
The growing prevalence of GPU-accelerated computing in the cloud, enterprise, and at the edge increasingly relies on robust and powerful network infrastructures. NVIDIA ConnectX SmartNICs and NVIDIA BlueField DPUs provide high-throughput, low-latency connectivity that enables the scaling of GPU resources across a fleet of nodes. To address the demand for cloud-native AI workloads, NVIDIA delivers the GPU Operator, aimed at simplifying scale-out GPU deployment and management on Kubernetes.
Today, NVIDIA announced the 1.0 release of the NVIDIA Network Operator. An analog to the NVIDIA GPU Operator, the Network Operator simplifies scale-out network design for Kubernetes by automating aspects of network deployment and configuration that would otherwise require manual work. It loads the required drivers, libraries, device plugins, and CNIs on any cluster node with an NVIDIA network interface.
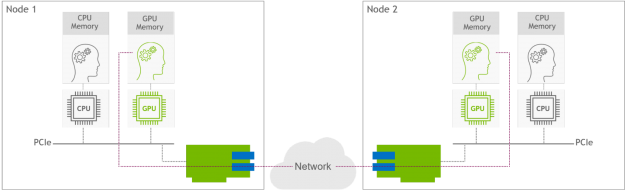
Paired with the GPU Operator, the Network Operator enables GPUDirect RDMA, a key technology that accelerates cloud-native AI workloads by orders of magnitude. The technology provides an efficient, zero-copy data transfer between NVIDIA GPUs while leveraging the hardware engines in the SmartNICs and DPUs. Figure 1 shows GPUDirect RDMA technology between two GPU nodes. The GPU on Node 1 directly communicates with the GPU on Node 2 over the network, bypassing the CPU devices.
Now available on NGC and GitHub, the NVIDIA Network Operator uses Kubernetes custom resources (CRD) and the Operator framework to provision the host software needed for enabling accelerated networking. This post discusses what’s inside the network operator, including its features and capabilities.
Kubernetes networking that’s easy-to-deploy and operate
The Network Operator is geared towards making Kubernetes networking simple and effortless. It’s an open-source software project under the Apache 2.0 license. The 1.0 release was validated for Kubernetes running on bare-metal server infrastructure and in Linux virtualization environments. Here are the key features of the 1.0 release:
- Automated deployment of host software components in a bare-metal Kubernetes environment for enabling the following:
- macvlan secondary networks
- SR-IOV secondary networks (VF assigned to pod)
- Host device secondary networks (PF assigned to pod)
- GPUDirect RoCE (with the NVIDIA GPU Operator)
- Automated deployment of host software components in a nested Kubernetes environment (Kubernetes Pods running in Linux VMs) for creating the following:
- SR-IOV secondary networks (# of VFs assigned to VM and passthrough to different pods)
- Host device secondary networks (PF assigned to Pod)
- GPUDirect RoCE (with the NVIDIA GPU Operator)
- Platform support:
- Kubernetes v1.17 or later
- Container runtime: Containerd
- Bare-metal host OS/Linux guest OS: Ubuntu 20.04
- Linux KVM virtualization
- Helm chart installation
While GPU-enabled nodes are a primary use case, the Network Operator is also useful for enabling accelerated Kubernetes network environments that are independent of NVIDIA GPUs. Some examples include setting up SR-IOV networking and DPDK for accelerating telco NFV applications, establishing RDMA connectivity for fast access to NVMe storage, and more.
Inside the NVIDIA Network Operator
The Network Operator is designed from the ground up as a Kubernetes Operator that makes use of several custom resources for adding accelerated networking capabilities to a node. The 1.0 version supports several networking models adapted to both various Kubernetes networking environments and varying application requirements. Today, the Network Operator configures RoCE only for secondary networks. This means that the primary pod network remains untouched. Future work may enable configuring RoCE for the primary network.
The following sections describe the different components that are packaged and used by the Network Operator.
Node Feature Discovery
Node Feature Discovery (NFD) is a Kubernetes add-on for detecting hardware features and system configuration. The Network Operator uses NFD to detect nodes installed with NVIDIA SmartNICs and GPU, and label them as such. Based on those labels, the Network Operator schedules the appropriate software resources.
Multus CNI
The Multus CNI is a container network interface (CNI) plugin for Kubernetes that enables attaching multiple network interfaces to pods. Normally in Kubernetes each Pod only has one network interface. With Multus, you can create a multihomed Pod that has multiple interfaces. Multus acting as a meta-plugin, a CNI plugin that can call multiple other CNI plugins. The NVIDIA Network Operator installs Multus to add to a container pod the secondary networks that are used for high-speed GPU-to-GPU communications.
