
One of the main challenges and goals when creating an AI application is producing a robust model that is performant with high accuracy. Building such a deep learning model is time consuming. It can take weeks or months of retraining, fine-tuning, and optimizing until the model satisfies the necessary requirements. For many developers, building a deep learning AI pipeline from scratch is not a viable option, which is why we built the NVIDIA NGC catalog.
The NGC catalog is the NVIDIA GPU-optimized hub of AI and HPC containers, pretrained models, SDKs, and Helm charts. It is designed to simplify and accelerate end-to-end workflows.
The NGC catalog also hosts a rich variety of task-specific, pretrained models for a variety of domains, such as healthcare, retail, and manufacturing, and across AI tasks, such as computer vision and speech and language understanding. In this post, we discuss the benefits of using pretrained models from the NGC catalog. We then show how you can use pretrained models for computer vision to build a hand gesture recognition AI application.
Why use a pretrained model?
To build an AI model from scratch, you often need access to large, high-quality datasets. In many instances, you may not have access to such datasets and may have to acquire the data yourself or use third-party resources. Even then, the data might require restructuring and preparation for training. This becomes a bottleneck for data scientists who must spend a lot of time labeling, annotating, and transforming the data instead of designing AI models.
Other typical development steps involve building a deep learning model from an open-source framework, training, refining, and retraining several times to reach the desired accuracy over several iterations. The size and complexity of deep learning models is another challenge. Over the last five years, the demand for computational resources has increased by ~30,000 times, from ResNet 50 five years ago to BERT-Megatron today. Coping with such large models requires you to have access to large-scale clusters to take advantage of scalability offered by multi-node systems.
A pretrained model, as the name suggests, is a model that has been previously trained on a particular representative dataset. It contains the weights and biases fine-tuned for this representation. To accelerate development, you can initialize your own models with pretrained ones. This typically helps you save time and allows you to run more iterations to refine the model. The technique is transfer learning.
Pretrained models for various use cases and domains
The NGC catalog hosts models specific to certain industries, such as automotive, healthcare, manufacturing, retail, and so on. The catalog also provides models for the following use cases:
- Detection: SSD PyTorch
- Classification: ResNet50 v1.5, resnext101-32x4d
- Segmentation: MaskRCNN, UNET Industrial
- Automatic speech recognition: Jasper
- Speech synthesis: FastPitch, TacoTron2, Waveglow
- Translation: GMNT, Transformer
- Language modeling: BERT, Electra
- Recommender systems: Wide and Deep, VAE
These pretrained models are developed directly by NVIDIA Research and by NVIDIA partners. You can readily integrate these pretrained models into existing industry SDKs, such as NVIDIA Clara for healthcare, NVIDIA Riva for conversational AI, NVIDIA Merlin for deep learning recommender systems, and NVIDIA DRIVE for autonomous vehicles, allowing you to get to production faster.
Model credentials
Models now include credentials that help you quickly identify the right model to deploy for your AI software development. These credentials provide a report card for the model, showing the training configurations, performance metrics, and other key parameters. The metrics show important hyperparameters like model accuracy, epoch, batch size, precision, training dataset, throughput, and other important dimensions that help you identify the usability of the models and give you the confidence to deploy them.
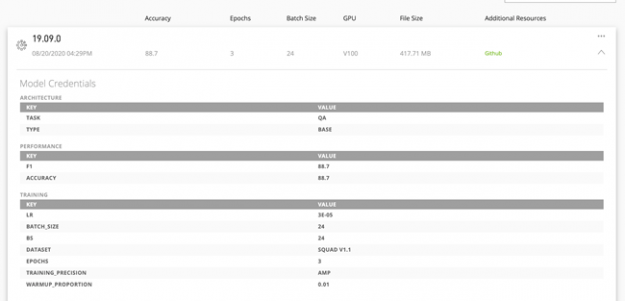
These model credentials enable you to quickly identify the right models and deploy them faster in production. The scorecard metrics are customizable so that you can use the appropriate attributes to better describe the models. For example, a computer vision model would better describe the inference performance with the images-per-second metric, while sentences-per-second is suitable for NLP models.
