Efficient processing of string data is vital for many data science applications. To extract valuable information from string data, RAPIDS libcudf provides powerful tools for accelerating string data transformations. libcudf is a C++ GPU DataFrame library used for loading, joining, aggregating, and filtering data.
In data science, string data represents speech, text, genetic sequences, logging, and many other types of information. When working with string data for machine learning and feature engineering, the data must frequently be normalized and transformed before it can be applied to specific use cases. libcudf provides both general purpose APIs as well as device-side utilities to enable a wide range of custom string operations.
This post demonstrates how to skillfully transform strings columns with the libcudf general purpose API. You’ll gain new knowledge on how to unlock peak performance using custom kernels and libcudf device-side utilities. This post also walks you through examples of how to best manage GPU memory and efficiently construct libcudf columns to speed up your string transformations.

Introducing Arrow format for strings columns
libcudf stores string data in device memory using Arrow format, which represents strings columns as two child columns: chars and offsets (Figure 1).
The chars column holds the string data as UTF-8 encoded character bytes that are stored contiguously in memory.
The offsets column contains an increasing sequence of integers which are byte positions identifying the start of each individual string within the chars data array. The final offset element is the total number of bytes in the chars column. This means the size of an individual string at row i is defined as (offsets[i+1]-offsets[i]).

chars and offsets child columnsExample of string redaction function
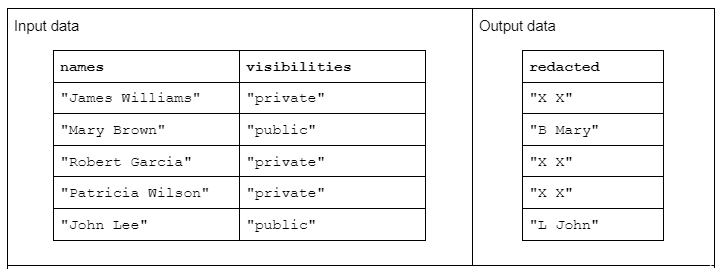
To illustrate an example string transformation, consider a function that receives two input strings columns and produces one redacted output strings column.
The input data has the following form: a “names” column containing first and last names separated by a space and a “visibilities” column containing the status of “public” or “private.”
We propose the “redact” function that operates on the input data to produce output data consisting of the first initial of the last name followed by a space and the entire first name. However, if the corresponding visibility column is “private” then the output string should be fully redacted as “X X.”
Transforming strings with the libcudf API
First, string transformation can be accomplished using the libcudf strings API. The general purpose API is an excellent starting point and a good baseline for comparing performance.
The API functions operate on an entire strings column, launching at least one kernel per function and assigning one thread per string. Each thread handles a single row of data in parallel across the GPU and outputs a single row as part of a new output column.
To complete the redact example function using the general purpose API, follow these steps:
- Convert the “visibilities” strings column into a Boolean column using
contains - Create a new strings column from the names column by copying “X X” whenever the corresponding row entry in the boolean column is “false”
- Split the “redacted” column into first name and last name columns
- Slice the first character of the last names as the last name initials
- Build the output column by concatenating the last initials column and the first names column with space (” “) separator.
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible);
// redact names
auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view());
// split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1);
// assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
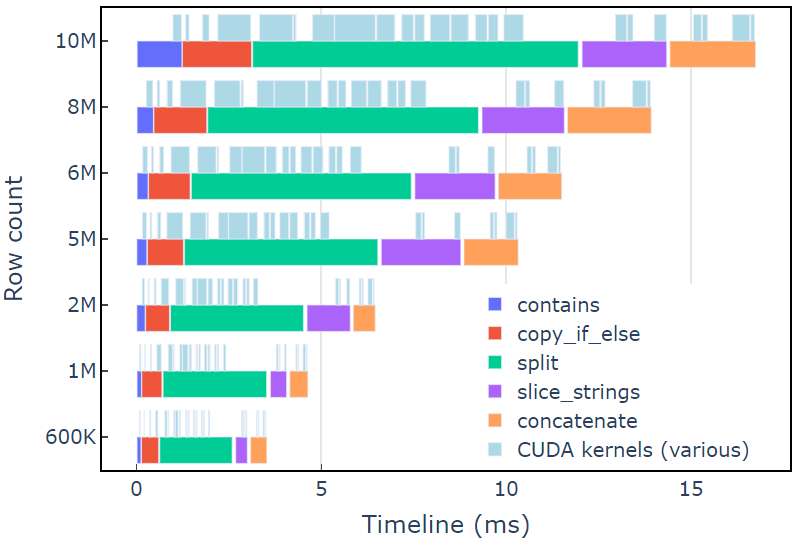
This approach takes about 3.5 ms on an A6000 with 600K rows of data. This example uses contains, copy_if_else, split, slice_strings and concatenate to accomplish a custom string transformation. A profiling analysis with Nsight Systems shows that the split function takes the longest amount of time, followed by slice_strings and concatenate.
