
Video quality metrics are used to evaluate the fidelity of video content. They provide a consistent quantitative measurement to assess the performance of the encoder.
- Peak signal-to-noise ratio (PSNR): A long-established quality metric that compares the pixel values of the reference image to a degraded one.
- Structural similarity index measure (SSIM): Compares luminance, contrast, and structure of the degraded image to the original one.
- Video Multi-Method Assessment Fusion (VMAF): Introduced by Netflix, this metric attempts to accurately capture human visual perception.
VMAF combines human vision modeling with machine learning techniques that are continuously evolving, enabling it to adapt to new content. VMAF excels in aligning with human visual perception by combining detailed analysis of video quality factors with human vision modeling and advanced machine learning.
This post showcases how CUDA-accelerated VMAF (VMAF-CUDA) enables VMAF scores to be calculated on NVIDIA GPUs. VMAF image feature extractors are ported to CUDA, enabling it to consume images that are decoded using the NVIDIA Video Codec SDK. We observed up to a 4.4x speedup in throughput in the open-source tool FFmpeg and up to 37x lower latency at 4K. The acceleration is now officially a part of VMAF 3.0 and FFmpeg v6.1.
The VMAF-CUDA implementation was the result of a successful open-source collaboration between NVIDIA and Netflix. The results of this collaboration are an extended libvmaf API with GPU support, libvmaf CUDA feature extractors, as well as an accompanying upstream FFmpeg filter, libvmaf_cuda. VMAF-CUDA must be built from the source. Use the Dockerfile.cuda container as a reference for all required libraries and steps.
VMAF key elementary metrics
VMAF evaluates video quality using key elementary metrics from a reference and a distorted image:
- Visual information fidelity (VIF): Quantifies the preservation of original content, reflecting perceived information loss.
- Additive distortion measurement (ADM): Assesses structural changes and texture degradation. It is notably sensitive to additive distortions such as noise.
- Motion features: Crucial for appraising motion-rendering quality in dynamic scenes.
These metrics are used as input features for a support vector machine (SVM) regressor, which integrates them to calculate the final VMAF score. This approach ensures a comprehensive and precise representation of video quality, as perceived by viewers.
Feature extractors such as VIF and ADM do not require any prior information. They only require a reference frame and a distorted frame as input. Unlike the other two, the extraction of motion features also requires information from previous motion feature extractor iterations (inter-frame dependency).
VMAF implementation on GPU vs. CPU
The CPU implementation of VMAF can distribute the computation of the above features over multiple threads for each image. Therefore, the VMAF calculation profits from a higher number of CPU cores. The computation of the VMAF score on the CPU implementation is dependent on the slowest feature that must be extracted (Figure 1).
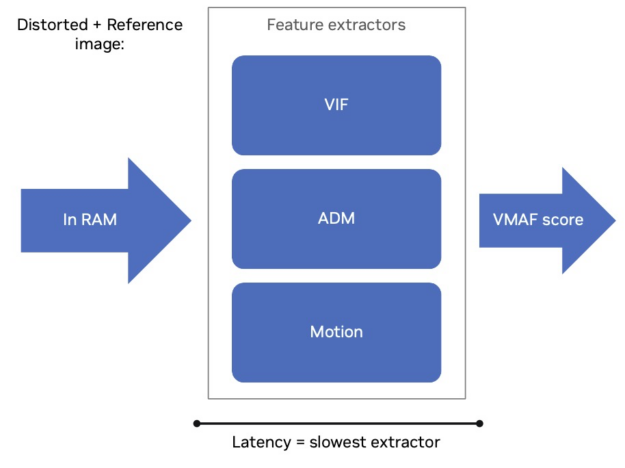
Also, the motion feature score calculation has temporal dependencies and therefore cannot be multi-threaded. So, the VMAF score latency per frame is independent of the number of threads that can be used. Performance profiling has shown that VIF generally requires more time to compute, making it the limiting feature extractor. Nonetheless, a higher number of threads increases the VMAF throughput in frames per second (FPS).
VMAF was recently ported to run on CUDA using NVIDIA GPUs. VMAF-CUDA requires the CUDA Toolkit to compile but does not need any additional libraries for deployment apart from the GPU driver.
VMAF-CUDA uses a different approach when compared to the CPU implementation. Rather than allocating parts of the GPU compute resources for specific feature extractors to compute them concurrently, the CUDA implementation allocates the entire GPU compute resources for each feature and calculates them sequentially (Figure 2).
