Today’s data science problems demand a dramatic increase in the scale of data as well as the computational power required to process it. Unfortunately, the end of Moore’s law means that handling large data sizes in today’s data science ecosystem requires scaling out to many CPU nodes, which brings its own problems of communication bottlenecks, energy, and cost (see figure 1).
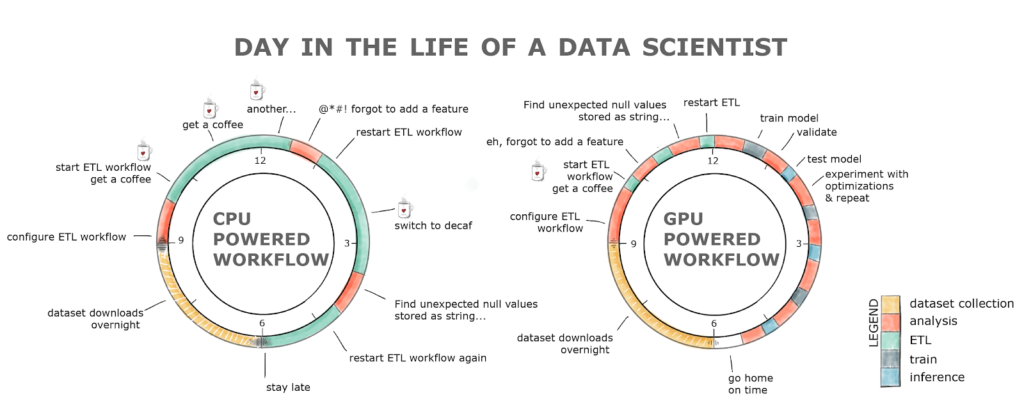
A key part of data science is data exploration. To prepare a dataset for training a machine learning algorithm requires understanding the dataset, cleaning and manipulating data types and formats, filling in gaps in the data, and engineering features for the learning algorithm. These tasks are often grouped under the term Extract, Transform, Load (ETL). ETL is often an iterative, exploratory process. As datasets grow, the interactivity of this process suffers when running on CPUs.
To address the challenges of the modern data science pipeline, today at GTC Europe NVIDIA announced RAPIDS, a suite of open-source software libraries for executing end-to-end data science and analytics pipelines entirely on GPUs. RAPIDS aims to accelerate the entire data science pipeline including data loading, ETL, model training, and inference. This will enable more productive, interactive, and exploratory workflows.
RAPIDS is the result of contributions from the machine learning community and GPU Open Analytics Initiative (GOAI) partners. Established in 2017 with the goal of accelerating end-to-end analytics and data science pipelines on GPUs, GOAI created the GPU DataFrame based on Apache Arrow data structures. The GPU DataFrame enabled the integration of GPU-accelerated data processing and machine learning libraries without incurring typical serialization and deserialization penalties. RAPIDS builds on and extends the earlier GOAI work.
Boosting Data Science Performance with RAPIDS
RAPIDS achieves speedup factors of 50x or more on typical end-to-end data science workflows. RAPIDS uses NVIDIA CUDA for high-performance GPU execution, exposing that GPU parallelism and high memory bandwidth through user-friendly Python interfaces. RAPIDS focuses on common data preparation tasks for analytics and data science, offering a powerful and familiar DataFrame API. This API integrates with a variety of machine learning algorithms without paying typical serialization costs, enabling acceleration for end-to-end pipelines. RAPIDS also includes support for multi-node, multi-GPU deployments, enabling scaling up and out on much larger dataset sizes.
