

Deep learning is enabling a revolution in how we interact with technology in our daily lives, from personalized healthcare to how we drive our cars. NVIDIA AI Co-Pilot combines deep learning and visual computing to enable augmented driving. Co-Pilot uses sensor data from a microphone inside the car, and cameras both inside and outside the car, to track the environment around the driver. Co-Pilot understands where you are looking while driving to determine objects you might not see—like what’s coming up along side you, ahead of you and in your blind spot. This lets the car understand the driver as well as its environment and provides suggestions, warnings and, where needed, interventions for safer and more enjoyable experience. A key component of AI Co-Pilot is the technology for continuous real-time monitoring of the driver’s posture and gaze, as Figure 1 shows.
Estimating facial features such as head pose and facial landmarks from images is key for many applications, including activity recognition, human-computer interaction, and facial motion capture. While most prior work has focused on facial feature estimation from a single image, videos provide temporal links among nearby image frames, which is essential for accurate and robust estimation. A key challenge for video-based facial analysis is to properly exploit temporal coherence.
In this post, we describe how we use recurrent neural networks (RNNs) for joint estimation and tracking of facial features in videos. As a generic and learning-based approach for time series prediction, RNNs avoid tracker engineering for tasks performed on videos, much like CNNs (Convolutional Neural Networks) avoid feature engineering for tasks performed on still images.
We recently incorporated RNN-based facial analysis into the NVIDIA AI Co-Pilot platform to improve the overall driving experience, and published this work [1] in IEEE CVPR 2017.
The following video from NVIDIA CEO Jen-Hsung Huang’s CES 2017 keynote provides examples of AI Co-Pilot in action.
Bayesian Filtering vs. RNNs for Dynamic Facial Analysis
The traditional approach for analyzing facial features in videos is Bayesian Filtering. Examples include Kalman Filters and Particle Filters. These methods, however, generally requires complicated, problem-specific design and tuning. For example, tracking can be performed at different levels for different tasks [2]. To deal with drifting, many tracking methods require a failure detection and reinitialization method as a backup [3]. For complex tasks (for example, non-rigid face, hand, or body tracking), implementing a Bayesian filter is quite challenging [4]. In short, the need for such tracker engineering makes these methods cumbersome and less generic for dynamic facial analysis from videos.