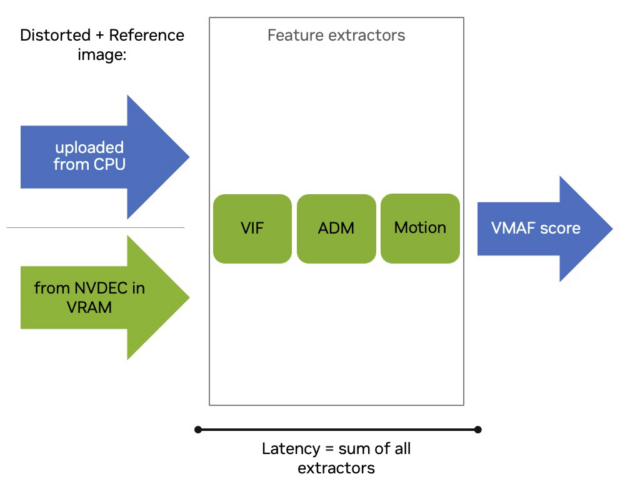
This results in the faster computation of each feature and makes the VMAF score latency now dependent on the sum of all feature extractors. The CUDA implementation accelerates the feature extractors and is compatible with different VMAF functionalities, such as support for VMAF models VMAF 4K and VMAF NEG.
VMAF-CUDA can be a drop-in replacement for an existing pipeline that uses the VMAF-CPU. If the images are in CPU RAM, they are promptly uploaded to the GPU. The entire GPU implementation consists of feature extractor compute and memory transfers to and from the GPU. It works asynchronously relative to the CPU.
NVIDIA also used VMAF-CUDA as an opportunity to accelerate PSNR calculations. VMAF and PSNR are usually calculated concurrently. Our research pointed to PSNR as the bottleneck if it is run on the CPU along VMAF-CUDA as it requires fetching the decoded image from GPU memory through the PCIe Bus. The PCIe transfer hurts performance significantly due to its limited speed. For this purpose, PSNR can also be calculated on the GPU using the CUDA-accelerated PSNR #1175 patch.
Advantages of VMAF-CUDA
VMAF-CUDA can be used during encoding. NVIDIA GPUs can run compute workloads on GPU cores independent of NVENC and NVDEC. NVENC can consume the raw video frame while NVDEC decodes the output frame into video memory. This implies that both the reference frame and the distorted frame stay in video memory and can be input into VMAF-CUDA (Figure 2). Therefore, VMAF can be computed during the encoding because NVENC does not require the GPU compute resources.
It also can be used during transcoding for quality monitoring. When transcoding an H.264 bitstream to H.265, NVDEC decodes the input bitstream and writes its frame to the GPU VRAM (reference frame). This reference frame is encoded to H.265 using NVENC, which can be directly decoded resulting in the distorted frame. This process leaves compute resources idle while transcoding on the GPU and keeping the data in GPU memory. VMAF-CUDA can use these idle resources and calculate a score without interrupting transcoding and no additional memory transfers. This makes it a cost-effective option compared to the CPU implementation.
VMAF-CUDA is fully integrated with FFmpeg v6.1 and supports GPU frames for hardware-accelerated decoding. FFmpeg is an industry-standard, open-source tool that handles multi-media files and video streams. After building VMAF and FFmpeg from the source, only the latest NVIDIA GPU driver is required for execution and you don’t require any prior knowledge of CUDA.
The usage in a Docker container makes dependency handling and compilation a convenient and portable process. VMAF-CUDA in FFmpeg executes on the GPU asynchronously relative to the CPU, freeing it up to do additional tasks.
Evaluation
There are two metrics we measured with VMAF-CUDA:
- VMAF per frame latency: The time required to compute the three feature extractors to obtain a VMAF score for a single frame reflecting responsiveness.
- Total throughput: How quickly the VMAF score for a video sequence can be computed.
The hardware used for this measurement was a 56C/112T Dual Intel Xeon 8480 compute node and a single NVIDIA L4 GPU.
VMAF latency improvements
The feature extractor latencies on a frame basis were measured using NVIDIA Tools Extension (NVTX) ranges placed inside the VMAF library (libvmaf) and a Nsight Systems trace was captured using the VMAF tool included in the VMAF GitHub repository.
Latency in this case is the time required to compute the three feature extractors to get a VMAF score for a single frame. NVTX enables you to measure the runtime of functions or operations on CPUs and GPUs. In the measurements, both the CPU and GPU feature extractors run independently for 4K and 1080p test sequences.