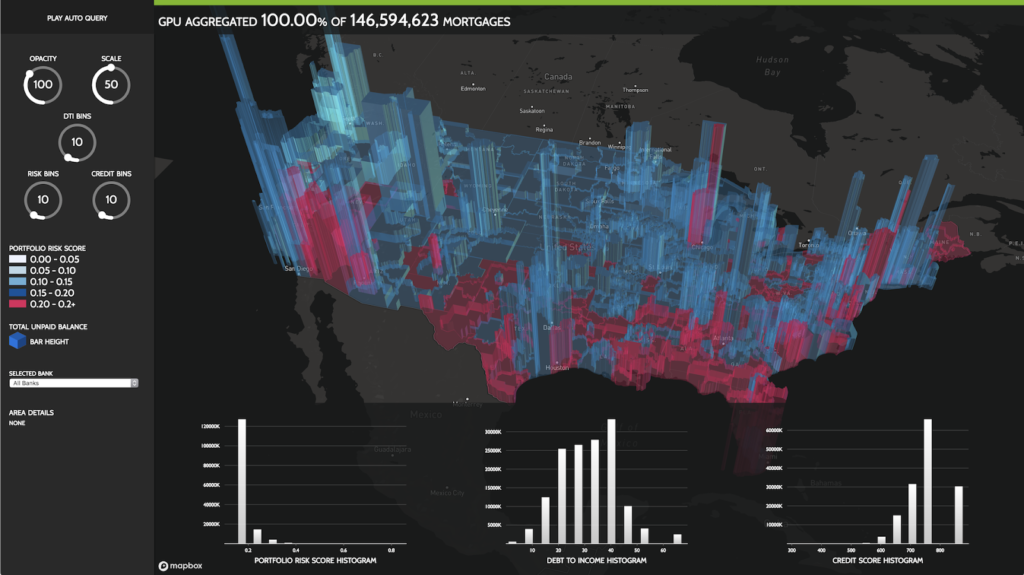
The RAPIDS container includes a notebook and code that demonstrates a typical end-to-end ETL and ML workflow. The example trains a model to perform home loan risk assessment using all of the loan data for the years 2000 to 2016 in the Fannie Mae loan performance dataset, consisting of roughly 400GB of data in memory. Figure 2 shows a geographical visualization of the loan risk analysis.
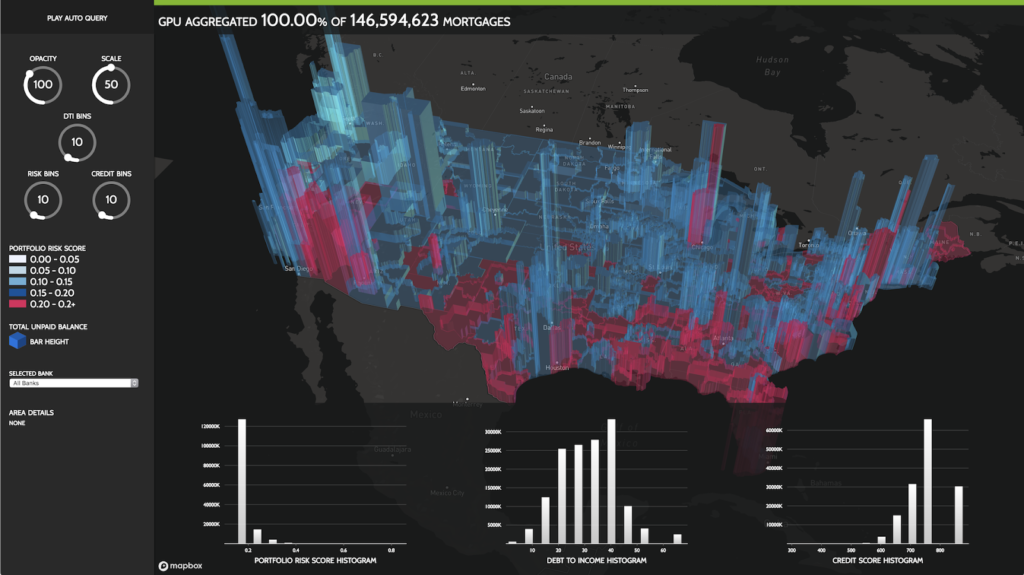
The example loads the data into GPU memory using the RAPIDS CSV reader. The ETL in this example performs a number of operations including extracting months and years from datetime fields, joins of multiple columns between DataFrames, and groupby aggregations for feature engineering. The resulting feature data is then converted and used to train a gradient boosted decision tree model on the GPU using XGBoost.
