
New scientific breakthroughs are being made possible by the convergence of HPC and AI. It is now necessary to deploy both HPC and AI workloads on the same system.
The complexity of the software environments needed to support HPC and AI workloads is huge. Application software depends on many interdependent software packages. Just getting a successful build can be a challenge, let alone ensuring the build is optimized to take advantage of the very latest hardware and software capabilities.
Containers are a widely adopted method of taming the complexity of deploying HPC and AI software. The entire software environment, from the deep learning framework itself, down to the math and communication libraries are necessary for performance, is packaged into a single bundle. Since workloads inside a container always use the same environment, the performance is reproducible and portable.
NGC, a registry of GPU-optimized software, has been enabling scientists and researchers by providing regularly updated and validated containers of HPC and AI applications. NGC recently announced beta support for using the deep learning containers with the Singularity container runtime, starting with version 19.11. This substantially eases the adoption of AI methodologies by HPC sites using Singularity.
This blog illustrates how NGC and Singularity dramatically simplify the deployment of deep learning workloads on HPC systems.
Training ResNet-50 with TensorFlow
First used to win the 2015 ImageNet competition, ResNet is still a popular image classification model and is widely used as a deep learning training benchmark. In just a few simple steps, I’ll demonstrate how to train the ResNet-50 v1.5 model using TensorFlow with images from the ImageNet database. While training the ResNet model is almost trivial nowadays, the same approaches shown here can be used to scale-out the training of much larger models and can also be used with other deep learning frameworks.
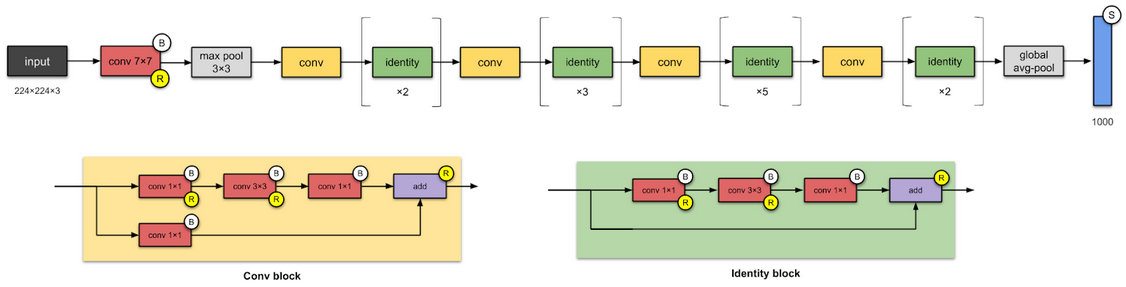
In addition to being a container registry, NGC also provides complete AI workflows, including pre-trained models and scripts. An example is the ResNet-50 v1.5 model for TensorFlow; I’ll follow the Quick Start Guide closely for this example.
The example uses Singularity version 3 and assumes you already have an interactive node allocation from the cluster resource manager.
1. Download and extract the ImageNet dataset as described in Step 2, “Download the data”, of the Quick Start Guide. Note that the overall ResNet-50 performance is sensitive to the performance of the filesystem used to store the images so your overall performance will vary. In my runs I used a local SSD.
2. The NGC TensorFlow 19.11 container image already includes the ResNet-50 model scripts, located in /workspace/nvidia-examples/resnet50v1.5, so I just used that. Alternatively, the models scripts could have been downloaded from the NGC model script page.
3. Pull the NGC TensorFlow container using Singularity. This is a single simple command that can be run as an unprivileged user. (Note: if your IT admin has set up the NGC Container Replicator, the TensorFlow container may already reside on your system.)
$ singularity pull tensorflow-19.11-tf1-py3.sif docker://nvcr.io/nvidia/tensorflow:19.11-tf1-py3
4. After the container is finished downloading, the fourth and final step is to train the model. Let’s start by using a single GPU and FP16. The corresponding Python command line on the Performance tab of the NGC model script page needs to be wrapped in the command to start the Singularity container image downloaded in the previous step.
$ singularity run --nv -B /local/imagenet:/data/imagenet tensorflow-19.11-tf1-py3.sif python /workspace/nvidia-examples/resnet50v1.5/main.py --mode=training_benchmark --use_tf_amp --warmup_steps=200 --batch_size=256 --data_dir=/data/imagenet --results_dir=/tmp/resnet
I’ve used two options with Singularity, --nv and -B. The first, –nv, enables NVIDIA GPU support in Singularity. The second, -B, bind mounts the /local/imagenet directory on the host where I extracted the ImageNet database to the location /data/imagenet inside the container. Modify this to use the location where you extracted the ImageNet database. The python command is taken from the NGC model script page for the 1 GPU / FP16 case with only minor modification to use the model script included with the NGC container.