In order to avoid tracker engineering, we use RNNs to directly learn the trackers from a large amount of training data. As Figure 2 shows, we found that the computation performed by a RNN resembles Bayesian filtering—both methods estimate the hidden states from the measurements and propagate the hidden states over time. The major difference is that Bayesian filtering requires the state transition model and the measurement model to be known beforehand with a problem-specific design, while RNNs learn these two models directly from training data. Please refer to our paper for a more detailed comparison.
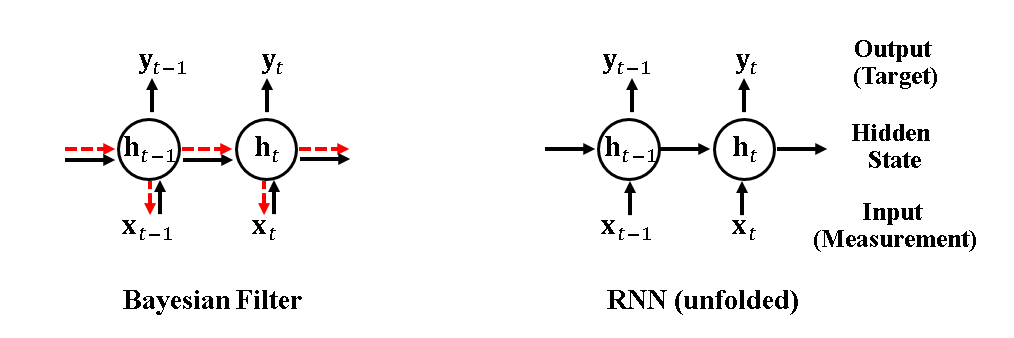
A Toy Example: Tracking a 1D Cursor
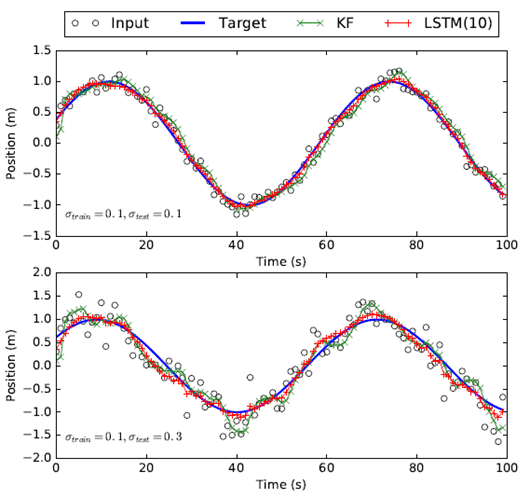
We first use an expository example to illustrate the similarity and differences between Bayesian filtering and RNNs. Figure 3 shows a classic example for Bayesian filtering, in which a cursor moves in a sinusoidal pattern in one dimension. The goal is to track the position of the cursor. The input to our system is the noisy measurement of the cursor’s position. We define the hidden state to be the cursor’s position, velocity, and acceleration. We use a linear Kalman filter (KF) to estimate the cursor position over time. Figure 3 shows that the Kalman Filter can smooth the noisy measurements over time as expected, but there is a gap to the ground truth position.
Alternatively, we trained a RNN (LSTM with 10 neurons for the hidden layer). For training, the input is the noisy measurements, the output is the true position of the cursor. We sampled the noise and created a large amount of training data. At testing, we tested the trained LSTM model at different noise levels. Figure 3 shows that RNN achieved much better results than Kalman Filter at all the noise levels.
From Bayesian Filtering to RNNs
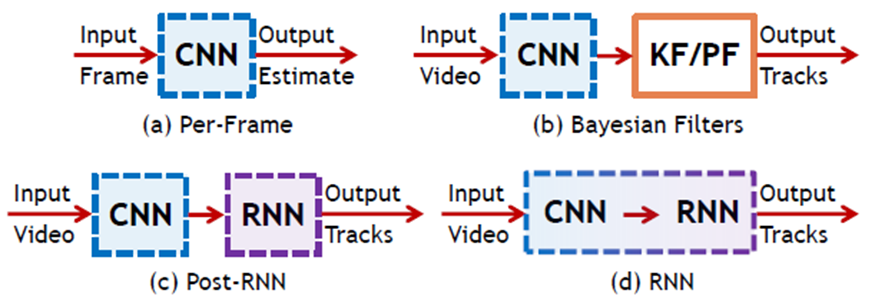
We now apply RNNs to facial analysis in videos. As Figure 4 shows, we studied four variants of the proposed method for head pose estimation and facial landmark localization in videos. Figure 4a is the baseline method, where we use a convolutional neural network (CNN) to estimate facial features for each input frame separately. In this case, the temporal connection is completely ignored. Many prior work falls in this category. The second method (Figure 4b) uses a Kalman filter (KF) or a particle filter (PF) to post-process the output of the CNN per-frame estimation. As we shall see later, Kalman filter or particle filter helps to temporally smoothen the per-frame estimation but they cannot reduce the bias in the estimation. In method three (Figure 4c), which we call post-RNN, we train the RNN separately from the CNN. The input of the RNN is the estimated facial features from the CNN, and thus the RNN has a similar role of the Kalman filter or particle filter for temporal smoothing. Finally, in method four (Figure 4d), we train the CNN and RNN jointly end-to-end from videos, where the input to the RNN is the high-dimensional feature maps estimated from the CNN. As we shall see later, this joint CNN-RNN structure is able to learn the temporal connections of facial features between consecutive frames and achieves significantly better performance than the other three methods.
