
Spark MLlib is a key component of Apache Spark for large-scale machine learning and provides built-in implementations of many popular machine learning algorithms. These implementations were created a decade ago, but do not leverage modern computing accelerators, such as NVIDIA GPUs.
To address this gap, we have recently open-sourced Spark RAPIDS ML (NVIDIA/spark-rapids-ml), a Python package providing GPU acceleration for PySpark ML applications. In doing so, we achieved the following key objectives:
- API: Fully retain the PySpark MLlib DataFrames-based API for Spark ML algorithms, maintaining compatibility with Spark’s Pipeline API, CrossValidation, and so on. Enable switching between baseline Spark ML implementations and GPU-accelerated implementations with minimal code changes (that is, Python package import statement changes at the most).
- Speedup and cost savings: Demonstrate significant performance gains and cost savings from GPU acceleration for Spark ML algorithms.
- Architecture: Use the extensive work already done at NVIDIA to accelerate traditional ML algorithms.
You can download the Spark RAPIDS ML package from the NVIDIA/spark-rapids-ml GitHub repository under the Apache v2 license. The initial release provides GPU acceleration for the following Spark ML algorithms:
- PCA
- K-means clustering
- Linear regression with ridge and elastic net regularization
- Random forest classification and regression
The release also includes a Spark ML API-compatible version of the following:
- K-nearest neighbors
We made this initial choice of algorithms because of our third objective: to use existing NVIDIA-accelerated ML libraries as much as possible.
Specifically, we opted to build Spark RAPIDS ML upon the OSS RAPIDS cuML library and provide PySpark API wrappers for existing cuML distributed implementations of algorithms also offered in Spark ML.
RAPIDS cuML also has GPU-accelerated distributed implementations of some popular algorithms not in Spark ML and we have included k-nearest neighbors as a proof of concept of providing Spark ML API compatibility for these algorithms.
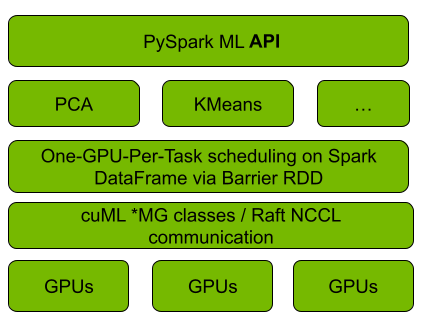
Figure 1 shows that the Spark RAPIDS ML integration with cuML uses Spark’s Barrier RDD synchronization and communication mechanism to bootstrap cuML’s distributed algorithm implementations on top of a running Spark cluster, with each cuML worker mapped onto one Spark task per GPU. Algorithm computation and inter-worker communication are deferred to cuML. For the latter, cuML relies on the NCCL and UCX libraries to speed up inter-GPU communication, which Spark RAPIDS ML uses as well.

API for ease of adoption
As a core design goal, Spark RAPIDS ML API is designed for minimal code changes to ease adoption by Spark ML developers and to facilitate the migration of existing Spark ML applications.
The following code examples are for baseline Spark ML and Spark RAPIDS ML for KMeans, where only a Python import statement is changed.
More generally, the Spark RAPIDS ML-accelerated versions of the supported algorithms implement their Spark ML counterpart’s estimator-model API. They have matching (in name and data typing) constructor parameters, getters and setters, and model attributes and methods, to the extent supported by the underlying cuML implementations for the various algorithms.
The corresponding fit and transform methods accept Spark DataFrames with VectorUDT, Spark SQL array, or scalar feature columns (with Float or Double element types). Currently, only dense vectors are supported.
Speedup and cost savings
In this section, we provide preliminary benchmarking results comparing the GPU-accelerated Spark RAPIDS ML and baseline CPU-based Spark ML versions of the supported algorithms.
The benchmarks were run in three-node Spark clusters (one driver, two executors) on Databricks’ AWS-hosted Spark service with the following hardware configurations:
- In the CPU cluster, the m5.2xlarge executor and driver nodes each have eight CPU cores and 32 GB of RAM.
- In the GPU cluster, the g5.2xlarge executor nodes each have the same CPU and RAM as the m5.2xlarge nodes, along with NVIDIA 24-GB A10 GPUs.
The benchmarks were run on 12-GB synthetic data sets suitable for the corresponding algorithms. They were generated using sci-kit-learn’s synthetic data-generating routines and stored in Parquet format on Amazon S3. The runtimes are for end-to-end data loading from Amazon S3 plus fit method execution. We also used the spark-rapids plugin to accelerate data loading for GPU runs.