The hardware used for this measurement was a 56C/112T Dual Intel Xeon 8480 compute node and an NVIDIA L4 GPU. The measurements showed a 30–90x speedup in feature extractor latencies for one image on the NVIDIA L4 over the Intel Xeon 8480 CPUs (Figure 3).
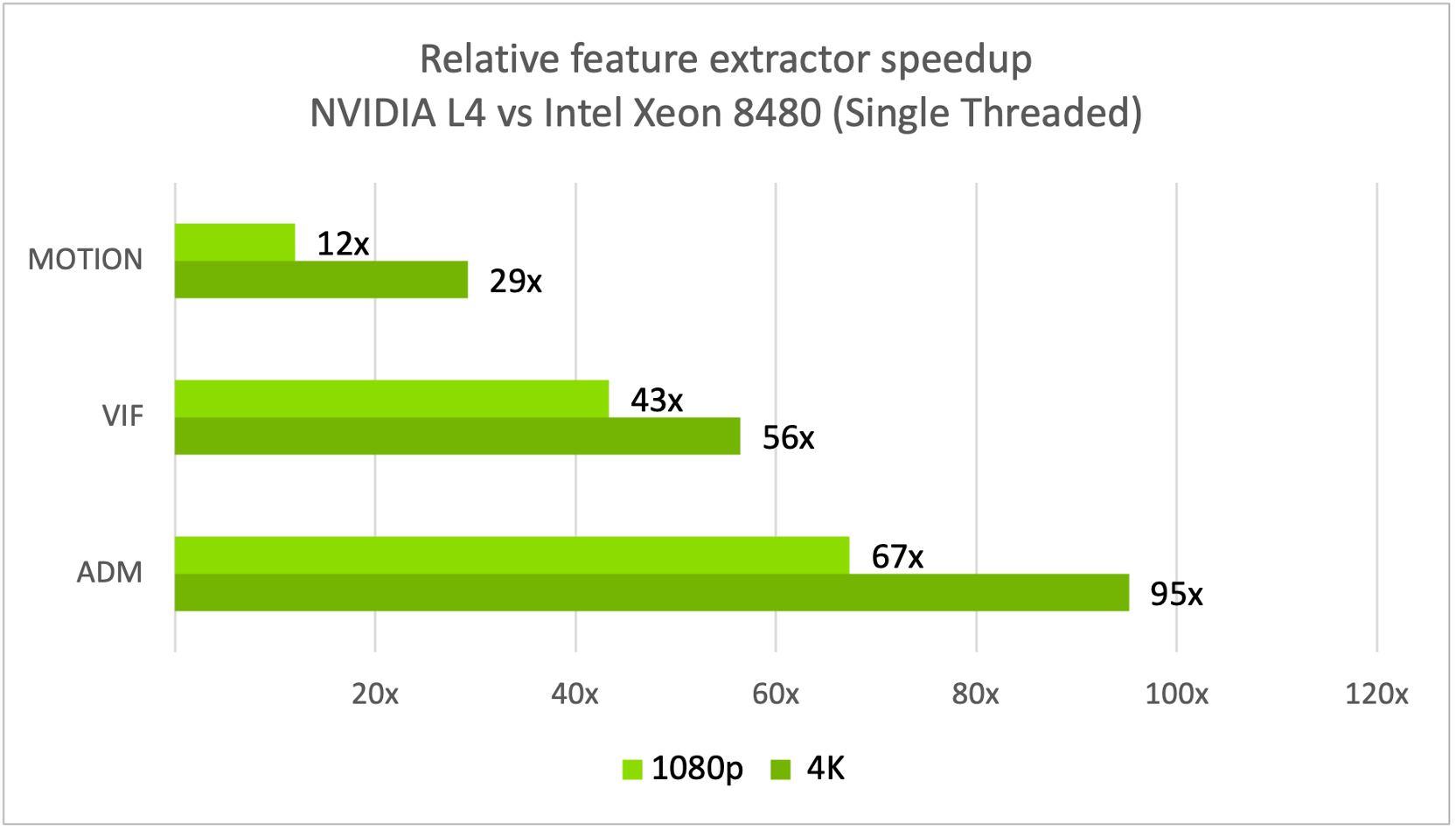
At lower resolutions like 1080p VMAF-CUDA does not saturate a single NVIDIA L4, which is why you see even better latency improvements compared to VMAF-CPU on higher resolutions like 4K.