Transfer learning
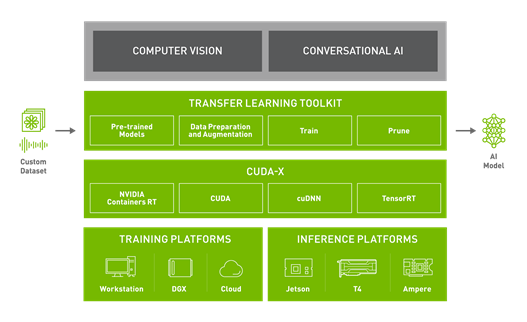
After you select the model, you might need to train with a custom dataset for a different task. NVIDIA TAO Toolkit is a Python-based AI toolkit for taking purpose-built pretrained AI models and customizing them with your own data. The toolkit adapts popular network architectures and backbones to your data, allowing you to train, fine-tune, prune, and export highly optimized and accurate AI models for edge deployment. TAO Toolkit is a standard feature for all pretrained models. Fine-tune these pretrained models with your own data. This can considerably speed up model development time by nearly 10X: from around 80 weeks to about eight weeks.
Accelerating training performance
In this section, we highlight the breakthroughs in key technologies implemented across the pretrained models: automatic mixed precision and multi-GPU training.
Automatic mixed precision
Deep neural networks can often be trained with a mixed-precision strategy, employing FP16 and FP32 precision. This results in a significant reduction in computation time and memory bandwidth requirements, while preserving model accuracy. For more information, see the Mixed Precision Training paper from NVIDIA Research. With automatic mixed precision (AMP), you can enable mixed precision with either no code changes or only minimal changes.
AMP is a standard feature across all NGC models. It automatically uses the Tensor Cores on NVIDIA Volta, NVIDIA Turing, and NVIDIA Ampere Architectures. You can get results up to 3x faster training with Tensor Cores.
Multi-GPU training
Multi-GPU training is a standard feature implemented on all NGC models. Under the hood, the Horovod and NCCL libraries are employed for distributed training and efficient communication. For most of the models, multi-GPU training on a set of homogeneous GPUs is enabled by setting the number of GPUs.
Hand gesture recognition AI application
In this example, you start with a pretrained detection model, repurpose it for hand detection using TAO Toolkit 3.0, and use it together with the purpose-built gesture recognition model. After it’s trained, you deploy this model on NVIDIA Jetson.
Setting up the environment
- Ubuntu 18.04 LTS
- python >=3.6.9 < 3.8.x
- docker-ce >= 19.03.5
- docker-API 1.40
- nvidia-container-toolkit >= 1.3.0-1
- nvidia-container-runtime >= 3.4.0-1
- nvidia-docker2 >= 2.5.0-1
- nvidia-driver >= 455.xx
You must also have an NGC account and API key. It’s free to use. When you’re registered, open the setup page for further instructions. For hardware requirements, see Requirements and Installation.
Set up your Python environment using virtualenv and virtualenvwrapper:
pip3 install virtualenv pip3 install virtualenvwrapper
Add the following lines to your shell startup file (.bashrc, .profile, and so on.) to set the location where the virtual environments should live, the location of your development project directories, and the location of the script installed with this package:
export WORKON_HOME=$HOME/.virtualenvs export PROJECT_HOME=$HOME/Devel export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3 export VIRTUALENVWRAPPER_VIRTUALENV=/home/USER_NAME/.local/bin/virtualenv source ~/.local/bin/virtualenvwrapper.sh
Create a virtual environment:
mkvirtualenv tao_gesture_demo
Activate your virtual environment:
workon tao_gesture_demo
If you forget the virtualenv name, type the following: workon.
For more information, see virtualenvwrapper 5.0.1.dev2.
Setting up TAO Toolkit 3.0
In TAO Toolkit 3.0, we have created an abstraction above the container. You launch all your training jobs from the launcher. There’s no need to manually pull the appropriate container, as tao-launcher handles that. You can install the launcher using pip with the following commands:
pip3 install nvidia-pyindex pip3 install nvidia-tao
You must install Jupyter notebook to work with this demo.
pip install notebook
Preparing the EgoHands dataset
To train the hand-detection model, we used the publicly available dataset EgoHands, provided by IU Computer Vision Lab, Indiana University. EgoHands contains 48 different videos of egocentric interactions with pixel-level, ground-truth annotations for 4,800 frames and more than 15,000 hands. To use it with TAO Toolkit, the dataset must be converted into KITTI format. For this example, we adapted the open-source script by JK Jung.