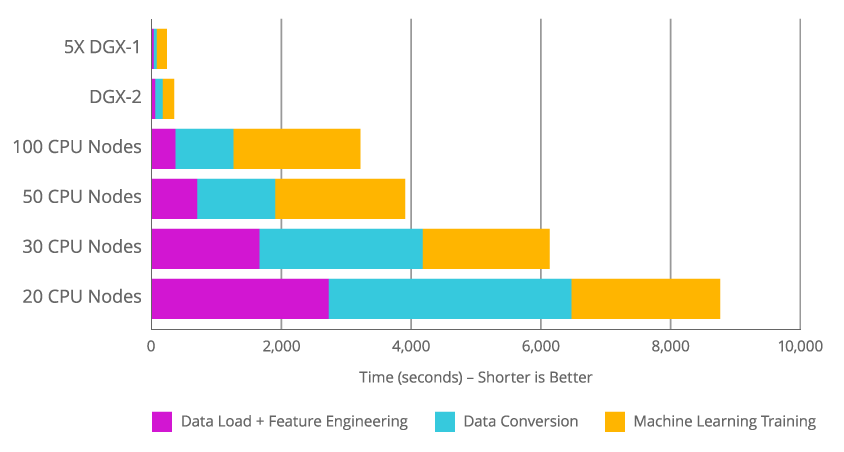
This workflow runs end-to-end on a single NVIDIA DGX-2 server with 16x Tesla V100 GPUs, 10x faster than 100 AWS r4.2xLarge instances, as the chart in figure 3 shows. Comparing GPU to CPU performance one-to-one, this equates to well over a 50x speedup .
The Need for End-to-End Acceleration
GPU acceleration of classical machine learning algorithms, such as gradient boosting, has already become popular. However, previous efforts at GPU-accelerating data science pipelines have focused on individual machine learning libraries and not other crucial interconnecting pieces of the pipeline. This creates a problem. Let’s say your pipeline has three steps:
- Load data
- Clean up the data and perform feature engineering
- Train a classifier
First you load the data into host memory. Then perform ETL tasks including data clean-up and feature engineering steps such as filtering, imputation, and generating new features. These steps today are largely done using the CPU. After that you must convert the output of the feature engineering step into the internal memory format of the GPU-accelerated machine learning library and then move the data to GPU memory. Now, you run training. You get a huge speedup on the training step, and you’re happy. Finally, you move the data back to host memory and visualize or prepare for deployment.
At the end you get a modest overall speedup, but the copy and convert operations introduce significant overhead due to serialization and deserialization operations and you end up underutilizing the available GPU processing power.
RAPIDS addresses this issue by design. It provides a columnar data structure called a GPU DataFrame, which implements the Apache Arrow columnar data format on the GPU. The RAPIDS GPU DataFrame provides a pandas-like API that will be familiar to data scientists, so they can now build GPU-accelerated workflows more easily.
RAPIDS Software Libraries
Data Scientists using RAPIDS interact with it using the following high-level python packages.
- cuDF: A GPU DataFrame library with a pandas-like API. cuDF provides operations on data columns including unary and binary operations, filters, joins, and groupbys. cuDF currently comprises the Python library PyGDF, and the C++/CUDA GPU DataFrames implementation in libgdf. These two libraries are being merged into cuDF. See the documentation for more details and examples.
- cuSKL: A collection of machine learning algorithms that operate on GPU DataFrames. cuSKL enables data scientists, researchers, and software engineers to run traditional ML tasks on GPUs without going into the details of CUDA programming from Python.
- XGBoost: XGBoost is one of the most popular machine learning packages for training gradient boosted decision trees. Native cuDF support allows you to pass data directly to XGBoost while remaining in GPU memory.
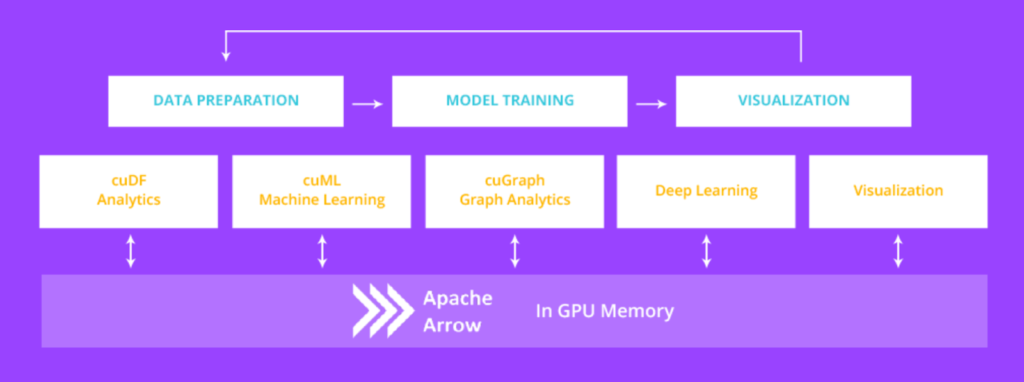
cuSKL is a library in cuML to make the following lower-level libraries more accessible for Python developers. More information about these libraries is available in the documentation. Figure 4 highlights the overall structure and flow of the pipeline using RAPIDS.