Figure 4 shows the average VMAF score access latency.
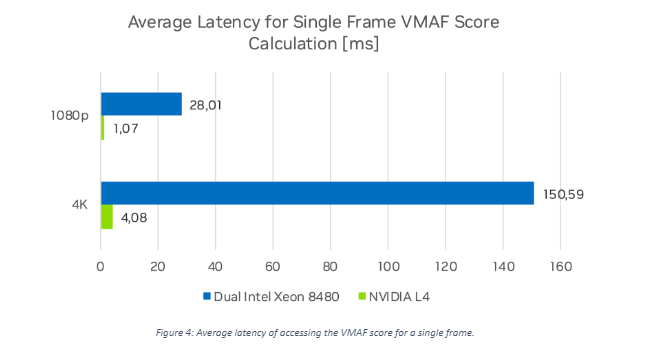
The NVIDIA L4 GPU latency time is the sum of the average runtime of each feature extractor as they run sequentially on the GPU. The average latency for the Dual Intel Xeon compute node is determined by the slowest feature extractors as they run in parallel on multiple cores. VMAF-CUDA is 36.9x faster at 4K and 26.1x faster at 1080p when accessing the VMAF score of a single frame than the Dual Intel Xeon 8480.
FFmpeg performance improvement
We measured the throughput (FPS) by calculating VMAF in FFmpeg. FFmpeg enables the encoded video to be read into GPU or CPU RAM directly instead of reading the raw byte streams from disk, as the VMAF tool does. We used the libvmaf_cuda video filter for the GPU implementation and the libvmaf video filter for the CPU implementation. For input, we used YUV420 8-bit per channel, 4K, and 1080p HEVC encoded test sequences as input.
The following FFmpeg command calculates the VMAF score using the GPU implementation:
ffmpeg -hwaccel cuda -hwaccel_output_format cuda -i distorted.mp4 -hwaccel cuda -hwaccel_output_format cuda -i reference.mp4 -filter_complex "[0:v]scale_npp=format=yuv420p[dis],[1:v]scale_npp=format=yuv420p[ref],[dis][ref]libvmaf_cuda" -f null –
-hwaccel cuda -hwaccel_output_format cuda: Enables CUDA for hardware-accelerated video frames. The video is decoded on the GPU using NVDEC and output to GPU VRAM. This is crucial for high throughput to prevent it from being limited by memory transfers from the CPU.-filter_complex: Starts a complex filter that describes a video processing pipeline. Each step is a video filter that is comma-separated and starts with the inputs in square brackets.[0:v]scale_npp=format=yuv420p[dis]: Takes the first input video (distorted.mp4), here0:v, and formats it toyuv420usingscale_npp, so that it is compatible with VMAF. VMAF supports YUV420, YUV422, and YUV444 in 8–, 10–, or 12-bit, but NVDEC outputs YUV420 as NV12, which requires this reformat. Finally, it stores the result in a variable:dis. The same goes for the reference input video (reference.mp4), here1:v, and stores it inref.[dis][ref]libvmaf_cuda: Takes the outputdisandreffrom the previous filters and inputs it into thelibvmaf_cudavideo filter that calculates the VMAF score for both input videos. Contrary to other metrics, the order of inputs here is important, as the metric is not symmetric.