In my runs, I achieved approximately 980 images per second using Singularity and virtually identical results for Docker, both using a single NVIDIA V100 GPU and the 19.11 TensorFlow NGC container image.
Multi-node Training with TensorFlow and Horovod
Distributed computing is an integral part of HPC. Frameworks such as Horovod enable distributed deep learning. The TensorFlow NGC container includes Horovod to enable multi-node training out-of-the-box. In this section, I’ll show how Singularity’s origin as a HPC container runtime makes it easy to perform multi-node training as well. Here I have been allocated two-cluster nodes each with 4xV100 GPUs from the cluster resource manager.
The usual approach to scaling out MPI workloads with Singularity is to use a MPI runtime outside the container to launch distributed tasks inside container instances (also known as “outside-in” or “hybrid”). This approach requires the least amount of change compared to running native MPI workloads, but does require a MPI runtime on the host compatible with the MPI library inside the container. The 19.11 NGC TensorFlow image bundles OpenMPI version 3.1.4, so any host OpenMPI version greater than 3.0 should work, but the closer the version match the better.
Launching a two-node training run that uses 4xGPUs per node with Singularity and the NGC container is straightforward. Use mpirun as you normally would and use the command to launch the Singularity container from above. In fact, the only difference relative to the single GPU command line in the previous example is starting it with mpirun.
$ mpirun singularity run --nv -B /local/imagenet:/data/imagenet tensorflow-19.11-tf1-py3.sif python /workspace/nvidia-examples/resnet50v1.5/main.py --mode=training_benchmark --use_tf_amp --warmup_steps=200 --batch_size=256 --data_dir=/data/imagenet --results_dir=/tmp/resnet
Note: in this case the MPI runtime on the host is resource manager aware, so I did not need to manually specify how many MPI ranks to start or how to place them. The MPI runtime is able to infer this information from my interactive SLURM job allocation (srun --nodes 2 --ntasks 8 --pty --time=15:00 bash -i). If your MPI runtime is not setup this way or your cluster uses a different resource manager, then you will need to manually tell the MPI runtime to use two-nodes with 4 ranks / GPUs per node, e.g., mpirun -n 8 --npernode 4 --hostfile hostfile where hostfile contains the names of the nodes you were allocated, one per line, or mpirun -n 8 -H node1:4,node2:4, replacing node1 and node2 with the names of the nodes you were allocated.
You should observe that eight training tasks have been started across two-nodes using a total of 8xGPUs (4xGPUs per node). On the particular system I used, the distributed training performance was approximately 6800 images per second, a roughly 6.9x speedup relative to a single GPU. Performance can be boosted even further by using XLA (--use_xla) and/or DALI (--use_dali), both of which are included in the NGC container image.
An alternative approach for scaling out MPI workloads with Singularity is to use the MPI runtime inside the container (also known as “inside-out” or “self-contained”). This eliminates the dependency on a compatible host MPI runtime, but requires additional configuration to manually specify the size and shape of the job as well as launching all the tasks inside containers. Both approaches, as well as their pros and cons, are described in more detail in the webinar “Scaling Out NGC Workloads with Singularity”.
The preceding examples assume an interactive session but the training can also be deployed via a job script that can be submitted to the resource manager, e.g., using SLURM’s sbatch.
#!/bin/bash #SBATCH -J resnet50 #SBATCH -t 15:00 #SBATCH -N 2 #SBATCH -n 8 # site specific module load singularity openmpi/3.1.0 # dataset staging, if necessary # ... mpirun singularity run --nv -B /local/imagenet:/data/imagenet tensorflow-19.11-tf1-py3.sif python /workspace/nvidia-examples/resnet50v1.5/main.py --mode=training_benchmark --use_tf_amp --warmup_steps=200 --batch_size=256 --data_dir=/data/imagenet --results_dir=/tmp/resnet
Quickly Deploy Your AI Workloads Today
NGC offers container images that are validated, optimized, and regularly updated with the latest versions of all the popular deep learning frameworks. With the addition of Singularity support, NGC containers can now be even more widely deployed, including HPC centers, your personal GPU-powered workstation, and on your preferred Cloud.
Download a NGC container and run it with Singularity today!