Editor’s note: Interested in GPU Operator? Register for our upcoming webinar on January 20th, “How to Easily use GPUs with Kubernetes”.
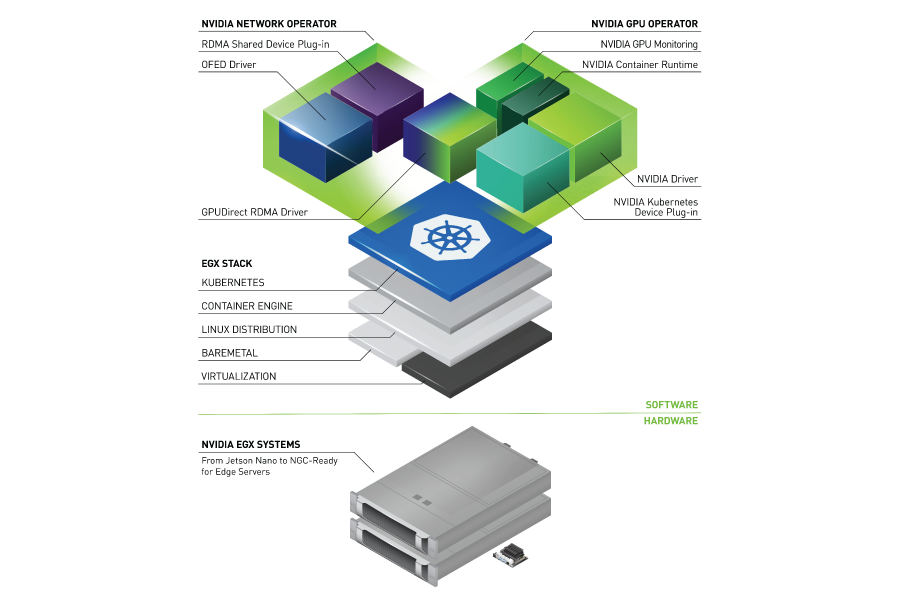
Reliably provisioning servers with GPUs in Kubernetes can quickly become complex as multiple components must be installed and managed to use GPUs. The GPU Operator, based on the Operator Framework, simplifies the initial deployment and management of GPU servers. NVIDIA, Red Hat, and others in the community have collaborated on creating the GPU Operator.
To provision GPU worker nodes in a Kubernetes cluster, the following NVIDIA software components are required:
- NVIDIA Driver
- NVIDIA Container Toolkit
- Kubernetes device plugin
- Monitoring
These components should be provisioned before GPU resources are available to the cluster and managed during the cluster operation.
The GPU Operator simplifies both the initial deployment and management of the components by containerizing all components. It uses standard Kubernetes APIs for automating and managing these components, including versioning and upgrades. The GPU Operator is fully open source. It is available on NGC and as part of the NVIDIA EGX Stack and Red Hat OpenShift.
The latest GPU Operator releases, 1.6 and 1.7, include several new features:
- Support for automatic configuration of MIG geometry with NVIDIA Ampere Architecture products
- Support for preinstalled NVIDIA drivers and the NVIDIA Container Toolkit
- Updated support for Red Hat OpenShift 4.7
- Updated GPU Driver version to include support for NVIDIA A40, A30, and A10
- Support for RuntimeClasses with Containerd
Multi-Instance GPU support
Multi-Instance GPU (MIG) expands the performance and value of each NVIDIA A100 Tensor Core GPU. MIG can partition the A100 or A30 GPU into as many as seven instances (A100) or four instances (A30), each fully isolated with their own high-bandwidth memory, cache, and compute cores.
Without MIG, different jobs running on the same GPU, such as different AI inference requests, compete for the same resources, such as memory bandwidth. With MIG, jobs run simultaneously on different instances, each with dedicated resources for compute, memory, and memory bandwidth. This results in predictable performance with quality of service and maximum GPU utilization. Because simultaneous jobs can operate, MIG is ideal for edge computing use cases.
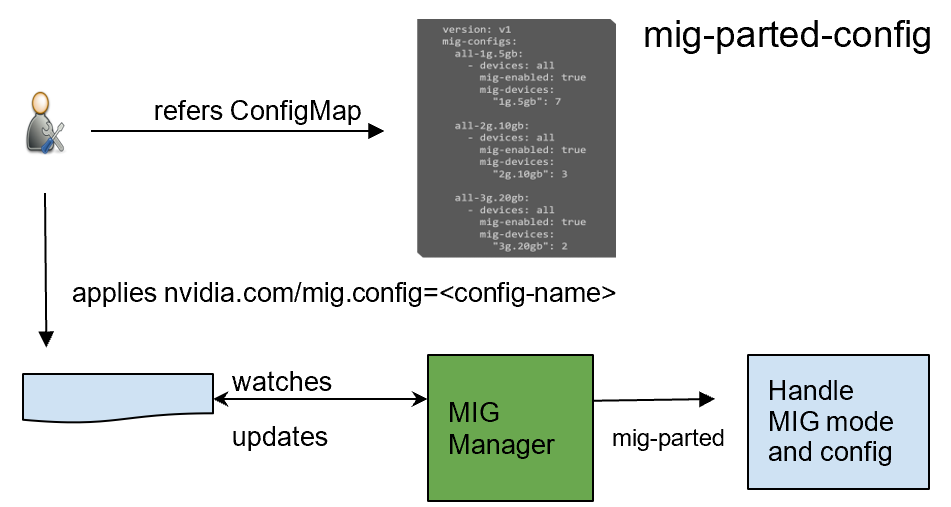
GPU Operator 1.7 added a new component called NVIDIA MIG Manager for Kubernetes, which runs as a DaemonSet and manages MIG mode and MIG configuration changes on each node. You can apply MIG configuration on the node by adding a label that indicates the predefined configuration name to be applied. After applying MIG configuration, GPU Operator automatically validates that MIG changes are applied as expected. For more information, see GPU Operator with MIG.