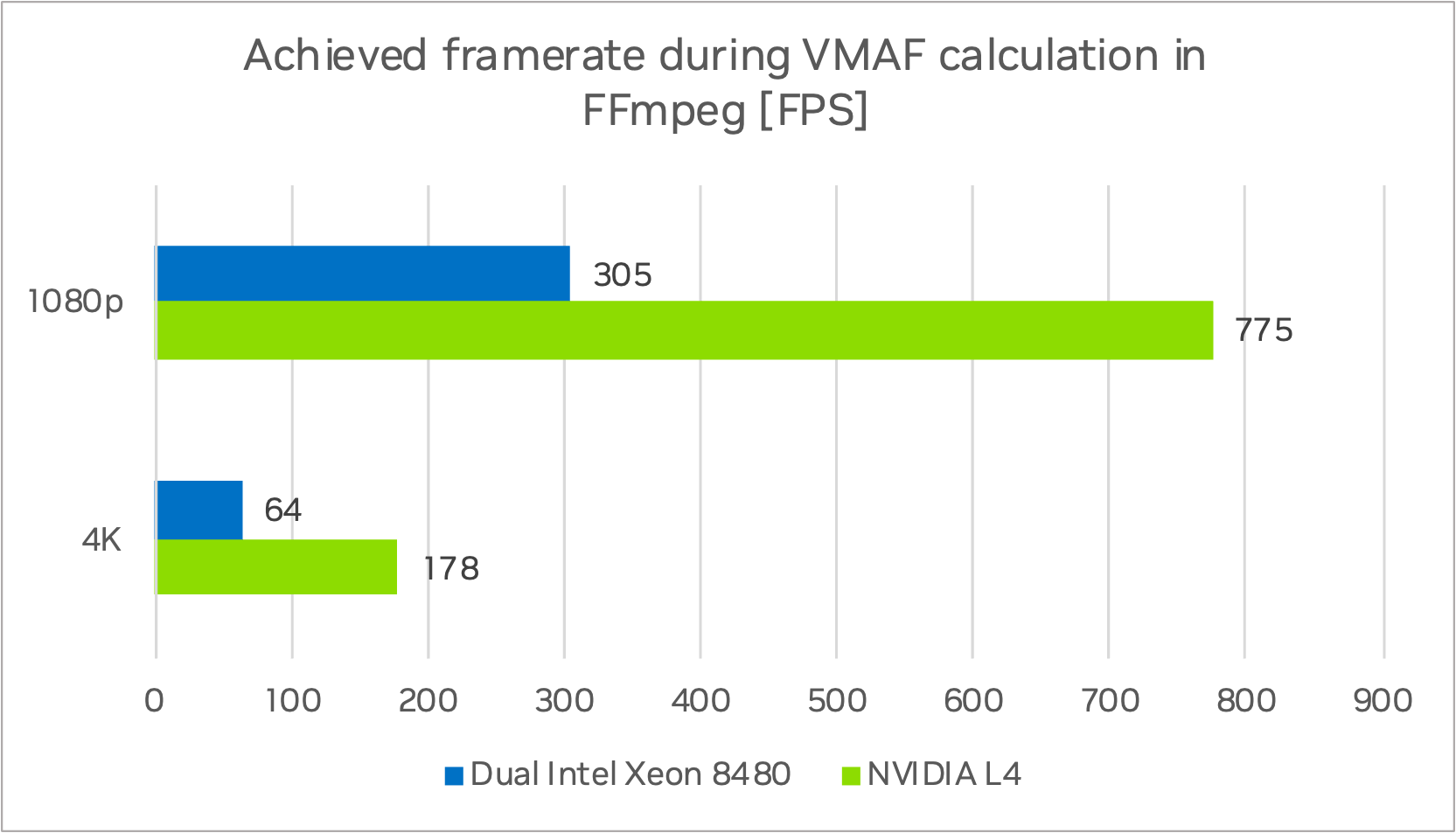
The NVIDIA L4 achieved 178 FPS at 4K and 775 FPS in 1080p while the Dual Intel Xeon 8480 compute node reached 64 FPS for 4K and 176 FPS for 1080p (Figure 5). This is a speedup of 2.8x for the 4K sequence and 2.5x for 1080p when processing a single video stream.
Dollar-cost analysis
For the cost analysis, we based our calculations on a standard 2U server typically found in data centers.
The NVIDIA L4 is designed with a single-slot low-profile form factor allowing for eight NVIDIA L4 units to be housed within a 2U server with cheaper Intel Xeon or AMD Rome processors. A single process/instance of FFmpeg cannot saturate the Dual Intel Xeon 8480 compute node during VMAF computation while the NVIDIA L4 was at 100% usage.
