In efficient parallel algorithms, threads cooperate and share data to perform collective computations. To share data, the threads must synchronize. The granularity of sharing varies from algorithm to algorithm, so thread synchronization should be flexible. Making synchronization an explicit part of the program ensures safety, maintainability, and modularity. CUDA 9 introduces Cooperative Groups, which aims to satisfy these needs by extending the CUDA programming model to allow kernels to dynamically organize groups of threads.
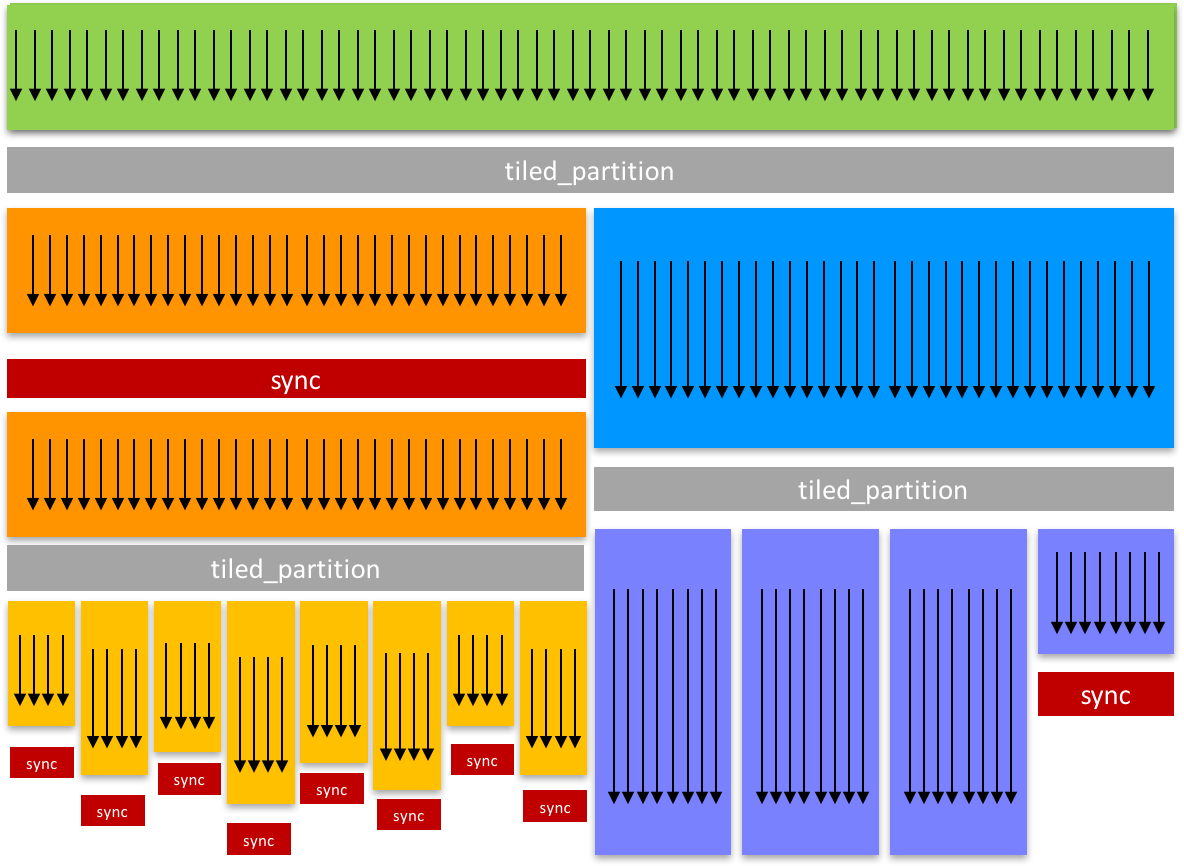
Historically, the CUDA programming model has provided a single, simple construct for synchronizing cooperating threads: a barrier across all threads of a thread block, as implemented with the __syncthreads() function. However, CUDA programmers often need to define and synchronize groups of threads smaller than thread blocks in order to enable greater performance, design flexibility, and software reuse in the form of “collective” group-wide function interfaces.
The Cooperative Groups programming model describes synchronization patterns both within and across CUDA thread blocks. It provides CUDA device code APIs for defining, partitioning, and synchronizing groups of threads. It also provides host-side APIs to launch grids whose threads are all guaranteed to be executing concurrently to enable synchronization across thread blocks. These primitives enable new patterns of cooperative parallelism within CUDA, including producer-consumer parallelism and global synchronization across the entire thread grid or even multiple GPUs.
Read more >
AI-Generated Summary
- CUDA 9 introduces Cooperative Groups, a feature that allows kernels to dynamically organize groups of threads to satisfy the need for flexible thread synchronization in efficient parallel algorithms.
- The Cooperative Groups programming model provides CUDA device code APIs for defining, partitioning, and synchronizing groups of threads, enabling synchronization patterns both within and across CUDA thread blocks.
- Cooperative Groups enables new patterns of cooperative parallelism within CUDA, including producer-consumer parallelism and global synchronization across the entire thread grid or even multiple GPUs.
AI-generated content may summarize information incompletely. Verify important information. Learn more