
In simple terms, conversational AI is the use of natural language to communicate with machines. Deep learning applications in conversational AI are growing every day, from voice assistants and chatbots, to question answering systems that enable customer self-service. The range of industries adapting conversational AI into their solutions are wide, and have diverse domains extending from finance to healthcare.

Conversational AI is a complex system that integrates multiple deep neural networks that must work seamlessly and in unison to deliver a delightful user experience with accurate, fast and natural human-to-machine interaction. To achieve these goals, developers are developing applications that solve key problems like accomplishing domain adaptation, user analytics, compliance, high accuracy voice recognition, user identification, sentiment analysis, among others.
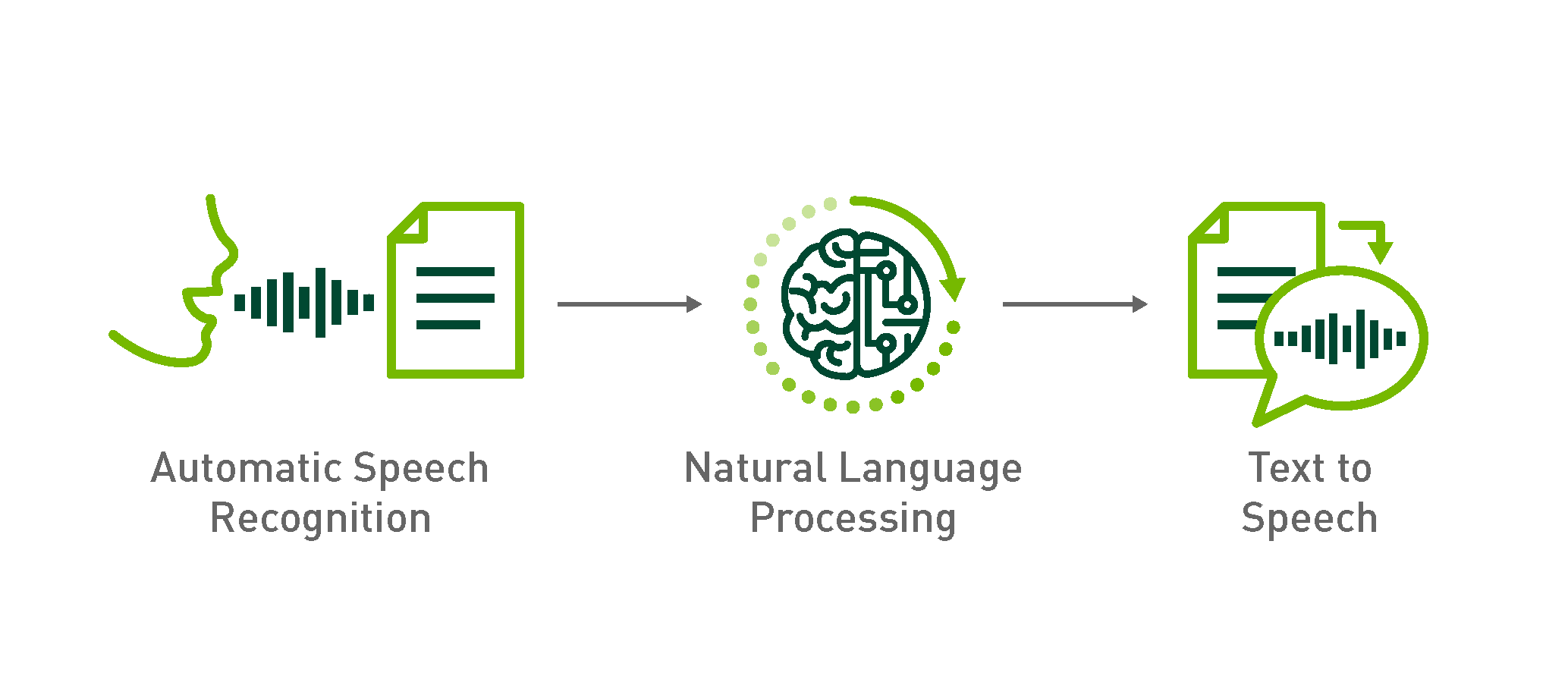
A typical conversational AI application uses three subsystems to do the steps of processing and transcribing the audio, understanding (deriving meaning) of the question asked, generating the response (text) and speaking the response back to the human. These steps are achieved by multiple deep learning solutions working together. First, automatic speech recognition (ASR) is used to process the raw audio signal and transcribing text from it. Second, natural language processing (NLP) is used to derive meaning from the transcribed text (ASR output). Last, speech synthesis or text-to-speech (TTS) is used for the artificial production of human speech from text. Optimizing this multi-step process is complicated, as each of these steps requires building and using one or more deep learning models. When developing a deep learning model to achieve the highest performance and accuracy for each of these areas, a developer will encounter several approaches and experiments that can vary by domain application.