- cuML: a GPU-accelerated library of machine learning algorithms including Singular Value Decomposition (SVD), Principal Component Analysis (PCA), Density-based Spatial Clustering of Applications with Noise (DBSCAN).
- ml-prims: A library of low-level math and computational primitives used by cuML.
Getting RAPIDS
RAPIDS source code is available on GitHub, and a container is available on NVIDIA GPU Cloud (NGC) and Docker Hub. Let’s quickly walk through getting the container and running it and accessing the mortgage risk analysis workflow notebook.
A complete, ready-to-run docker container image is available on the RAPIDS Docker Hub container registry, making it easy to get started with RAPIDS. Pull the latest RAPIDS container image by running the following command:
$ docker pull nvcr.io/nvidia/rapidsai/rapidsai:latest
You can verify that you have the image with the docker images command:
$ docker images | grep rapids rapids/rapidsai latest 4b30dcd9849c 2 days ago 8.51GB
Run the RAPIDS container
The container can either automatically launch a jupyter notebook or you can start the container in terminal mode by adding bash at the end of the docker command. Let’s launch the notebook.
$ docker run --runtime=nvidia \ --rm -it \ -p 8888:8888 \ -p 8787:8787 \ -p 8786:8786 \ nvcr.io/nvidia/rapidsai/rapidsai:latest
You will see a bash terminal prompt, where you can activate the conda environment with the following command:
root@0038283a49ef:/# cd rapids && source activate gdf (gdf) root@0038283a49ef:/rapids#
After running it, note the prompt has (gdf) prepended to indicate the activated conda environment. Next, you need to decompress the provided data with <code>tar -xzvf data/mortgat/tar.gz which results in the following:
(gdf) root@0038283a49ef:/rapids# tar -xzvf data/mortgage.tar.gz mortgage/ mortgage/acq/ mortgage/acq/Acquisition_2000Q1.txt mortgage/acq/Acquisition_2001Q4.txt mortgage/acq/Acquisition_2001Q2.txt mortgage/acq/Acquisition_2000Q4.txt mortgage/acq/Acquisition_2000Q3.txt mortgage/acq/Acquisition_2000Q2.txt mortgage/acq/Acquisition_2001Q1.txt mortgage/acq/Acquisition_2001Q3.txt mortgage/perf/ mortgage/perf/Performance_2001Q2.txt_0 mortgage/perf/Performance_2001Q4.txt_0 mortgage/perf/Performance_2001Q4.txt_1 mortgage/perf/Performance_2001Q3.txt_1” mortgage/perf/Performance_2000Q1.txt mortgage/perf/Performance_2001Q1.txt mortgage/perf/Performance_2000Q4.txt mortgage/perf/Performance_2000Q3.txt mortgage/perf/Performance_2000Q2.txt mortgage/perf/Performance_2001Q3.txt_0 mortgage/perf/Performance_2001Q2.txt_1 mortgage/names.csv