Apply a small change to the original script to make it compatible with TAO Toolkit. In the line function box_to_line(box), remove the score component by replacing the return statement with the following:
return ' '.join(['hand',
'0',
'0',
'0',
'{} {} {} {}'.format(*box),
'0 0 0',
'0 0 0',
'0'])
To convert the dataset, download the prepare_egohands.py file, apply the above-mentioned modification, set the correct paths, and follow the instructions in egohands_dataset/kitti_conversion.ipynb in this project. In addition to calling the original conversion script, this notebook converts your dataset into training and testing sets, as required by TAO Toolkit.
Training the detection model
As part of TAO Toolkit 3.0, we provide a set of Jupyter notebooks demonstrating training workflows for various models. The notebook for this demo can be found in the training_tao directory in the gesture_recognition_tao_deepstream GitHub repository.
After activating the virtual environment, navigate to the directory, start the notebook, and follow the instructions in the training_tao/handdetect_training.ipynb notebook in your browser.
cd training_tao jupyter notebook
Running TAO Toolkit training on DetectNet V2 initialized with PeopleNet
Start with fine-tuning the pretrained PeopleNet model from the NGC catalog. PeopleNet model is a DetectNet V2 model trained to recognize objects of three classes: persons, bags, and faces. After the training, these categories are overwritten by a single category: hands. We chose to initialize our model with PeopleNet, as hands are elements found in humans and the network should already have learned some representation of this category.
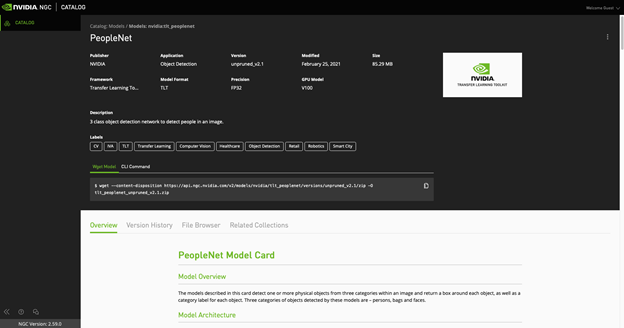
DetectNet V2 now supports restart from checkpoints. If the training job is killed prematurely, you may resume training from the closest checkpoint by re-running the same command. Make sure to use the checkpoint when restarting the training.
After training, the model should be evaluated to see if you were able to achieve the desired performance in terms of accuracy. For that, TAO Toolkit provides an evaluation tool, which can be executed in the notebook by running the following command:
!tao detectnet_v2 evaluate -e $SPECS_DIR/egohands_train_resnet34_kitti.txt\ -m $USER_EXPERIMENT_DIR/experiment_dir_unpruned_peoplenet/weights/resnet34_detector.tao \ -k $KEY
The parameters are as follows:
- The configuration file (the same one used for training)
- The trained model file
- The unique key used for training
Pruning the model
After you have fine-tuned the model, prune it so that you can build a model smaller in size for inference. Pruning is a process where you remove unnecessary connections in a neural network so that the corresponding computation does not need to be executed, freeing up memory and accelerating the model.
However, pruning brings about a loss in accuracy of the model. Usually, you just adjust a threshold for accuracy and model size trade-off. A higher threshold value gives you a smaller model but with lower accuracy. The threshold to use is dependent on the dataset. Pick some value as a starting point. If the retrain accuracy is good, you can increase this value to get a smaller model size. Otherwise, lower this value to get better accuracy. For some internal studies, we noticed that a threshold value of 0.01 is a good starting point for DetectNet V2 models.
# Create an output directory if it doesn't exist. !mkdir -p $LOCAL_EXPERIMENT_DIR/experiment_dir_pruned !tao detectnet_v2 prune \ -m $USER_EXPERIMENT_DIR/experiment_dir_unpruned_peoplenet/weights/resnet34_detector.tao \ -o $USER_EXPERIMENT_DIR/experiment_dir_pruned/resnet34_nopool_bn_detectnet_v2_pruned.tao \ -eq union \ -pth 0.0000052 \ -k $KEY
The model must be retrained to bring back accuracy after pruning. You should create a retraining specification with pretrained weights as a pruned model.