Figure 2 shows profiling data from Nsight Systems of the redact example, showing end-to-end string processing at up to ~600 million elements per second. The regions correspond to NVTX ranges associated with each function. Light blue ranges correspond to periods where CUDA kernels are running.
Transforming strings with a custom kernel
The libcudf strings API is a fast and efficient toolkit for transforming strings, but sometimes performance-critical functions need to run even faster. A key source of extra work in the libcudf strings API is the creation of at least one new strings column in global device memory for each API call, opening up the opportunity to combine multiple API calls into a custom kernel.
Performance limitations in kernel malloc calls
First, we’ll build a custom kernel to implement the redact example transformation. When designing this kernel, we must keep in mind that libcudf strings columns are immutable.
Strings columns cannot be changed in place because the character bytes are stored contiguously, and any changes to the length of a string would invalidate the offsets data. Therefore the redact_kernel custom kernel generates a new strings column by using a libcudf column factory to build both offsets and chars child columns.
In this first approach, the output string for each row is created in dynamic device memory using a malloc call inside the kernel. The custom kernel output is a vector of device pointers to each row output, and this vector serves as input to a strings column factory.
The custom kernel accepts a cudf::column_device_view to access the strings column data and uses the element method to return a cudf::string_view representing the string data at the specified row index. The kernel output is a vector of type cudf::string_view that holds pointers to the device memory containing the output string and the size of that string in bytes.
The cudf::string_view class is similar to the std::string_view class but is implemented specifically for libcudf and wraps a fixed length of character data in device memory encoded as UTF-8. It has many of the same features (find and substr functions, for example) and limitations (no null terminator) as the std counterpart. A cudf::string_view represents a character sequence stored in device memory and so we can use it here to record the malloc’d memory for an output vector.
Malloc kernel
// note the column_device_view inputs to the kernel
__global__ void redact_kernel(cudf::column_device_view const d_names,
cudf::column_device_view const d_visibilities,
cudf::string_view redaction,
cudf::string_view* d_output)
{
// get index for this thread
auto index = threadIdx.x + blockIdx.x * blockDim.x;
if (index >= d_names.size()) return;
auto const visible = cudf::string_view("public", 6);
auto const name = d_names.element<cudf::string_view>(index);
auto const vis = d_visibilities.element<cudf::string_view>(index);
if (vis == visible) {
auto const space_idx = name.find(' ');
auto const first = name.substr(0, space_idx);
auto const last_initial = name.substr(space_idx + 1, 1);
auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1;
char* output_ptr = static_cast<char*>(malloc(output_size));
// build output string
d_output[index] = cudf::string_view{output_ptr, output_size};
memcpy(output_ptr, last_initial.data(), last_initial.size_bytes());
output_ptr += last_initial.size_bytes();
*output_ptr++ = ' ';
memcpy(output_ptr, first.data(), first.size_bytes());
} else {
d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()};
}
}
__global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{
auto index = threadIdx.x + blockIdx.x * blockDim.x;
if (index >= count) return;
auto ptr = const_cast<char*>(d_output[index].data());
if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
This might seem like a reasonable approach, until the kernel performance is measured. This approach takes about 108 ms on an A6000 with 600K rows of data—more than 30x slower than the solution provided above using the libcudf strings API.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
The main bottleneck is the malloc/free calls inside the two kernels here. The CUDA dynamic device memory requires malloc/free calls in a kernel to be synchronized, causing parallel execution to degenerate into sequential execution.
Pre-allocating working memory to eliminate bottlenecks
Eliminate the malloc/free bottleneck by replacing the malloc/free calls in the kernel with pre-allocated working memory before launching the kernel.
For the redact example, the output size of each string in this example should be no larger than the input string itself, since the logic only removes characters. Therefore, a single device memory buffer can be used with the same size as the input buffer. Use the input offsets to locate each row position.