To tackle the challenging tasks of building and optimizing for accuracy, NVIDIA released Neural Modules (NeMo) version 0.9 [1]. NeMo is a toolkit based on PyTorch created for developing AI applications for Conversational AI. Through modular Deep Neural Networks development, NeMo enables fast experimentation by connecting modules, mixing and matching components. NeMo modules typically represent data layers, encoders, decoders, language models, loss functions, or methods of combining activations [2]. NeMo makes it easy to compose complex neural network architectures and systems using reusable components for each of ASR, NLP and TTS. Additionally, in NGC you can find NeMo resources for Conversational AI such as pre-trained models, scripts for training or evaluation and NeMo end-to-end applications that allow developers to experiment with different algorithms and perform transfer learning using their own datasets.
In this blog, we describe how to build and optimize the first part of Conversational AI, i.e. automatic speech recognition. ASR is a challenging task in natural language, as it consists of a series of subtasks such as speech segmentation, acoustic modelling, and language modelling to form a prediction (of sequences of labels) from noisy, unsegmented input data [3, 4]. Luckily, the introduction of Connectionist Temporal Classification (CTC) [4] removed the need for pre-segmented data and allowed the network to be trained end-to-end directly for sequence labelling tasks like ASR. As a result, a CTC based ASR pipeline consists of the following blocks, shown below:

- Feature extraction: Audio signal preprocessing using normalization, windowing, (log) spectrogram (or mel scale spectrogram, or MFCC).
- Acoustic Model: A CTC-based network that predicts the probability distributions P_t(c) over vocabulary characters c per each time step t. For this block we use NVIDIA’s high performing acoustic models: Jasper [5] and QuartzNet [6, 7].
- Decoding:
- Greedy (argmax): Is the simplest strategy for a decoder. The letter with the highest probability (temporal softmax output layer) is chosen at each time-step, without regard to any semantic understanding of what was being communicated. Then, the repeated characters are removed or collapsed, and blank tokens are discarded.
- A language model can be used to add contex,t and therefore correct mistakes in the acoustic model. A beam search decoder weights the relative probabilities the softmax output against the likelihood of certain words appearing in context and tries to determine what was spoken by combining both what the acoustic model thinks it heard with what is a likely next word.
To facilitate the implementation and domain adaptation of the complete ASR pipeline, we created the Domain Specific – NeMo ASR Application. This application is developed using NeMo and it enables you to train or fine-tune pre-trained (acoustic and language) ASR models with your own data. Through this application, we empower you to train, evaluate and compare ASR models built on your own domain specific audio data. This gives you the ability to progressively create better performing ASR models specifically built for your data.
Through an example domain adaptation use case we show you:
- The performance impact of Acoustic Model training
- The performance impact of adding and training a Language Model
- The performance comparison of approaches using Word Error Rate (WER)
To exemplify the end-to-end domain specific NeMo ASR application, we do transfer learning or domain adaptation from old fiction books (LibriSpeech [8]) to relatively modern business news Wall Street Journal (WSJ) [9].