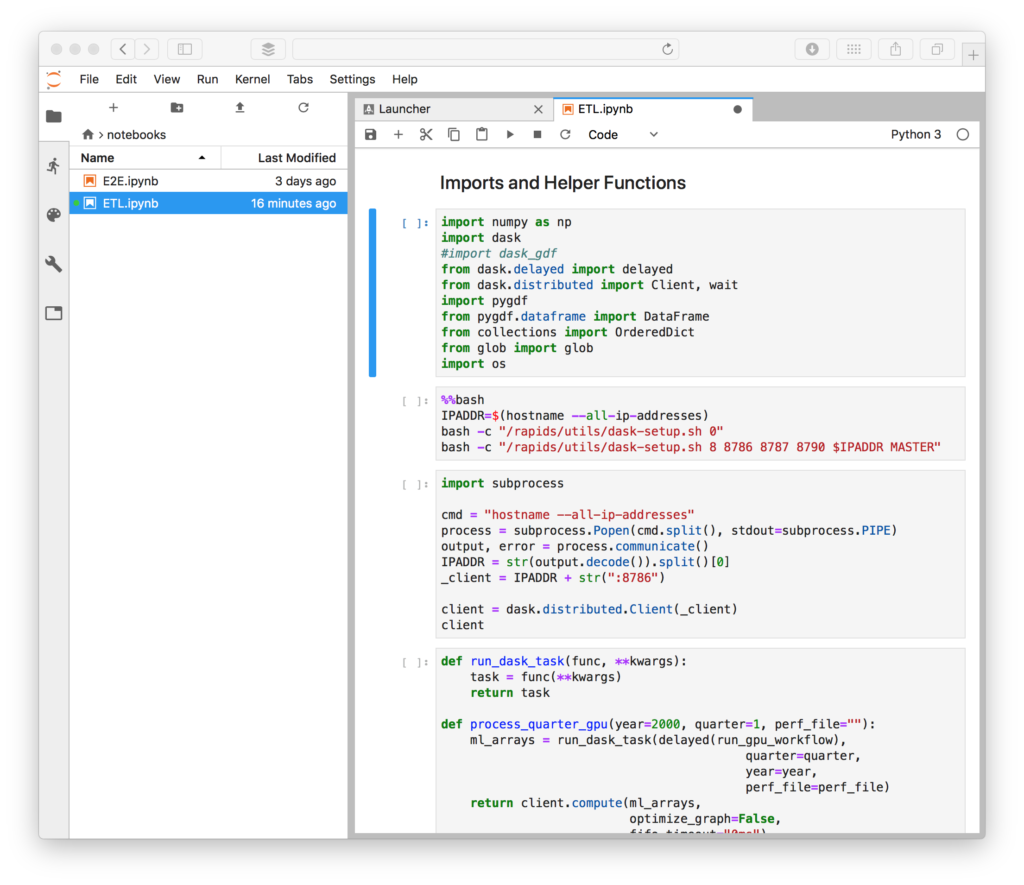
Now you can start the Jupyter notebook server, which you can access from the following URL in your browser: {IPADDR}:8888 (e.g.) 12.34.567.89:8888, where IPADDR is the address of the machine running Docker. Where it says “password or token”, enter “rapids”. You will find a couple of example notebooks in the notebook folder that will run end-to-end ETL and machine learning on the provided data. Figure 5 shows the ETL notebook running. From here you can run and edit the cells in the notebook (Shift+Enter) and see the output of running them.
We’ll walk through the details of the example in detail in a future post to demonstrate the Python APIs and RAPIDS capabilities.
Note that you are free to modify the above to experiment with your own data. For example, you can launch an interactive session with your own data mapped into the container:
docker run --runtime=nvidia \ --rm -it \ -p 8888:8888 \ -p 8787:8787 \ -v /path/to/host/data:/rapids/my_data nvcr.io/nvidia/rapidsai/rapidsai:latest
This will map data from your host operating system to the container OS in the /rapids/my_data directory. You may need to modify the provided notebooks for the new data paths.
You can get interactive documentation on Python functions in the notebook using the ? prefix on the function name, such as ?pygdf.read_csv. This will print the documentation string for PyGDF’s read_csv function. Check out the RAPIDS documentation for more detailed information, and see the NVIDIA GPU Cloud container registry for more instructions on using the container.
Conclusion
RAPIDS accelerates the complete data science pipeline from data ingestion and manipulation to machine learning training. It does this by:
- Adopting the GPU DataFrame as the common data format across all GPU-accelerated libraries
- Accelerating data science building blocks such as data manipulation routines offered by pandas, and machine learning algorithms such as XGboost by processing data and retaining the results in the GPU memory.
RAPIDS is now available as a container image on NVIDIA GPU Cloud (NGC) and Docker Hub for use on-premises or on public cloud services such as AWS, Azure, and GCP. The RAPIDS source code is also available on GitHub. Visit the RAPIDS site for more information. If you have questions, comments or feedback please use the comments section below.