Accessing the strings column’s offsets involves wrapping the cudf::column_view with a cudf::strings_column_view and calling its offsets_begin method. The size of the chars child column can also be accessed using the chars_size method. Then a rmm::device_uvector is pre-allocated before calling the kernel to store the character output data.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector<char>(scv.chars_size(), stream);
Pre-allocated kernel
__global__ void redact_kernel(cudf::column_device_view const d_names,
cudf::column_device_view const d_visibilities,
cudf::string_view redaction,
char* working_memory,
cudf::offset_type const* d_offsets,
cudf::string_view* d_output)
{
auto index = threadIdx.x + blockIdx.x * blockDim.x;
if (index >= d_names.size()) return;
auto const visible = cudf::string_view("public", 6);
auto const name = d_names.element<cudf::string_view>(index);
auto const vis = d_visibilities.element<cudf::string_view>(index);
if (vis == visible) {
auto const space_idx = name.find(' ');
auto const first = name.substr(0, space_idx);
auto const last_initial = name.substr(space_idx + 1, 1);
auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1;
// resolve output string location
char* output_ptr = working_memory + d_offsets[index];
d_output[index] = cudf::string_view{output_ptr, output_size};
// build output string into output_ptr
memcpy(output_ptr, last_initial.data(), last_initial.size_bytes());
output_ptr += last_initial.size_bytes();
*output_ptr++ = ' ';
memcpy(output_ptr, first.data(), first.size_bytes());
} else {
d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()};
}
}
The kernel outputs a vector of cudf::string_view objects which is passed to the cudf::make_strings_column factory function. The second parameter to this function is used for identifying null entries in the output column. The examples in this post do not have null entries, so a nullptr placeholder cudf::string_view{nullptr,0} is used.
auto str_ptrs = rmm::device_uvector<cudf::string_view>(names.size(), stream);
redact_kernel<<<blocks, block_size, 0, stream.value()>>>(*d_names,
*d_visibilities,
d_redaction.value(),
working_memory.data(),
offsets,
str_ptrs.data());
auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
This approach takes about 1.1 ms on an A6000 with 600K rows of data and therefore beats the baseline by more than 2x. The approximate breakdown is shown below:
redact_kernel 66us
make_strings_column 400usThe remaining time is spent in cudaMalloc, cudaFree, cudaMemcpy, which is typical of the overhead for managing temporary instances of rmm::device_uvector. This method works well if all of the output strings are guaranteed to be the same size or smaller as the input strings.
Overall, switching to a bulk working memory allocation with RAPIDS RMM is a significant improvement and a good solution for a custom strings function.
Optimizing column creation for faster compute times
Is there a way to improve this even further? The bottleneck is now the cudf::make_strings_column factory function which builds the two strings column components, offsets and chars, from the vector of cudf::string_view objects.
In libcudf, many factory functions are included for building strings columns. The factory function used in the previous examples takes a cudf::device_span of cudf::string_view objects and then constructs the column by performing a gather on the underlying character data to build the offsets and character child columns. A rmm::device_uvector is automatically convertible to a cudf::device_span without copying any data.
However, if the vector of characters and the vector of offsets are built directly, then a different factory function can be used, which simply creates the strings column without requiring a gather to copy the data.
The sizes_kernel makes a first pass over the input data to compute the exact output size of each output row:
Optimized kernel: Part 1
__global__ void sizes_kernel(cudf::column_device_view const d_names,
cudf::column_device_view const d_visibilities,
cudf::size_type* d_sizes)
{
auto index = threadIdx.x + blockIdx.x * blockDim.x;
if (index >= d_names.size()) return;
auto const visible = cudf::string_view("public", 6);
auto const redaction = cudf::string_view("X X", 3);
auto const name = d_names.element<cudf::string_view>(index);
auto const vis = d_visibilities.element<cudf::string_view>(index);
cudf::size_type result = redaction.size_bytes(); // init to redaction size
if (vis == visible) {
auto const space_idx = name.find(' ');
auto const first = name.substr(0, space_idx);
auto const last_initial = name.substr(space_idx + 1, 1);
result = first.size_bytes() + last_initial.size_bytes() + 1;
}
d_sizes[index] = result;
}
The output sizes are then converted to offsets by performing an in-place exclusive_scan. Note that the offsets vector was created with names.size()+1 elements. The last entry will be the total number of bytes (all the sizes added together) while the first entry will be 0. These are both handled by the exclusive_scan call. The size of the chars column is retrieved from the last entry of the offsets column to build the chars vector.
