Editor’s note: Interested in GPU Operator? Register for our upcoming webinar on January 20th, “How to Easily use GPUs with Kubernetes”.
In the last post, we looked at how the GPU Operator has evolved, adding a rich feature set to handle GPU discovery, support for the new Multi-Instance GPU (MIG) capability of the NVIDIA Ampere Architecture, vGPU, and certification for use with Red Hat OpenShift.
In this post, we look at the new features added in the GPU Operator release 1.8, further simplifying GPU management for various deployment scenarios, including:
- Added support for GPU Operator upgrades
- Support for NVSwitch Systems NVIDIA HGX A100 servers
- Support for gathering GPU Operator State Metrics
- GPU Operator and Network Operator Improve Multinode Training
- Support for Red Hat OpenShift 4.8
NVIDIA Software Lifecycle Management
Version 1.8 of GPU Operator provides an update mechanism for organizations to update their GPU Operator version without disrupting the workflow of the cluster the GPU Operator is running on. Previous releases of GPU Operator required users to uninstall the prior version before installing the new version, meaning no GPUs in the cluster were usable during the upgrade process.
Starting with 1.8, upgrading versions doesn’t disrupt the workflow. The mechanism updates one node at a time in a rolling fashion, so the other nodes can continue to be used. The next node is updated only when the installation is complete and the previous node is back online. Users can be confident that their workflow will be better managed when updating GPU Operator.
Now Supporting NVSwitch Systems
With 1.8, the GPU Operator automatically deploys the software required for initializing the fabric on NVIDIA NVSwitch systems, such as the NVIDIA HGX A100. Once initialized, all GPUs can communicate with one another at full NVLink bandwidth to create an end-end scalable computing platform.
Support for Gathering GPU Operator State Metrics
With 1.8, the GPU Operator now reports various metrics for users to monitor overall health of the GPU Operator and operator deployed resources under the gpu-operator-resources namespace. SRE teams and Cluster administrators can now configure necessary Prometheus resources to gather metrics and also to trigger alerts on certain failure conditions.
For the OpenShift Container Platform, these resources are automatically created in this release. Monitoring solutions like Grafana can be used to build dashboards and visualize the operational status of GPU Operator and node components.
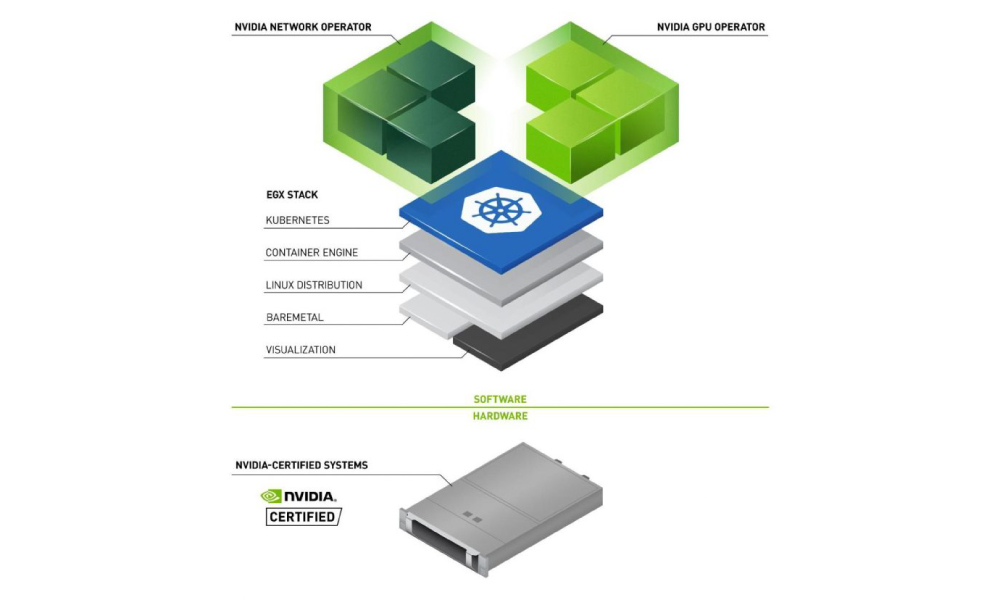
Better Together: NVIDIA Accelerated Compute and Networking
Recently, NVIDIA announced the 1.0 release of the NVIDIA Network Operator. An analog to the NVIDIA GPU Operator, the Network Operator simplifies scale-out network design for Kubernetes by automating aspects of network deployment and configuration that would otherwise require manual work. It loads the required drivers, libraries, device plug-ins, and CNIs on any cluster node with an NVIDIA network interface.
When they are deployed together, the NVIDIA GPU and Network operators enable GPUDirect RDMA, a fast data path between NVIDIA GPUs on different nodes. This is a critical technology enabler for data-intensive workloads like AI Multi-Node Training.
Learn more about the latest NVIDIA Network Operator release.
Added Support for Red Hat OpenShift
We continue our line of support for Red Hat OpenShift.
- GPU Operator 1.8 and 1.7 support both Red Hat OpenShift 4.8 and 4.7
- GPU Operator 1.6 supports Red Hat OpenShift 4.7
- GPU Operator 1.5 supports Red Hat OpenShift 4.6
- GPU Operator 1.4 and 1.3 support Red Hat OpenShift 4.5 and 4.4, respectively
Summary
The following resources are available for using NVIDIA GPU Operator:
- GPU Operator 1.8 Release Notes
- Getting Started Guide
- GPU Operator Helm Chart on NGC
- GPU Operator on GitHub
The NVIDIA GPU Operator is a key component to many edge computing solutions. Learn more about NVIDIA solutions for edge computing.