To load the pruned model graph, for retraining, set the load_graph option to true in the model_config and load the pruned model graph. If, after retraining, the model shows some decrease in mAP, it could be that the originally trained model was pruned too much. You can reduce the pruning threshold and reduce the pruning ratio and then use the new model to retrain.
DetectNet V2 now supports quantization aware training (QAT) to optimize the model even more. This step is usually performed during retraining after pruning.
Retraining after pruning with QAT
All DetectNet models, unpruned and pruned, can be converted to QAT models by setting the enable_qat parameter in the training_config component of the spec file to true.
!tao detectnet_v2 train -e $SPECS_DIR/egohands_retrain_resnet34_kitti_qat.txt \ -r $USER_EXPERIMENT_DIR/experiment_dir_retrain_qat \ -k $KEY \ -n resnet34_detector_pruned_qat \ --gpus $NUM_GPUS
Evaluating the QAT-converted model
This section evaluates a QAT-enabled, pruned, retrained model. The mAP of this model should be comparable to that of the pruned retrained model without QAT. However, due to quantization, it is possible sometimes to see a drop in the mAP value for certain datasets. To evaluate the new model, execute the following command in the notebook:
!tao detectnet_v2 evaluate -e $SPECS_DIR/egohands_retrain_resnet34_kitti_qat.txt \ -m $USER_EXPERIMENT_DIR/experiment_dir_retrain_qat/weights/resnet34_detector_pruned_qat.tao \ -k $KEY \ -f tao
Acquiring the gesture recognition model from the NGC catalog
For this application, use the trained hand-detection model cascaded with GestureNet, a gesture recognition model from the NGC. You can download the GestureNet model from the NGC catalog using the wget method:
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/tao_gesturenet/versions/deployable_v1.0/zip -O tao_gesturenet_deployable_v1.0.zip
Or you can use the CLI command:
ngc registry model download-version "nvidia/tao_gesturenet:deployable_v1.0"
As you are not retraining this model and using it directly for deployment, select the deployable_v1.0 version.
Deploying on NVIDIA Jetson with the DeepStream SDK
Now that you have fine-tuned a detection network and downloaded a gesture recognition model, deploy these models on Jetson, the target edge device. In this section, we show you how to deploy a model using the DeepStream SDK, a multi-platform scalable framework for video analytics applications
Prerequisites
These prerequisites are specific for Jetson deployment. To repurpose this solution to run on a discrete GPU, see DeepStream Getting Started.
- CUDA 10.2
- cuDNN 8.0.0
- TensorRT 7.1.0
- JetPack >= 4.4
If you don’t have the DeepStream SDK installed with your JetPack version, follow the Jetson setup instructions from the DeepStream Quick Start Guide.
Preparing the models for deployment
There are two ways of deploying a model with DeepStream SDK. The first relies on a TensorRT runtime and requires a model to be converted into a TensorRT engine. The second relies on Triton Inference Server. Triton Server is a server that can be used as a standalone solution, but it can also be used integrated into the DeepStream app. Such a setup allows high flexibility because it can accept models in various formats that do not necessarily have to be converted into TensorRT format. In this post, we show both types by deploying the hand detector using the TensorRT runtime and gesture recognition model using Triton Server.
To deploy a model to DeepStream using the TensorRT runtime, make sure that the model is convertible into TensorRT. All layers and operations in the model should be supported by TensorRT. For more information about supported layers and operations, see the TensorRT support matrix.
Converting the models to TensorRT
To take advantage of the hardware and software accelerations on the target edge device, you must convert the .etao models into NVIDIA TensorRT engines. TensorRT is an SDK for high-performance, deep learning inference. It includes a deep learning inference optimizer and runtime that delivers low latency and high throughput for deep learning inference applications.
There are two ways to convert your model into a TensorRT engine. You can do it either directly using DeepStream, or by using the tao-converter utility. We show you both ways.
The trained detector model is converted automatically by DeepStream during the first run. For the following runs, you can specify the path to the produced engine in the corresponding DeepStream config. We are providing our DeepStream configs with this project.