// create offsets vector
auto offsets = rmm::device_uvector<cudf::size_type>(names.size() + 1, stream);
// compute output sizes
sizes_kernel<<<blocks, block_size, 0, stream.value()>>>(
*d_names, *d_visibilities, offsets.data());
thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
The redact_kernel logic is still very much the same except that it accepts the output d_offsets vector to resolve each row’s output location:
Optimized kernel: Part 2
__global__ void redact_kernel(cudf::column_device_view const d_names,
cudf::column_device_view const d_visibilities,
cudf::size_type const* d_offsets,
char* d_chars)
{
auto index = threadIdx.x + blockIdx.x * blockDim.x;
if (index >= d_names.size()) return;
auto const visible = cudf::string_view("public", 6);
auto const redaction = cudf::string_view("X X", 3);
// resolve output_ptr using the offsets vector
char* output_ptr = d_chars + d_offsets[index];
auto const name = d_names.element<cudf::string_view>(index);
auto const vis = d_visibilities.element<cudf::string_view>(index);
if (vis == visible) {
auto const space_idx = name.find(' ');
auto const first = name.substr(0, space_idx);
auto const last_initial = name.substr(space_idx + 1, 1);
auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1;
// build output string
memcpy(output_ptr, last_initial.data(), last_initial.size_bytes());
output_ptr += last_initial.size_bytes();
*output_ptr++ = ' ';
memcpy(output_ptr, first.data(), first.size_bytes());
} else {
memcpy(output_ptr, redaction.data(), redaction.size_bytes());
}
}
The size of the output d_chars column is retrieved from the last entry of the d_offsets column to allocate the chars vector. The kernel launches with the pre-computed offsets vector and returns the populated chars vector. Finally, the libcudf strings column factory creates the output strings columns.
This cudf::make_strings_column factory function builds the strings column without making a copy of the data. The offsets data and chars data are already in the correct, expected format and this factory simply moves the data from each vector and creates the column structure around it. Once completed, the rmm::device_uvectors for offsets and chars are empty, their data having been moved into the output column.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector<char>(output_size, stream);
redact_kernel<<<blocks, block_size, 0, stream.value()>>>(
*d_names, *d_visibilities, offsets.data(), chars.data());
// from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
This approach takes about 300 us (0.3 ms) on an A6000 with 600K rows of data and improves over the previous approach by more than 2x. You might notice that sizes_kernel and redact_kernel share much of the same logic: once to measure the size of the output and then again to populate the output.
From a code quality perspective, it is beneficial to refactor the transformation as a device function called by both the sizes and redact kernels. From a performance perspective, you might be surprised to see the computational cost of the transformation being paid twice.
The benefits for memory management and more efficient column creation often outweigh the computation cost of performing the transformation twice.
Table 2 shows the compute time, kernel count, and bytes processed for the four solutions discussed in this post. “Total kernel launches” reflects the total number of kernels launched, including both compute and helper kernels. “Total bytes processed” is the cumulative DRAM read plus write throughput and “minimum bytes processed” is an average of 37.9 bytes per row for our test inputs and outputs. The ideal “memory bandwidth limited” case assumes 768 GB/s bandwidth, the theoretical peak throughput of the A6000.
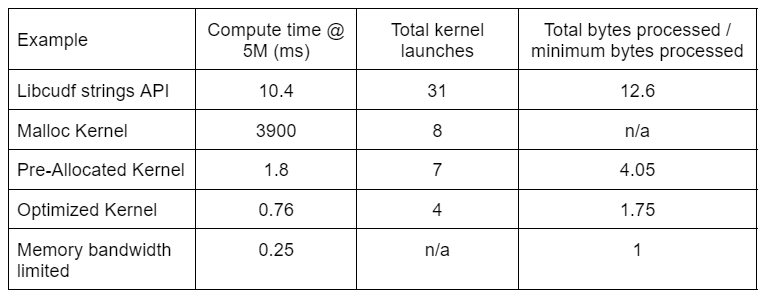
“Optimized Kernel” provides the highest throughput due to the reduced number of kernel launches and the fewer total bytes processed. With efficient custom kernels, the total kernel launches drop from 31 to 4 and the total bytes processed from 12.6x to 1.75x of the input plus output size.
As a result, the custom kernel achieves >10x higher throughput than the general purpose strings API for the redact transformation.
Peak performance analysis
The pool memory resource in RAPIDS Memory Manager (RMM) is another tool you can use to increase performance. The examples above use the default “CUDA memory resource” for allocating and freeing global device memory. However, the time needed to allocate working memory adds significant latency in between steps of the string transformations. The “pool memory resource” in RMM reduces latency by allocating a large pool of memory up front, and assigning suballocations as needed during processing.
