DP4 or EP8DP8).
Along the same lines, parallelizing the model using tensor, expert, and pipeline parallelism (TP4EP4PP4) can deliver 3x more GPU throughput compared to tensor-only parallelism (TP64) without any loss in user interactivity.

Maximizing throughput: Strategies for managing prefill and decode phase requirements
When a user submits a request to a model, it undergoes two distinct operational phases: prefill and decode. Each of these phases uses system resources differently.
During prefill, the system processes all the request’s input tokens to calculate intermediate states, which are crucial for building an overall contextual understanding of the request. These intermediate states are then used to generate the first token. This phase has high computational requirements that can be parallelized, leading to high resource utilization and throughput.
In the decode phase, the system sequentially generates output tokens, updating the intermediate states calculated during the Prefill stage for each new token. Since the intensive calculations for intermediate state calculations have already been completed during the Prefill Phase, this phase only processes the newly generated token in the previous stage. As such, it is less computationally intensive and more memory bandwidth intensive and may result in the underutilization of GPU compute resources.
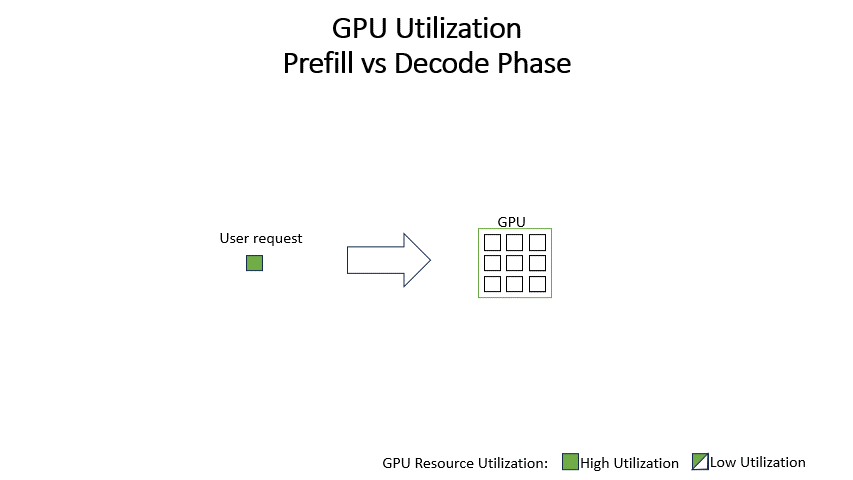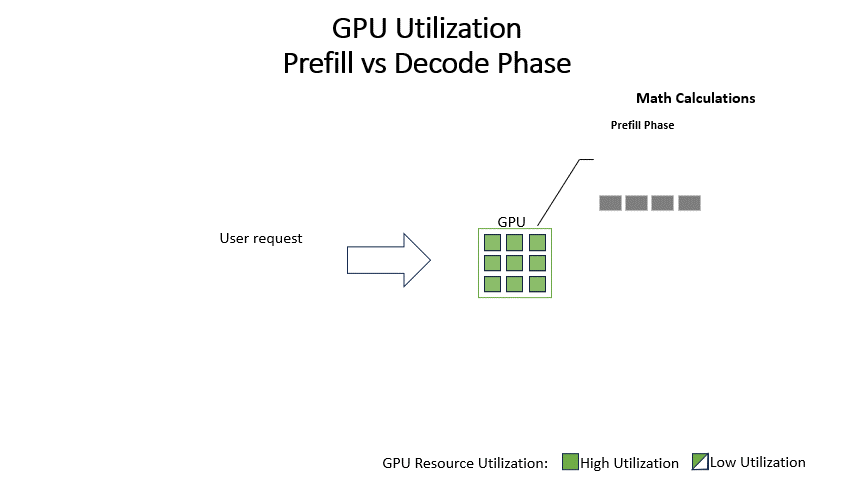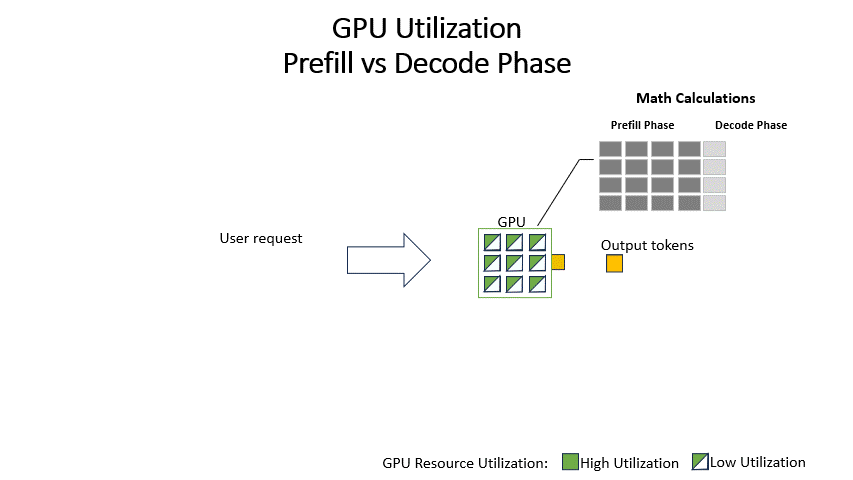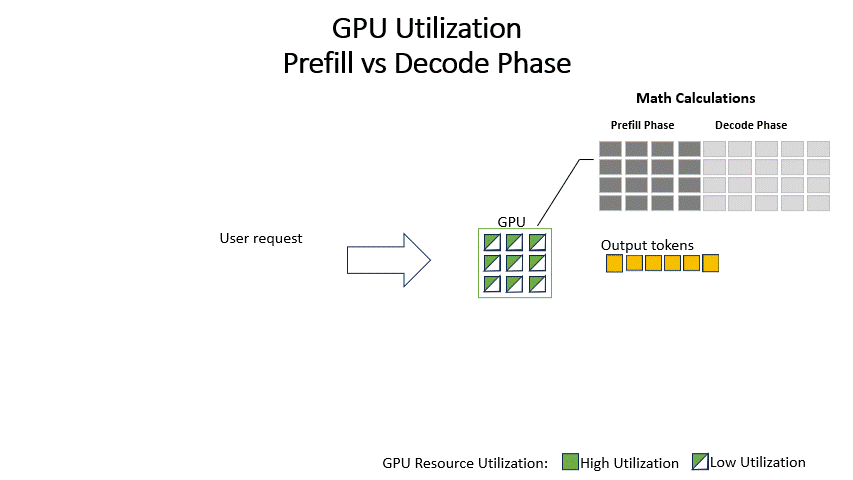
The traditional method of inference, termed static batching, involves completing the prefill and decode phases sequentially for all requests in a batch before proceeding to the next batch. This approach becomes inefficient due to the underutilization of GPUs during the decode phase and the poor user experience as new requests are stalled until all current requests are completed.
Techniques such as inflight batching and chunking are used to solve these issues:
- Inflight batching: You dynamically insert and evict requests even if the current batch is not fully completed.
- Chunking: You break down the prefill phase of requests with long input sequences into smaller chunks. This helps prevent the processing of these requests from becoming a bottleneck in the token generation rate of ongoing requests.
Inflight batching and chunking deliver better GPU utilization while providing a good user experience.
The chunk size affects the user interactivity tradeoff decision. Using a large chunk size lowers the number of iterations required to process prefill sequences, reducing time to first token (TTFT). However, it also increases the time taken to complete the decode phase of ongoing requests, reducing tokens per sec (TPS).
Conversely, a smaller chunk size enables the quicker ejection of tokens, increasing TPS but also increasing TTFT.