Because the GestureNet model is quite new, the 5.0 version of DeepStream used for this demo does not support its conversion. However, you can convert it using the updated tao-converter. To download it, choose your JetPack version:
For more information about using tao-converter with different hardware and software, see TAO Toolkit Get Started.
When you have the tao-converter installed on Jetson, convert the GestureNet model using the following command:
./tao-converter -k nvidia_tao \
-t fp16 \
-p input_1,1x3x160x160,1x3x160x160,2x3x160x160 \
-e /EXPORT/PATH/model.plan \
/PATH/TO/YOUR/GESTURENET/model.etao
Because you didn’t change the model and are using it as-is, the model key remains the same (nvidia_tao) as specified on NGC.
You are converting the model into FP16 format, as there isn’t any INT8 calibration file for the deployable model. Make sure to provide correct values for your model path as well as for the export path.
Configuring GestureNet for Triton Inference Server
To deploy your model using Triton Inference Server, prepare a model repository in a specified format. It should have the following structure:
└── trtis_model_repo
└── hcgesture_tao
├── 1
│ └── model.plan
└── config.pbtxt
In this structure, model.plan is the .plan file generated with the trt-converter, and config.pbtxt has the following content:
name: "hcgesture_tao"
platform: "tensorrt_plan"
max_batch_size: 1
input [
{
name: "input_1"
data_type: TYPE_FP32
dims: [ 3, 160, 160 ]
}
]
output [
{
name: "activation_18"
data_type: TYPE_FP32
dims: [ 6 ]
}
]
dynamic_batching { }
For more information about configuring the Triton Server repository, see Model Repository.
Customizing deepstream-app
You can configure the sample deepstream-app in a flexible way: as a primary detector, a classifier, or even cascading several models such as a detector and a classifier. In such a case, the detector passes cropped objects of interest to the classifier. This process happens in a DeepStream pipeline where each component takes advantage of the hardware components in Jetson devices.
Figure 5 shows the pipeline for the application.
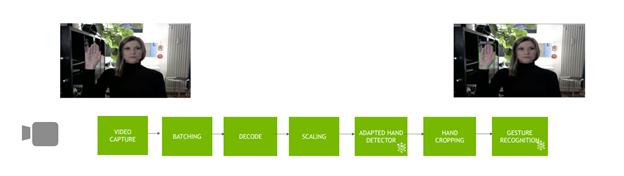
The GestureNet model you are using in this post was trained on images with a big margin around the region of interest (ROI). At the same time, the trained detector model produces narrow boxes around objects of interest (the hand, in this case). At first, this leads to the fact that the objects passed to the classifier are different from the representation learned by the classifier. There were two ways to solve this problem:
- Retrain it with a new dataset reflecting the setup.
- Extend the cropped ROIs by some suitable margin.
As we wanted to use the GestureNet model as-is, we chose the second path, which required modification of the original app.
To modify the metadata returned by the detector to crop bigger bounding boxes, implement the following function:
#define CLIP(a,min,max) (MAX(MIN(a, max), min))
int MARGIN = 200;
static void
modify_meta (GstBuffer * buf, AppCtx * appCtx)
{
int frame_width;
int frame_height;
get_frame_width_and_height(&frame_width, &frame_height, buf);
NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta (buf);
NvDsFrameMetaList *frame_meta_list = batch_meta->frame_meta_list;
NvDsObjectMeta *object_meta;
NvDsFrameMeta *frame_meta;
NvDsObjectMetaList *obj_meta_list;
while (frame_meta_list != NULL) {
frame_meta = (NvDsFrameMeta *) frame_meta_list->data;
obj_meta_list = frame_meta->obj_meta_list;
while (obj_meta_list != NULL) {
object_meta = (NvDsObjectMeta *) obj_meta_list->data;
object_meta->rect_params.left = CLIP(object_meta->rect_params.left - MARGIN, 0, frame_width - 1);
object_meta->rect_params.top = CLIP(object_meta->rect_params.top - MARGIN, 0, frame_height - 1);
object_meta->rect_params.width = CLIP(object_meta->rect_params.left + object_meta->rect_params.width + MARGIN, 0, frame_width - 1);
object_meta->rect_params.height = CLIP(object_meta->rect_params.top + object_meta->rect_params.height + MARGIN, 0, frame_height - 1);
