
Apache Spark provides capabilities to program entire clusters with implicit data parallelism. With Spark 3.0 and the open source RAPIDS Accelerator for Spark, these capabilities are extended to GPUs. However, prior to this work, all CUDA operations happen in the default stream, causing implicit synchronization and not taking advantage of concurrency on the GPU. In this post, we look at how to use CUDA per-thread default stream to execute Spark tasks concurrently on the GPU and speed up Spark jobs without requiring any user change.
Task parallelism
On a high level, a Spark job is a series of transformations on immutable data. A transformation can be narrow (map) or wide (shuffle).
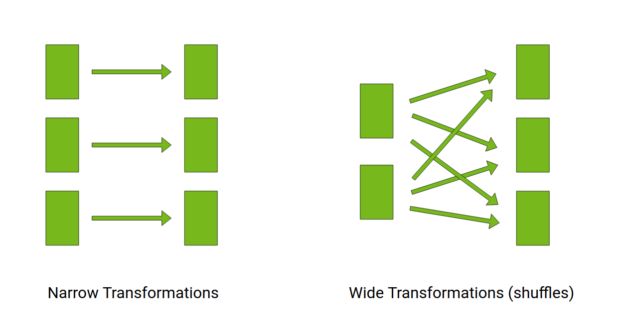
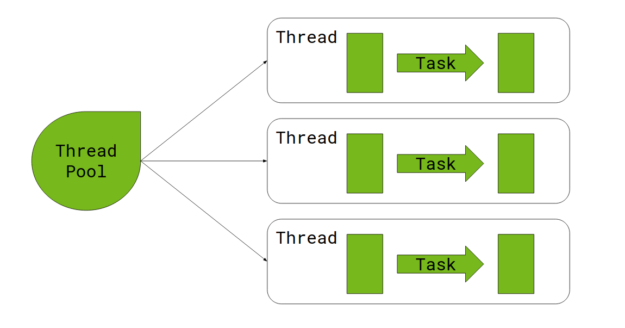
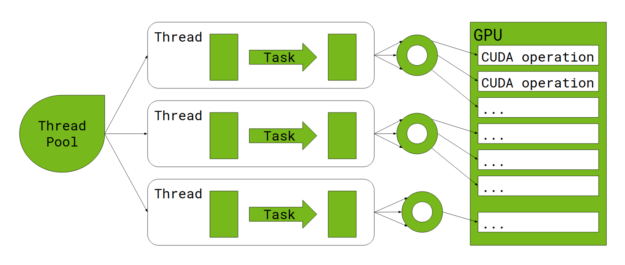
Here’s a quick look at how narrow transformations happen on the CPU. Input data is divided into partitions, with each partition transformed using a task. A task is executed by a thread, obtained from a thread pool.
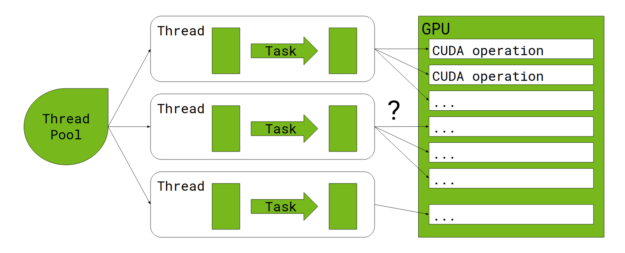
When the RAPIDS Accelerator for Apache Spark is enabled, each task offloads much of the work to the GPU. The question is, how does a multi-threaded Spark executor interact with the GPU?
CUDA streams and concurrency
In the context of the GPU, concurrency refers to the ability to perform multiple CUDA operations simultaneously. These include running CUDA kernels, calling cudaMemcpyAsync for HostToDevice or DeviceToHost data copies, and operations on the CPU. Modern GPU architectures support running multiple kernels and performing multiple data copies at the same time.
A CUDA stream is a sequence of operations that execute in issue-order on the GPU. CUDA operations in different streams may run concurrently, and CUDA operations from different streams may be interleaved. If no stream is specified, or if the stream parameter is set to 0, a single default stream (also known as a legacy default stream) is used for all host threads, essentially causing all CUDA operations to be serialized on the GPU.
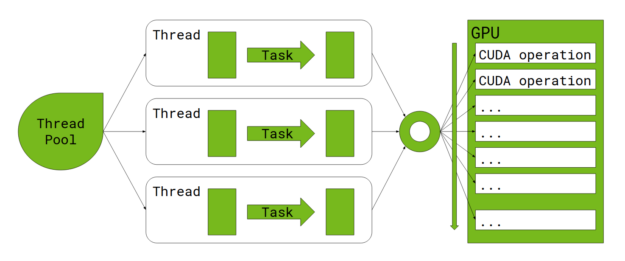
When profiling Spark jobs running in this mode, all the CUDA kernels are lined up like train cars.
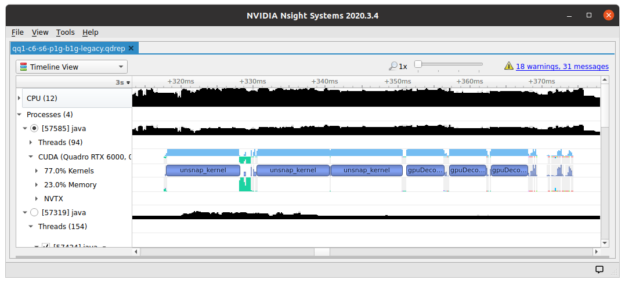
One option to increase GPU concurrency is to let each task use its own non-default stream, preferably obtained from a stream pool. The drawback of this approach is that streams need to be explicitly managed, and passed to all library functions, which might be infeasible if a library doesn’t accept stream parameters.
Per-thread default stream
CUDA has an option to specify per-thread default stream, which can be enabled by passing --default-stream per-thread or -DCUDA_API_PER_THREAD_DEFAULT_STREAM to nvcc. This gives each host thread its own default stream, and CUDA operations issued to the default stream by different host threads can run concurrently. The only drawback is that the nvcc command line flag must be applied to all compilation units, including dependent libraries. We implemented this solution and made necessary changes to Thrust, RAPIDS Memory Manager (RMM), and cuDF’s C++ library and Java JNI wrapper.
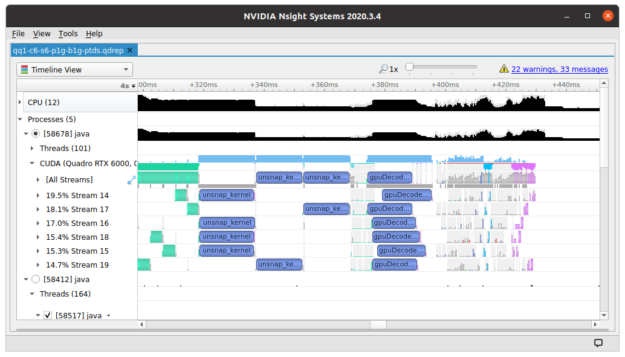
In this mode, profiling a Spark job shows multiple CUDA kernels running simultaneously.
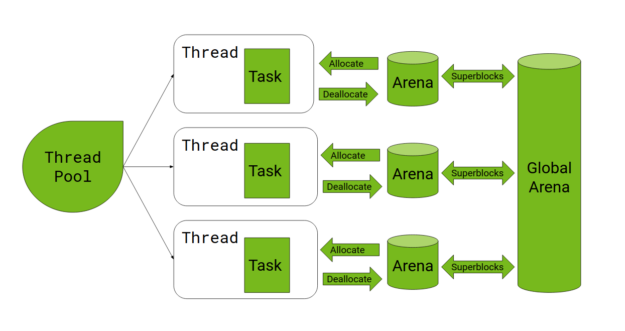
Arena allocator
One tricky issue with per-thread default stream is memory allocation. Because Spark jobs tend to allocate large memory buffers on the GPU, and the native CUDA malloc/free calls are expensive for this usage, RAPIDS Accelerator for Spark relies on RMM to provide a memory pool. When a Spark job starts running, most of the GPU memory is allocated to a shared pool, then carved off to individual allocation calls. When a buffer is deallocated, it is coalesced with neighboring free buffers, if possible.
The default RMM pool implementation divides the pool up for each stream and relies on CUDA events to synchronize between streams. When a stream runs out of memory, it “borrows” buffers from other streams. If that fails, a last-ditch effort is made to merge free buffers across streams. However, this approach results in high memory fragmentation, causing jobs to fail when there is memory pressure.
Capturing the memory allocations from a real Spark job (TPCH Query 4) shows that buffer sizes skew heavily towards the small end, with a long tail of large buffer sizes.
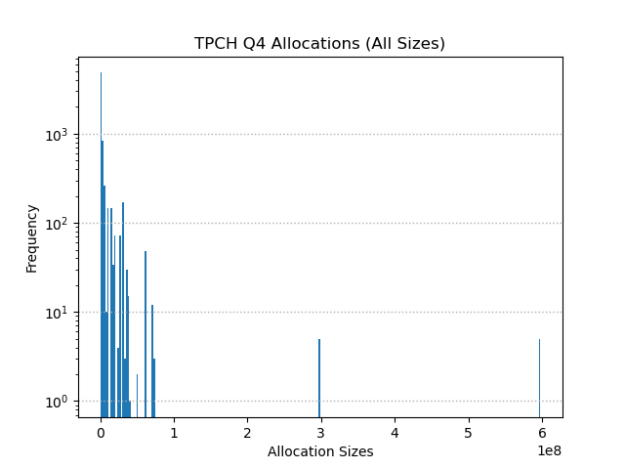
The top 10 sizes in terms of frequency shows this pattern more clearly:
| Buffer size (bytes) | # allocations |
| 256 | 1,871 |
| 505,344 | 420 |
| 2,874,368 | 290 |
| 768 | 196 |
| 2,816 | 181 |
| 4,042,496 | 160 |
| 564,992 | 144 |
| 1536 | 121 |
| 1792 | 113 |
| 319,488 | 108 |
Based on this insight, we implemented an arena-based allocator. Each CUDA stream has its own arena, a standalone memory pool. There is a global arena that initially holds all the GPU memory. When an arena needs more memory, it allocates a superblock with a minimum size (this is currently set to 256 KiB) from the global arena. Allocation requests smaller than the superblock threshold are handled by the per-stream arena. When a superblock becomes completely free, it is returned to the global arena.
This algorithm reduces memory fragmentation as a single global pool is maintained for large buffers. At the same time, it speeds up allocation and lowers contention because the more frequent small allocations are handled locally within each stream.
Benchmarks
To show the benefits of higher concurrency with per-thread default stream, we ran the TPC-DS benchmark scale factor 100 (100GB) on a single GCP instance with 24 CPU cores, 156 GB memory, and 2 V-100 GPUs, out of which only 12 cores and 1 GPU were used for running Spark. To ameliorate the effects of disk I/O, the command vmtouch -t -m 20G ${DATA_DIR} was run before each job, and SPARK_LOCAL_DIRS set to /dev/shm/tmp. The following charts show the ratio of query time between legacy default stream and per-thread default stream.
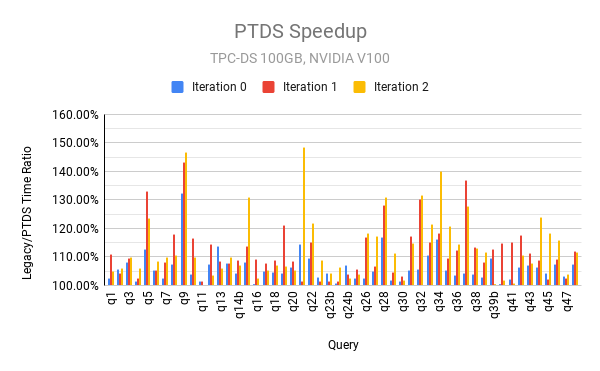
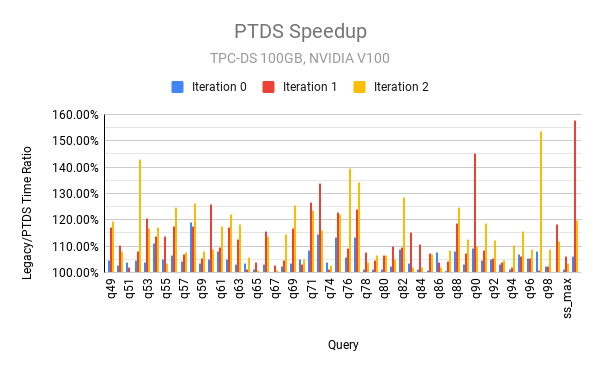
As can be seen from these charts, per-thread default stream is faster than legacy default stream across the board for all queries and performs significantly better for many queries.
When scaling up to multiple GPUs and nodes, the total query time tends to be overwhelmed by I/O (disk, network, and GPU memory copies), and the effect of per-thread default stream becomes less pronounced. As we continue to work on improving Spark shuffle performance and other aspects of I/O efficiency, we hope that GPU concurrency plays a bigger role in reducing user latency.
For more information about RMM, see Fast, Flexible Allocation for NVIDIA CUDA with RAPIDS Memory Manager.