Reflecting on the earlier GPT 1.8T example with 64 GPUs, you can analyze how chunking affects the trade-off problem. Begin by examining chunks as small as 128 tokens and progressively increase them in increments of either 128 or 256, up to 8,192 tokens. This significantly expands the search space from the previous 73 configurations to over 2.7K possibilities of parallelism and chunk-length combinations.

To better understand the effect of the various chunk sizes on GPU throughput and user interactivity for the GPT 1.8T MoE model, we picked a few different chunk sizes and parallelism configurations and plotted them separately.

Given an average reading speed of about 5–6 words per second, which translates to 15–18 tokens per second, you can clearly see that you can maximize your GPU throughput at a chunk size of 896 tokens using a configuration of TP2EP16PP2:
- Tensor parallelism on two GPUs
- Expert parallelism on 16 GPUs
- Pipeline parallelism on two GPUs
NVIDIA Blackwell: A new platform to power trillion parameter LLMs
NVIDIA Blackwell is a GPU architecture that features new transformative technologies. It simplifies the complexities of optimizing interference throughput and user interactivity for trillion-parameter LLMs such as GPT 1.8T MoE.

NVIDIA Blackwell features 208B transistors and a second-generation transformer engine. It supports NVIDIA’s fifth-generation NVLink, which boosts 1.8TB/s bidirectional throughput per GPU. NVLink supports a domain of up to 72 NVIDIA Blackwell GPUs, delivering unparalleled acceleration to the GPU-to-GPU operations that occur in multi-GPU deployments of trillion-parameter models with parallelism combinations.
Combined, these features enable NVIDIA Blackwell to deliver high throughput gains, compared to the prior-generation NVIDIA H100 Hopper GPU, for every possible user interactivity requirement. More specifically, NVIDIA Blackwell can deliver 30x more throughput at reading speeds of 20 tokens per user per second (5–6 words per second) using TP2EP16PP2 and a chunk size of 896 tokens.
NVIDIA NIM is a collection of easy-to-use inference microservices for rapid production deployment of the latest AI models including open-source community models and NVIDIA AI Foundation models. It is licensed as a part of NVIDIA AI Enterprise.
NIM is built on NVIDIA inference software including TensorRT-LLM, which enables advanced multi-GPU and multi-node primitives. TensorRT-LLM also delivers advanced chunking and inflight batching capabilities.
Enterprises deploying LLMs as part of a custom AI pipeline can use NVIDIA Triton Inference Server, part of NVIDIA NIM, to create model ensembles that connect multiple AI models and custom business logic into a single pipeline.
Next steps
Organizations can now parallelize trillion-parameter models during the model compilation phase using data, tensor, pipeline, and expert parallelism techniques with just a few lines of code.
Together, NVIDIA Blackwell, TensorRT-LLM, and NVIDIA Triton Inference Server offer organizations the freedom to explore the entire inference search space of trillion-parameter MoE models and identify the ideal throughput and user interactivity combination to meet their service level agreement, no matter the desired throughput and user interactivity combination.