NVIDIA OFED driver
The NVIDIA OpenFabrics Enterprise Distribution (OFED) networking libraries and drivers are packaged and tested by the NVIDIA networking team. NVIDIA OFED supports Remote Direct Memory Access (RDMA) over both Infiniband and Ethernet interconnects. The Network Operator deploys a precompiled NVIDIA OFED driver container onto each Kubernetes host using node labels. The container loads and unloads the NVIDIA OFED drivers when it is started or stopped.
NVIDIA peer memory driver
The NVIDIA peer memory driver is a client that interacts with the network drivers to provide RDMA between GPUs and host memory. The Network Operator installs the NVIDIA peer memory driver on nodes that have both a ConnectX adapter and an NVIDIA GPU. This driver is also loaded and unloaded automatically when the container is started and stopped.
RDMA shared device plugin
The Kubernetes device plugin framework advertises system hardware resources to the Kubelet agent running on a Kubernetes node. The Network Operator deploys the RDMA shared device plugin that advertises RDMA resources to Kubelet and exposes RDMA devices to Pods running on the node. It allows the Pods to perform RDMA operations. All Pods running on the node share access to the same RDMA device files.
Container networking CNI plugins
The macvlan CNI and host-device CNI are generic container networking plugins that are hosted under the CNI project. The macvlan CNI creates a new MAC address, and forwards all traffic to the container. The host-device CNI moves an already-existing device into a container. The Network Operator uses these CNI plugins for creating macvlan networks, and assigning NIC physical functions to a container or virtual machine, respectively.
SR-IOV device plugin and CNI
SR-IOV is a technology providing a direct interface between the virtual machine or container pod and the NIC hardware. It bypasses the host CPU and OS , frees up expensive CPU resources from I/O tasks, and greatly accelerates connectivity. The SR-IOV device plugin and CNI plugin enable advertising SR-IOV virtual functions (VFs) available on a Kubernetes node. Both are required by the Network Operator for creating and assigning SR-IOV VFs to secondary networks on which GPU-to-GPU communication is handled.
SR-IOV Operator
The SR-IOV Operator is designed to help the user to provision and configure the SR-IOV device plugin and SR-IOV CNI plugin in the cluster. The Network Operator uses the SR-IOV Operator to deploy and manage SR-IOV in the Kubernetes cluster.
Whereabouts CNI
The Whereabouts CNI is an IP address management (IPAM) CNI plugin that can assign IP addresses in a Kubernetes cluster. The Network Operator uses this CNI to assign IP addresses for secondary networks that carry GPU-to-GPU communication.
Better together: NVIDIA accelerated compute and networking
Figure 2 shows how the Network Operator works in tandem with the GPU Operator to deploy and manage the host networking software.

The following sections describe the supported networking models, and corresponding host software components.
RoCE shared mode
Shared mode implies the method where a single IB device is shared between several container pods on the node. This networking model is optimized for enterprise and edge environments that require high-performance networking, without multitenancy. The Network Operator installs the following software components:
- Multus CNI
- RoCE shared mode device plugin
- macvlan CNI
- Whereabouts IPAM CNI
The Network Operator also installs the NVIDIA OFED Driver and NVIDIA Peer Memory on GPU nodes.
SR-IOV, RoCE, and DPDK networking
As mentioned earlier, SR-IOV is an acceleration technology that provides direct access to the NIC hardware. This networking model is optimized for multitenant Kubernetes environments, running on bare-metal. The Network Operator installs the following software components:
- Multus CNI
- SR-IOV device plugin
- SR-IOV CNI
- Whereabouts IPAM CNI
The Network Operator also installs the NVIDIA OFED Driver and NVIDIA Peer Memory on GPU nodes.
NIC PF passthrough
This networking model is suited for extremely demanding applications. The Network Operator can assign the NIC physical function to a Pod so that the Pod uses it fully. The Network Operator installs the following host software components:
- Multus CNI
- SR-IOV device plugin
- Host-Dev CNI
- Whereabouts IPAM CNI
The Network Operator also installs the NVIDIA OFED Driver and NVIDIA Peer Memory on GPU nodes.
Streamlining Kubernetes networking for scale-out GPU clusters
The NVIDIA GPU and Network Operators are both part of the NVIDIA EGX Enterprise platform that allows GPU-accelerated computing work alongside traditional enterprise applications on the same IT infrastructure. Taken together, the operators make the NVIDIA GPU a first-class citizen in Kubernetes. Now released for use in production environments, the Network Operator streamlines Kubernetes networking, bringing the necessary levels of simplicity and scalability for enabling scale-out training and edge inferencing in the enterprise.
For more information, see the Network Operator documentation. You can also download the Network Operator from NGC to see it in action, and join the developer community in the network-operator GitHub repo.