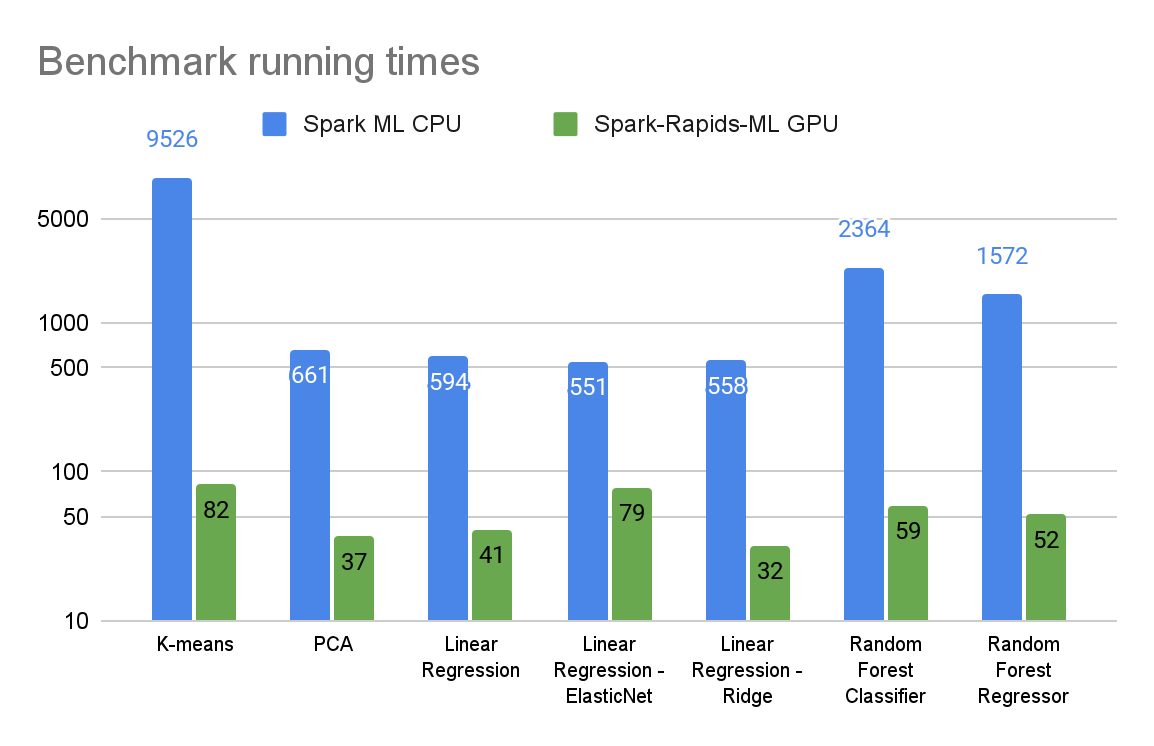
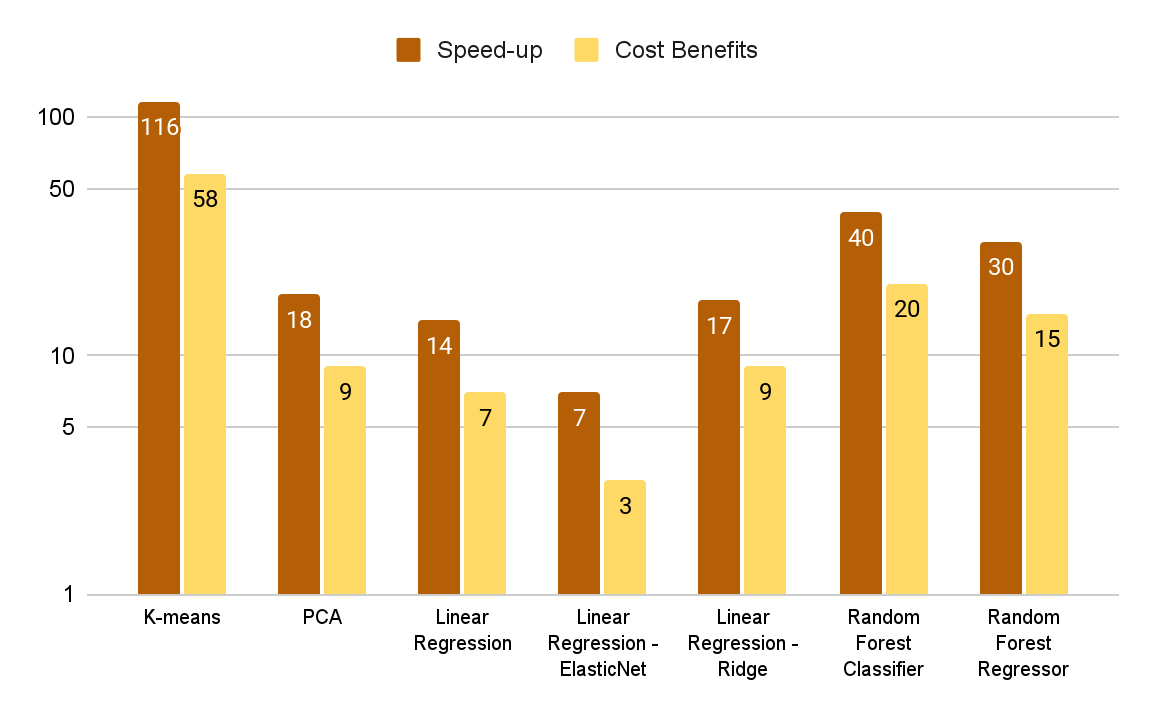
Figures 2 and 3 summarize the benchmark results for various algorithms. The data set and algorithm parameters were selected to represent highly compute-intensive ML workloads.
The cost benefits graph in Figure 3 shows the ratio of CPU compute cost to GPU compute cost as determined by the benchmark running times and Databricks’ compute cost model (DBUs plus Amazon EC2 instance costs). While the GPU cluster costs more on an hourly basis, it is significantly more cost-effective end-to-end for these benchmarks due to more-than-compensating faster runtimes.
For more information and the steps to reproduce these results, see the NVIDIA/spark-rapids-ml GitHub repo.
Next steps
With Spark RAPIDS ML, you can dramatically speed up Spark ML applications with a one-line code change and reduce your computing costs.
- To access Spark RAPIDS ML source code and documentation, see the NVIDIA/spark-rapids-ml GitHub repo.
- To try out Spark RAPIDS ML, follow the Spark RAPIDS ML Getting Started guide.
- To provide feedback, file GitHub issues at NVIDIA/spark-rapids-ml.
