NVIDIA introduces FLIP: A Difference Evaluator for Alternating Images, published as an HPG 2020 research paper.
Image quality measures are becoming increasingly important in the field of computer graphics. For example, there is currently a major focus on generating photorealistic images in real time by combining path tracing with denoising, for which such quality assessment is integral. We present FLIP, which is a difference evaluator with a particular focus on the differences between rendered images and corresponding ground truths.
The algorithm produces a map that approximates the difference perceived by humans when alternating between two images.
FLIP is a combination of modified existing building blocks, and the net result is surprisingly powerful. We have compared our work against a wide range of existing image difference algorithms and we have visually inspected over a thousand image pairs that were either retrieved from image databases or generated in-house.
Evaluating the Perceived Differences Between Images
Imagine that you are tasked with the problem of identifying and assessing the severity of each perceivable difference between two images, on a per-pixel basis. One approach to doing this is to put the images next to each other and compare them by moving your gaze between the two. However, in this process, it is likely that details are either overlooked or forgotten as you look from one image to the next. A more accurate method would be to alternate, or flip, between the images as they are placed on top of each other. This reveals differences much more distinctly than the previous approach. Therefore, this is the preferred practice for the majority of graphics researchers and practitioners when they wish to compare algorithms. Still, on a per-pixel basis, this manual difference identification and severity assessment is time-consuming and infeasible on a larger scale.
FLIP is a novel algorithm that automates the difference evaluation between alternating images and is targeted to act as an aid in graphics research. It is built on principles of human perception and incorporates dependencies on viewing distance and monitor pixel size.
This implies, for example, that if you’re observing a checkerboard from a long distance and it appears uniformly gray, this is how FLIP will perceive it as well. If the checkerboard is then compared to an inverted version of it, FLIP will report no difference, as none can be perceived.
In addition to the analysis and adoption of existing perception research, the development of FLIP was focused primarily on the examination of the difference maps it produced. The goal was to produce difference maps, or error maps in the case when distorted images are compared to higher quality versions, that agree with the difference the observer perceives while alternating between the images, both in terms of where the differences are seen and also how large the differences are. Critically, this goal is unlike any of the previous metrics, including common ones such as SSIM and LPIPS, whose error maps were seldom analyzed during development.

“While some other algorithms also incorporate principles of human vision, FLIP’s significant focus on the error map itself is what sets it apart from other methods,” says Pontus Andersson, co-author of the paper
“FLIP: A Difference Evaluator for Alternating Images.”
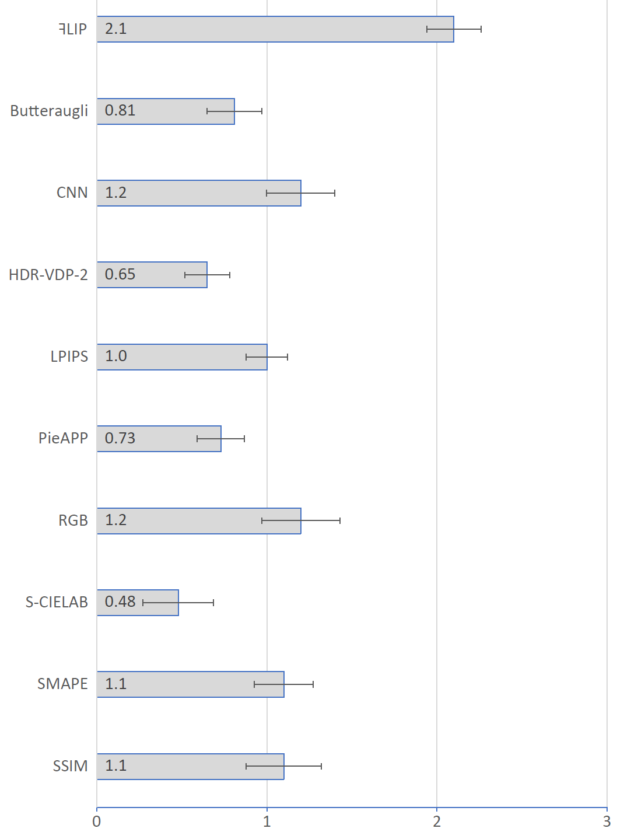
“This was solidified by our user study, where subjects were asked to rate several metrics’ error maps based on how well the maps corresponded with the errors they perceived while alternating between two images,” says Andersson.
With the key role image quality metrics have in the development and evaluation of graphics algorithms, it is important that they reliably generate results that agree with human perception.
“Before FLIP, as shown in the paper, this was seldom the case. It is our hope that, with FLIP’s proven agreement with perceived errors, it will be adopted and become a precursor in the development of more perceptually-aligned metrics that can further improve the perceived quality of the imagery our industry produces,” says Jim Nilsson, co-creator of FLIP.
To facilitate the use of FLIP, we provide source code in C++, MATLAB, NumPy/SciPy, and PyTorch.