We used FC-RNN as our choice of RNN and VGG16 trained on the imageNet dataset as our choice of CNN. FC-RNN was originally proposed in [5] to leverage the generalizability of a pre-trained CNN. FC-RNN transforms the fully connected layer of a pre-trained CNN into recurrent layers with the intention of preserving the structure of a pre-trained CNN as much as possible. We adopt FC-RNN in our experiments for dynamic facial analysis because of its simple structural design and superior or on-par performance to other more complex variants of recurrent networks. We apply a set of regularization techniques to train the FC-RNN, such as variational dropout [6] and soft gradient clipping.
Large Synthetic Datasets are Essential
Big data is critical for the success of any deep learning related study. The requirement of big data is especially prominent for head pose and landmark estimation from videos, because (1) the existing video datasets are relatively small, and (2) the ground truth labels of head pose and facial landmarks are not accurate. For example, the BIWI head pose dataset [6] has only 20 subjects and 24 videos in total, and the 300VW facial landmark dataset [7] has only 114 videos, with semi-automatically generated labels as ground truth.
These problems motivated us to create a large-scale, synthetic dataset that has sufficient coverage of head motion and accurate ground truth labels. In this vein, we created to our knowledge the first synthetic head tracking dataset, NVIDIA SynHead, that covers 10 subjects, 70 head motion tracks, 700 videos, and in total 510,960 frames. SynHead is 32 times larger than BIWI (15,678 frames) and two times larger than 300-VW (218,595 frames). We released this synthetic dataset online for research purposes.
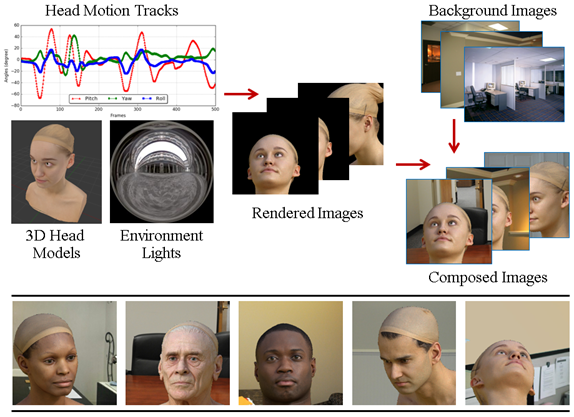
Figure 5 demonstrates the pipeline we used to create SynHead. The 10 (5 female and 5 male) 3D head models are high resolution 3D scans. To simulate realistic head motions, we gathered head motion tracks, 24 from the BIWI and 26 from the ETH dataset. Additionally, we recorded 20 depth video sequences performed by 13 (11 male and 2 female) subjects with the Kinect and SoftKinetic sensors. We computed the raw head pose angles for these sequences and discarded any failure cases by manual inspection. Finally, we temporally smoothed these head motion tracks with a Gaussian filter. For each head pose, we rendered the 10 head models and composed the rendered images with a randomly selected background image per motion track. We find that adding the random background is an efficient way to augment the dataset and is helpful for good performance.
Experimental Results
We applied our methods to two dynamic facial analysis tasks: head pose estimation and facial landmark localization from videos. We implemented the CNN and RNN networks with Theano, and trained the networks on an NVIDIA Titan X GPU.
Head Pose Estimation
For head pose estimation, we evaluated our methods on real data from the BIWI dataset which contains 24 videos in all. We followed the same experimental protocol proposed in prior work. Among all the four methods that Figure 4 shows, the end-to-end RNN approach (Figure 4d) performs the best not only in terms of the average error but also the standard deviation of the estimated error, which shows that the estimation with the end-to-end RNN method is more stable over time. Compared with other prior work, our method has achieved state-of-the-art performance (with average error about 1.5 degree on BIWI), with only RGB images as input. This shows the effectiveness of the proposed method for head pose estimation with large training data obtained by image synthesis. Figure 6 shows several examples of head pose estimation on the BIWI dataset, with RNN estimation and per-frame estimation.