Preinstalled drivers and Container Toolkit
GPU Operator 1.7 now supports selectively installing NVIDIA Driver and Container Toolkit (container config) components. This new feature provides great flexibility for environments where the driver or nvidia-docker2 packages are preinstalled. These environments can now use GPU Operator for simplified management of other software components like Device Plugin, GPU Feature Discovery Plugin, DCGM Exporter for monitoring, or MIG Manager for Kubernetes.
Install command with only the drivers preinstalled:
helm install --wait --generate-name \ nvidia/gpu-operator \ --set driver.enabled=false
Install command with both drivers and nvidia-docker2 preinstalled:
helm install --wait --generate-name \ nvidia/gpu-operator \ --set driver.enabled=false --set toolkit.enabled=false
Added support for Red Hat OpenShift
We continue our line of support for Red Hat OpenShift,
- GPU Operator 1.6 and 1.7 include support for the latest Red Hat OpenShift 4.7 version.
- GPU Operator 1.5 supports Red Hat OpenShift 4.6.
- GPU Operator 1.4 and 1.3 support Red Hat OpenShift 4.5 and 4.4, respectively.
GPU Operator is an OpenShift certified operator. Through the OpenShift web console, you can install and start using the GPU Operator with only a few mouse clicks. Being a certified operator makes it significantly easier for you to use NVIDIA GPUs with Red Hat OpenShift.
GPU Driver support for NVIDIA A40, A30, and A10
We updated the GPU Driver version to include support for NVIDIA A40, A30, and A10.
NVIDIA A40
The NVIDIA A40 delivers the data center-based solution that designers, engineers, artists, and scientists need for meeting today’s challenges. Built on the NVIDIA Ampere Architecture, the A40 combines the latest generation RT Cores, Tensor Cores, and CUDA Cores. It has 48 GB of graphics memory for unprecedented graphics, rendering, compute, and AI performance. From powerful virtual workstations accessible from anywhere, to dedicated render and compute nodes, the A40 is built to tackle the most demanding visual computing workloads from the data center.
For more information, see NVIDIA A40.
NVIDIA A30
The NVIDIA A30 Tensor Core GPU is the most versatile mainstream compute GPU for AI inference and enterprise workloads. Tensor Cores with MIG combine with fast memory bandwidth in a low 165W power envelope, all in a PCIe form factor ideal for mainstream servers.
Built for AI inference at scale, A30 can also rapidly retrain AI models with TF32 as well as accelerate HPC applications using FP64 Tensor Cores. The combination of the NVIDIA Ampere Architecture Tensor Cores and MIG delivers speedups securely across diverse workloads, all powered by a versatile GPU enabling an elastic data center. The versatile A30 compute capabilities deliver maximum value for mainstream enterprises.
For more information, see NVIDIA A30.
NVIDIA A10
The NVIDIA A10 Tensor Core GPU is the ideal GPU for mainstream media and graphics with AI. Second-generation RT Cores and third-generation Tensor Cores enrich graphics and video applications with powerful AI. NVIDIA A10 delivers a single-wide, full-height, full-length PCIe form factor and a 150W power envelope for dense servers.
Built for graphics, media, and cloud gaming applications with powerful AI capabilities, the NVIDIA A10 Tensor Core GPU can deliver rich media experiences. It delivers up to 4k for cloud gaming, with 2.5x the graphics and over 3x the inference performance compared to the NVIDIA T4 Tensor Core GPU.
For more information, see NVIDIA A10.
RuntimeClass support with Containerd
RuntimeClass provides you with the flexibility of choosing the container runtime configuration per Pod and then applying the default runtime configuration for all Pods on each node. With this support, you can specify the specific runtime configuration for Pods running GPU-accelerated workloads and choose other runtimes for generic workloads.
GPU Operator v1.7.0 now supports auto creation of nvidia RuntimeClass when default runtime is selected as containerd during installation. You can explicitly specify this RuntimeClass name when running applications consuming GPUs.
apiVersion: node.k8s.io/v1beta1 handler: nvidia kind: RuntimeClass metadata: labels: app.kubernetes.io/component: gpu-operator name: nvidia
Summary
To start using NVIDIA GPU Operator today, see the following resources:
