Editor’s note: Interested in GPU Operator? Register for our upcoming webinar on January 20th, “How to Easily use GPUs with Kubernetes”.
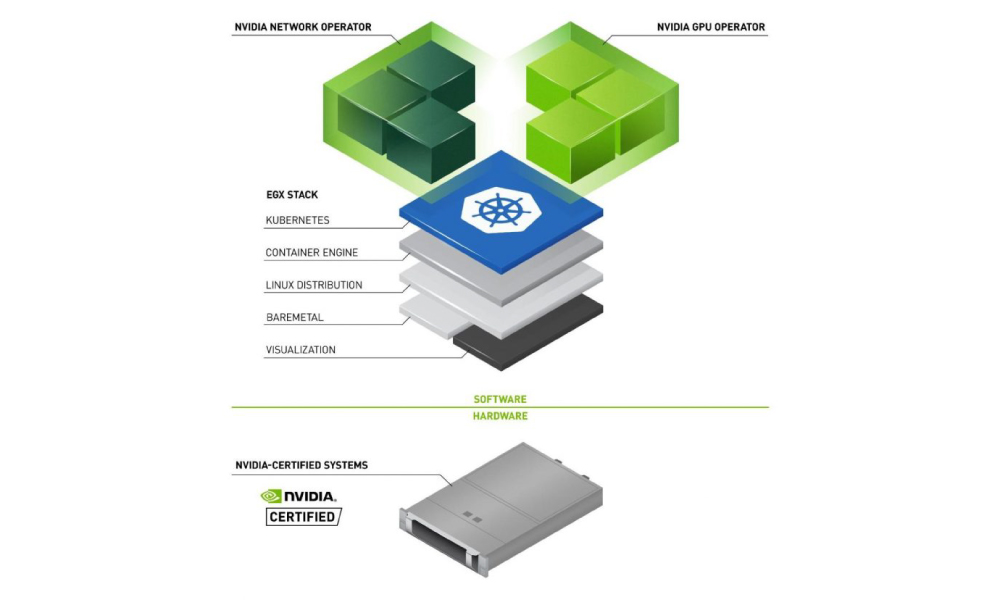
NVIDIA GPU Operator allows organizations to easily scale NVIDIA GPUs on Kubernetes.
By simplifying the deployment and management of GPUs with Kubernetes, the GPU Operator enables infrastructure teams to scale GPU applications error-free, within minutes, automatically.
GPU Operator 1.9 is now available and includes several key features, among other updates, that allow users to get started faster and maintain uninterrupted service.
GPU Operator 1.9 includes:
- Support for NVIDIA DGX A100 systems with DGX OS
- Streamlined installation process
Support for DGX A100 with DGX OS
With 1.9, the GPU Operator automatically deploys the software required for initializing the fabric on NVIDIA NVSwitch systems, including the DGX A100 when used with DGX OS. Once initialized, all GPUs can communicate with one another at full NVLink bandwidth to create an end-to-end scalable computing platform.
The DGX A100 features the world’s most advanced accelerator, enabling enterprises to consolidate training, inference, and analytics into a unified, easy-to-deploy AI infrastructure. And now, with GPU Operator support, organizations can take their applications from training to scale with the world’s most advanced systems.
Streamlined installation process
With previous versions of GPU Operator, organizations using GPU Operator with OpenShift needed to apply additional entitlements from Red Hat in order to successfully use the GPU Operator. As entitlement keys expired, users would need to re-apply them to ensure that their workflow was not interrupted.
GPU Operator 1.9 now supports entitlement-free driver containers for OpenShift. This is done by leveraging Driver-Toolkit images provided by RedHat with necessary kernel packages preinstalled for building NVIDIA kernel modules. Users no longer need to ensure that valid certificates with an RHEL subscription are always applied for running GPU Operator. More importantly for disconnected clusters, it eliminates dependencies on private package repositories.
Version 1.9 also includes support for preinstalled drivers with the MIG Manager, support for preinstalled MOFED to use GPUDirect RDMA, automatic detection of container runtime, and automatic disabling of NOUVEAU – all designed to make it easier for users to get started and continue GPU-accelerated Kubernetes.
Additionally, GPU Operator 1.9 automatically detects the container runtime installed on the worker node. There is no need to specify the container runtime at install time.
GPU Operator 1.9:
helm install --wait --generate-name nvidia/gpu-operator
GPU Operator 1.8 and earlier:
helm install --wait --generate-name nvidia/gpu-operator --set operator.defaultRuntime=containerd
GPU Operator requires Nouveau to be disabled. With previous GPU Operator versions, the K8s admin had to disable Nouveau as documented here. GPU Operator 1.9 automatically detects if Nouveau is enabled and disables it for you.
GPU Operator Resources
The following resources are available for using NVIDIA GPU Operator:
- GPU Operator 1.9 Release Notes
- Getting Started Guide
- GPU Operator Helm Chart on NGC
- GPU Operator on GitHub
The NVIDIA GPU Operator is a key component to many edge computing solutions. Learn more about NVIDIA solutions for edge computing.