We start with an acoustic model pre-trained on open-source English datasets LibriSpeech [8] and English – Mozilla Common Voice [10]. Then we fine-tune the pre-trained acoustic and language models with the Wall Street Journal (WSJ) news dataset [9,12,13].
Acoustic Model Training
The Domain Specific – NeMo ASR Application helps you do transfer learning with a notebook that walks you through the process of fine-tuning a pre-trained model with domain specific data and comparing the performance of the baseline pre-trained model vs. the fine-tuned model.
As a starting point, we use a NeMo pre-trained acoustic model named QuartzNet [6, 7, 11]. QuartzNet [6, 7] is an end-to-end neural acoustic model for automatic speech recognition. This model consists of separable convolutions and larger filters, often denoted by QuartzNet_[BxR], where B is the number of blocks, and R – the number of convolutional sub-blocks within a block. Each sub-block contains a 1D separable convolution, batch normalization, ReLU, and dropout. The QuartzNet model can achieve Jasper’s [5] performance, but with a lot less parameters (from about 333M to about 19M). Both Jasper and QuartzNet are a CTC-based end-to-end model, which can predict a transcript directly from an audio input, without additional alignment information.
Specifically, the pre-trained model we use is a QuartzNet15x5, which is formed by an Encoder and Decoder neural module’s checkpoints available for download in NGC [11]. These modules were trained using LibriSpeech (+-10% speed perturbation) and Mozilla’s EN Common Voice “validated” set.
To demonstrate that acoustic model training on your own data has the biggest effect on performance, we fine-tune the pre-trained model with Wall Street Journal Datasets [12,13]. The training dataset consisted of about 250 hours of audio, for which we used speed perturbation of +-10% to provide data augmentation and diversity to the original dataset. We fine-tune the pre-trained model with only 100 epochs and improved performance by over 55%.
ASR performance is typically measured by Word Error Rate (WER) which is determined by the formula: Word Error Rate = (Substitutions + Insertions + Deletions) / Number of Words Spoken. The Table below shows the baseline model (trained on LibriSpeech + Common Voice) achieving 10.05% WER and the fine-tuned model (fine-tuned on WSJ) achieving 4.45% WER, this represents over 55% reduction in relative error.
Adding a Language model
Up to now, the output or transcript the ASR system is generated by an “end-to-end” CTC-based network [4] which matches audio and text without additional alignment information. However, ambiguities in the transcription, for example when collapsing repeated characters and removing blanks, can exist as the CTC-based network has little prior linguistic knowledge besides what it learned from a limited training corpus. This is where a language model comes in, as it can help solve those decoding ambiguities. Specifically, the decoder output or transcript, when introducing a language model, is dependent on both the CTC network (softmax) output and the language model. The Language Model (LM) we use is based on prefix beam search KenLM [14] which imposes a language model constraint on the new prediction based on previous (most probable) prefixes.
The Domain Specific – NeMo ASR Application provides a notebook to evaluate the effect in performance of adding a language model. Specifically, we evaluate the effect of two different language models: one trained on LibriSpeech data and another trained on WSJ data. As shown in the table below, adding a language model to the fine-tuned acoustic model was beneficiary. We reduced WER by about 1% by adding an LM trained on LibriSpeech and reduce WER by over 2% when adding a LM trained on the domain data, i.e. WSJ. Overall, we reduced baseline performance from 10.05% WER to 2.39% WER, resulting in 76% performance improvement by fine-tuning the acoustic model and adding a language model trained on our domain data.
Comparing Word Error Rate
The overall performance results of our domain adaptation example use case is shown in the table below. We evaluated all models with two different datasets: wsj-eval-92 and wsj-dev-93. You can see in both cases WER decreased by about 75% and the largest performance improvement was achieved by acoustic model fine-tuning, as well adding a language model trained on domain data improved the fine-tuned acoustic model performance by almost 50%.
| Network | Models | Model ID | WSJ | WSJ | |
| AM | Decoder/LM | wsj-eval-92.json | wsj-dev-93.json | ||
| QuartzNet 15×5 | Pre-trained | Greedy | am-pretrained-greedy-decoder | 10.05% | 14.27% |
| Fine-tuned | Greedy | am-finetuned-WSJ_train_speed-greedy-decoder | 4.45% | 6.59% | |
| Fine-tuned | 6-gram – Libri | am-finetuned-WSJ_train_speed–lm-Libri | 3.70% | 5.57% | |
| Fine-tuned | 6-gram – WSJ | am-finetuned-WSJ_train_speed–lm-WSJ | 2.39% | 3.76% | |
| Performance Improvement: | 76% | 74% |
Getting Started
The Domain Specific – NeMo ASR Application is available for download as a docker container (search for nemo_asr_app_img) on NVIDIA’s container registry and software hub, NGC [15]. The NeMo toolkit is open source, and is available on GitHub in the NeMo (Neural Modules) repository [1].
Additionally, multiple pre-trained ASR models are available in NGC. You can download the acoustic model checkpoints for QuartzNet15x5 trained on LibriSpeech+CommonVoice (nvidia:quartznet15x5) [11], as well as the fine-tuned acoustic (wsj_quartznet_15x5) and language models (wsj_lm_decoder) created in this example use-case. With all these available resources, now you are ready to start doing Automatic Speech Recognition, using the pre-trained models for inference on your own data or fine-tune these for your specific domain using the Domain Specific – NeMo ASR Application.
References
- NVIDIA. Neural Modules (NeMo) on Github. Retrieved from https://github.com/NVIDIA/NeMo
- NVIDIA. Neural Modules (NeMo) Tutorial. Retrieved from https://nvidia.github.io/NeMo/index.html
- Borgholt, L. CTC Networks and Language Models: Prefix Beam Search Explained. Retrived from https://medium.com/corti-ai/ctc-networks-and-language-models-prefix-beam-search-explained-c11d1ee23306
- Graves, A., Fernández, S., Gomez, F., & Schmidhuber, J. (2006, June). Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning . ACM. https://www.cs.toronto.edu/~graves/icml_2006.pdf
- Li, J., Lavrukhin, V., Ginsburg, B., Leary, R., Kuchaiev, O., Cohen, J. M., … & Gadde, R. T. (2019). Jasper: An End-to-End Convolutional Neural Acoustic Model. arXiv preprint arXiv:1904.03288. https://arxiv.org/pdf/1904.03288.pdf
- Kriman, S., Beliaev, S., Ginsburg, B., Huang, J., Kuchaiev, O., Lavrukhin, V., … & Zhang, Y. (2019). QuartzNet: Deep Automatic Speech Recognition with 1D Time-Channel Separable Convolutions. arXiv preprint arXiv:1910.10261. https://arxiv.org/pdf/1910.10261.pdf
- Huang, J. , et. al. Develop Smaller Speech Recognition Models with NVIDIA’s NeMo Framework. Retrieved from https://developer.nvidia.com/blog/develop-smaller-speech-recognition-models-with-nvidias-nemo-framework/
- Povey, D. LibriSpeech ASR corpus. Retrieved from http://www.openslr.org/12
- Linguistic Data Consortium. Wall Street Journal. Retrieved from https://www.ldc.upenn.edu/
- Mozilla Common Voice Dataset. Retrieved from https://voice.mozilla.org/en/datasets
- NVIDIA NGC. QuartzNet 15×5 for NeMo https://ngc.nvidia.com/catalog/models/nvidia:quartznet15x5
- Linguistic Data Consortium. Wall Street Journal – CSR-I (WSJ0) Complete. Retrieved from https://catalog.ldc.upenn.edu/LDC93S6A
- Linguistic Data Consortium. Wall Street Journal – CSR-II (WSJ1) Complete. Retrieved from: https://catalog.ldc.upenn.edu/LDC94S13A
- Heafield, K. KenLM: Faster and Smaller Language Model Queries. Retrieved from https://github.com/kpu/kenlm
- NVIDIA NGC – Accelerated Software. Retrieved from http://ngc.nvidia.com/