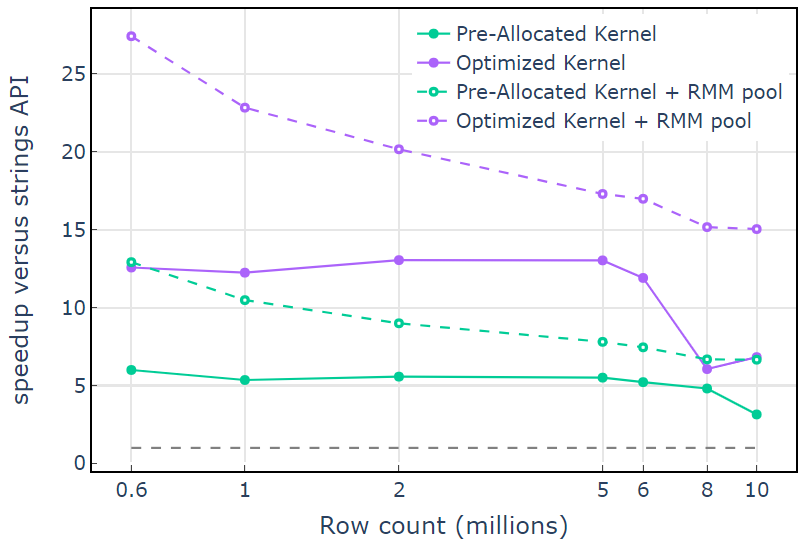
With the CUDA memory resource, “Optimized Kernel” shows a 10x-15x speedup that begins to drop off at higher row counts due to the increasing allocation size (Figure 3). Using the pool memory resource mitigates this effect and maintains 15x-25x speedups over the libcudf strings API approach.
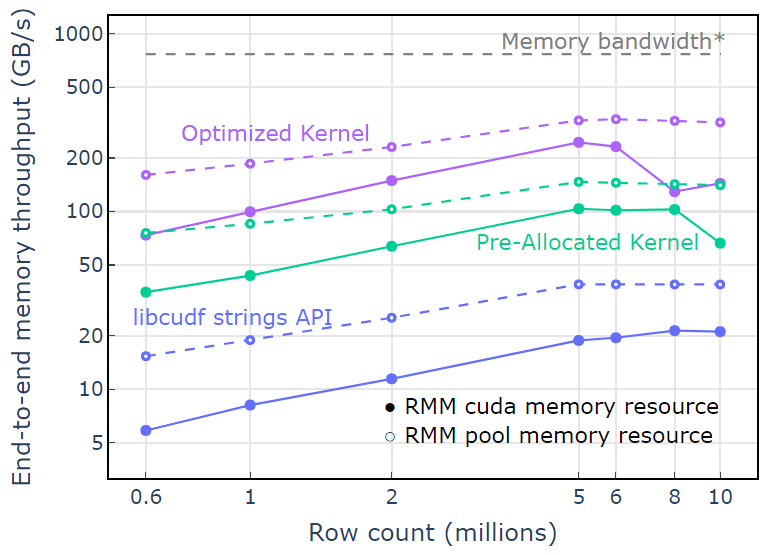
With the pool memory resource, an end-to-end memory throughput approaching the theoretical limit for a two-pass algorithm is demonstrated. “Optimized Kernel” reaches 320-340 GB/s throughput, measured using the size of inputs plus the size of outputs and the compute time (Figure 4).
The two-pass approach first measures the sizes of the output elements, allocates memory, and then sets the memory with the outputs. Given a two-pass processing algorithm, the implementation in “Optimized Kernel” performs close to the memory bandwidth limit. “End-to-end memory throughput” is defined as the input plus output size in GB divided by the compute time. *RTX A6000 memory bandwidth (768 GB/s).
Key takeaways
This post demonstrates two approaches for writing efficient string data transformations in libcudf. The libcudf general purpose API is fast and straightforward for developers, and delivers good performance. libcudf also provides device-side utilities designed for use with custom kernels, in this example unlocking >10x faster performance.
Apply your knowledge
To get started with RAPIDS cuDF, visit the rapidsai/cudf GitHub repo. If you have not yet tried cuDF and libcudf for your string processing workloads, we encourage you to test the latest release. Docker containers are provided for releases as well as nightly builds. Conda packages are also available to make testing and deployment easier. If you’re already using cuDF, we encourage you to run the new strings transformation example by visiting rapidsai/cudf/tree/HEAD/cpp/examples/strings on GitHub.