obj_meta_list = obj_meta_list->next;
}
frame_meta_list = frame_meta_list->next;
}
}
To display the original bounding boxes, implement the following function, which restores the meta bounding boxes to their original size:
static void
restore_meta (GstBuffer * buf, AppCtx * appCtx)
{
int frame_width;
int frame_height;
get_frame_width_and_height(&frame_width, &frame_height, buf);
NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta (buf);
NvDsFrameMetaList *frame_meta_list = batch_meta->frame_meta_list;
NvDsObjectMeta *object_meta;
NvDsFrameMeta *frame_meta;
NvDsObjectMetaList *obj_meta_list;
while (frame_meta_list != NULL) {
frame_meta = (NvDsFrameMeta *) frame_meta_list->data;
obj_meta_list = frame_meta->obj_meta_list;
while (obj_meta_list != NULL) {
object_meta = (NvDsObjectMeta *) obj_meta_list->data;
// reduce the bounding boxes for output (copy the reserve value from detector_bbox_info)
object_meta->rect_params.left = object_meta->detector_bbox_info.org_bbox_coords.left;
object_meta->rect_params.top = object_meta->detector_bbox_info.org_bbox_coords.top;
object_meta->rect_params.width = object_meta->detector_bbox_info.org_bbox_coords.width;
object_meta->rect_params.height = object_meta->detector_bbox_info.org_bbox_coords.height;
obj_meta_list = obj_meta_list->next;
}
frame_meta_list = frame_meta_list->next;
}
Also, implement this helper function to get frame width and height from the buffer.
static void
get_frame_width_and_height (int * frame_width, int * frame_height, GstBuffer * buf) {
GstMapInfo map_info;
memset(&map_info, 0, sizeof(map_info));
if (!gst_buffer_map (buf, &map_info, GST_MAP_READ)){
g_print("Error: Failed to map GST buffer");
} else {
NvBufSurface *surface = NULL;
surface = (NvBufSurface *) map_info.data;
*frame_width = surface->surfaceList[0].width;
*frame_height = surface->surfaceList[0].height;
gst_buffer_unmap(buf, &map_info);
}
}
Building the application
To build the custom app, copy deployment_deepstream/deepstream-app-bbox to /opt/nvidia/deepstream/deepstream-5.0/sources/apps/sample_apps.
Install the required dependencies:
sudo apt-get install libgstreamer-plugins-base1.0-dev libgstreamer1.0-dev \ libgstrtspserver-1.0-dev libx11-dev libjson-glib-dev
Build an executable:
cd /opt/nvidia/deepstream/deepstream-5.0/sources/apps/sample_apps/deepstream-app-bbox make
Configuring the DeepStream pipeline
Before executing the app, you must provide configuration files. For more information about configuration parameters, see Application Architecture. You can find the configuration files of this demo under deployment_deepstream/egohands-deepstream-app-trtis/. In the same directory, you can also find the label files required by the models.
Finally, you must make your models discoverable by the app. According to the configs, the directory structure under deployment_deepstream/egohands-deepstream-app-trtis/ for model storage looks like the following:
├── tao_models
│ ├── tao_egohands_qat
│ │ ├── calibration_qat.bin
│ │ └── resnet34_detector_qat.etao
└── trtis_model_repo
└── hcgesture_tao
├── 1
│ └── model.plan
└── config.pbtxt
You may notice that the file resnet34_detector_qat.etao_b16_gpu0_int8.engine specified in the config config_infer_primary_peoplenet_qat.txt is missing in the current setup. It is generated upon the first execution and used directly in the following runs.
Executing the app
In general, the execution command looks like the following:
./deepstream-app-bbox -c <config-file>
In this case, with the configs provided, it looks like the following:
./deepstream-app-bbox -c source1_primary_detector_qat.txt
The app should be running now.
Summary
In this post, we demonstrated how you can use a pretrained model from the NGC catalog to fine-tune, optimize, and deploy a gesture recognition application using the DeepStream SDK.
In addition to PeopleNet and GestureNet models used for this example, you can also find models in the NGC catalog for other use cases, such as conversational AI, speech, and language understanding. For more information, see the following resources:
