Researchers from NVIDIA, together with collaborators from academia, developed a new deep learning-based architecture for landmark localization, which is the process of finding the precise location of specific parts of an image. Additionally they proposed a novel training procedure based on semi-supervised learning that allows exploring images without ground-truth landmarks to improve accuracy of the model. The researchers are presenting their work at the annual Computer Vision and Pattern Recognition Conference in Salt Lake City, Utah this week.
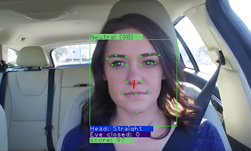
Landmark localization is a necessary task for accurate and reliable gesture recognition, facial expression recognition, facial identity verification, eye gaze tracking, and more. Unfortunately, labeling images is a manually intensive task and as a result, few landmark datasets with image to landmarks pairs exist that are large enough to train reliable deep neural networks, the researchers said.
“Our contributions are twofold; We first proposed an unsupervised technique that leverages equivariant landmark transformation without requiring labeled landmarks. In addition, we developed an architecture to improve landmark estimation using auxiliary attributes.” the researchers stated in their paper. “A key aspect of our approach is that errors can be back propagated through a complete landmark localization model.” Moreover, any existing deep-learning based architecture can benefit from findings published in the paper as the proposed methods not architecture specific.
“We show that these techniques, improve landmark prediction considerably and can learn effective detectors even when only a small fraction of the dataset has landmark labels.” The team was able to achieve state of the art performance on facial landmarks localization using 20x less labeled data.
Using NVIDIA Tesla V100 GPUs and the cuDNN-accelerated Theano deep learning framework the team trained their convolutional neural network on multiple datasets for various applications including facial landmarks and hand pose estimation. Additionally they studied few controlled experiments on synthetic data to study the contributions.

In comparison to two other leading architectures, the neural network learned with semi-supervised learning is 136 times and 6.5 times faster. The system also achieves state-of-the-art performance on public benchmark datasets.
The researchers, Sina Honari, Pavlo Molchanov, Stephen Tyree, Pascal Vincent, Christopher Pal, and Jan Kautz, will be at CVPR on Tuesday, June 19 from 12:30 – 2:50 PM, in Hall C-E, at the Salt Palace Convention Center.
Read more >
Improving Landmark Localization with a New Deep Learning Architecture
Jun 19, 2018
Discuss (0)
AI-Generated Summary
- Researchers from NVIDIA and academia have developed a new deep learning-based architecture for landmark localization, which is the process of finding specific parts of an image.
- The team proposed a semi-supervised learning technique that allows the model to use images without labeled landmarks to improve its accuracy, achieving state-of-the-art performance on facial landmarks localization using 20 times less labeled data.
- The new architecture and training procedure are not specific to a particular model and can be applied to various applications, including facial landmarks and hand pose estimation, with significant improvements in speed and accuracy.
AI-generated content may summarize information incompletely. Verify important information. Learn more