Facial Landmark Localization
For facial landmark localization, we experimented with the 300-VW benchmark dataset. As a pre-processing step, we trained a face detector with Faster R-CNN to perform face detection on every frame. For each video, the central positions of the detected facial regions are smoothed temporally with a Gaussian filter, and the maximum size of the detected bounding boxes is used to extract a face-centered sequence. This pre-processing step stabilizes face detections over time and interpolates face regions for the few frames with missed face detection.
We employed several types of data augmentation—horizontal mirroring of the images, playing the image sequences in reverse, and small random scaling and translation of the face windows. We used the same network architecture as for head pose estimation except that the output layer has 136 neurons corresponding to the locations of the 68 facial landmarks.
In our experiments the RNN-based methods, including Post-RNN and RNN, improve the performance of per-frame estimation. In addition, compared to a recent work HyperFace [8], which is a multi-tasking network for frame-wise facial analysis and has state-of-theart performance, our RNN-based method has better performance, demonstrating the effectiveness of joint estimation and tracking. Finally, we observe that the RNN significantly reduces the failure rate compared to other methods. Apart from reducing the noise on the observed measurements, neither the Kalman filter (KF) or the particle filter (PF) are able to reduce the observed error from the ground truth.
Figure 7 shows examples of facial landmark localization on the 300-VW dataset. Compared to per-frame estimation, the RNN is more robust to occlusions, profile head poses, and facial expressions. In particular, it is more advantageous when the head is moving fast, which shows the RNN’s ability to learn motion information implicitly.

Learn More at CVPR 2017
Compared with traditional Bayesian filtering methods, our RNN-based method learns to jointly estimate frame-wise measurements and to temporally track them with a single end-to-end network. This makes the RNN-based method a generic approach that can be extended to other tasks of dynamic facial analysis in videos.
To learn more, come see our poster and demo “Dynamic Facial Analysis: From Bayesian Filtering for Recurrent Neural Network” (Paper ID 574) on Saturday, July 22 from 3:00 pm to 5:00 pm at the CVPR conference in Honolulu (Hawaii Convention Center room Kamehameha I). You should also visit the NVIDIA booth (#105) (after 10:00 am July 22-25).
Please refer to our paper [1] for more technical details. The large synthetic NVIDIA SynHead dataset is also available for research purposes.
References
[1] J. Gu, X. Yang, S. De Mello, and J. Kautz. Dynamic Facial Analysis: From Bayesian Filtering to Recurrent Neural Networks. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[2] M. Uricar and V. Franc. Real-time facial landmark tracking by tree-based deformable part model based detector. In International Conference on Computer Vision (ICCV) Workshop, 2015.
[3] E. Murphy-Chutorian and M. Trivedi. HyHOPE: Hybrid head orientation and position estimation for vision-based driver head tracking. In IEEE Intelligent Vehicles Symposium, 2008.
[4] U. Prabhu, K. Seshadri, and M. Savvides. Automatic facial landmark tracking in video sequences using Kalman filter assisted active shape models. In European Conference on Computer Vision (ECCV) Workshop, 2012.
[5] X. Yang, P. Molchanov, and J. Kautz. Multilayer and multimodal fusion of deep neural networks for video classification. In ACM Multimedia, 2016.
[6] G. Fanelli, J. Gall, and L. Van Gool. Real time head pose estimation with random regression forests. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011.
[7] J. Shen, S. Zafeiriou, G. Chrysos, J. Kossaifi, G. Tzimiropoulos, and M. Pantic. The first facial landmark tracking in-the-wild challenge: Benchmark and results. In International Conference on Computer Vision (ICCV) Workshop, 2015.
[8] R. Ranjan, V. Patel, and R. Chellappa. Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. arXiv:1603.01249, 2016.