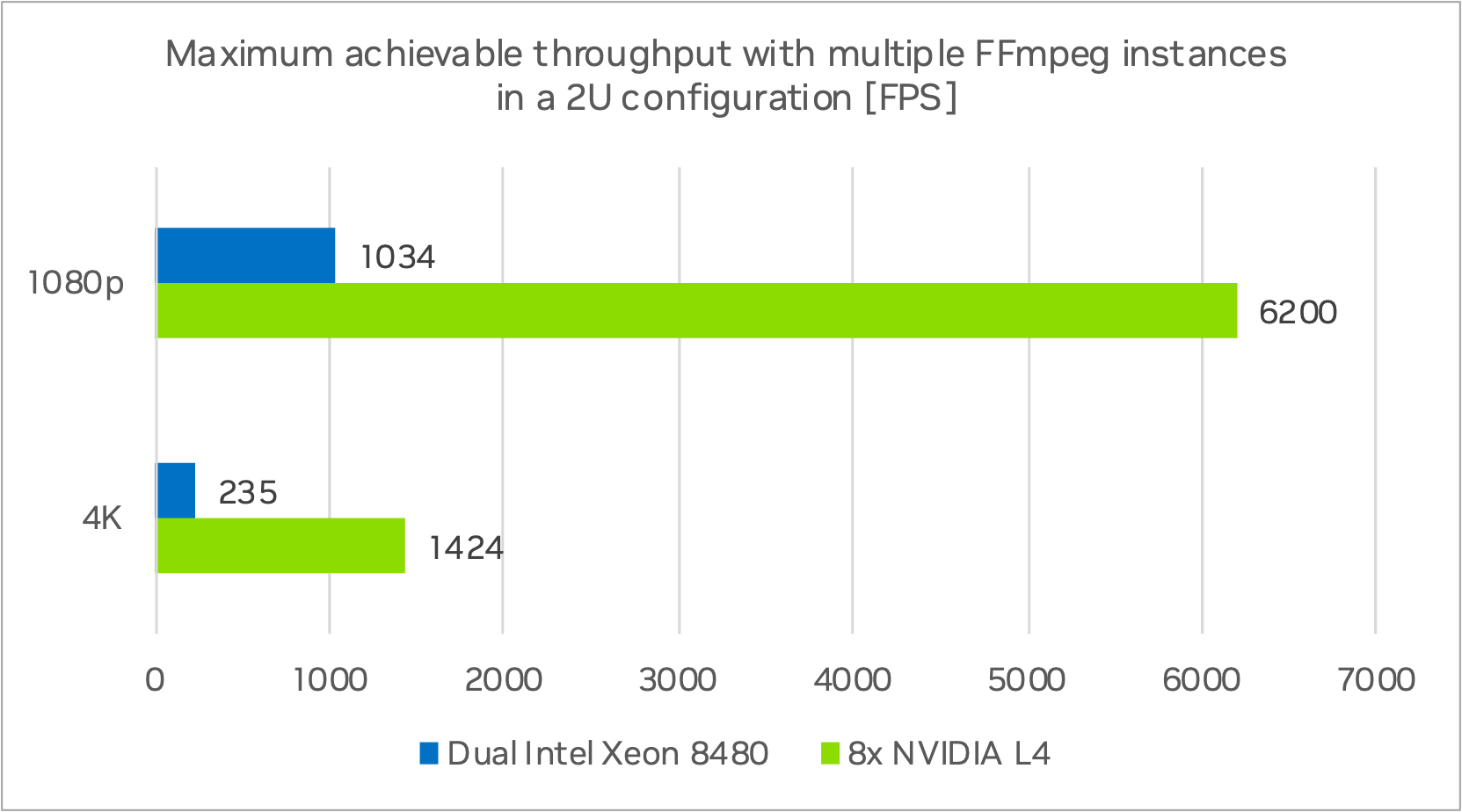
Figure 6 shows the results of a test based on the total compute performance of a 2U Dual Intel Xeon system conducted with multiple processes of FFmpeg to fully saturate the CPUs. The FPS numbers for a 2U eight L4 server are shown as well.
Multiple instances of FFmpeg on Dual Intel Xeon 8480 and eight NVIDIA L4
The Dual Intel Platinum 8480 node has a total throughput of 1034 FPS at 1080p and 235 FPS at 4K with multiple FFmpeg instances/processes. The 2U server system with eight NVIDIA L4 GPUs reached a total throughput of 6200 FPS at 1080p and 1424 FPS at 4K. This is a speedup of ~6x for 1080p and 4K at the same power draw level.
The following table breaks down the cost per VMAF frame for a 2U server.
| NVIDIA L4 | Dual Intel Platinum 84801 | |
| 1000 hours of 4K at 30 FPS | 108M frames | 108M frames |
| Server Type | 2U | 2U |
| # of processors | 8 | 2 |
| Max total throughput | 1424 FPS | 235 FPS |
| Time to calculate VMAF scores | 21.0 hrs | 127.6 hrs |
| 3-year TCO | $30K | $20K |
| Cost to calculate VMAF for 1000 hrs of 4K video at 30 FPS | $24 | $97 |
1CPU-only server (2U chassis, Dual Intel Platinum 8480, 512GB RAM, 1TB SSD, NIC) | L4 server (2U chassis, 2S 32C CPU, 128GB RAM, 1TB SSD, CX6 NIC)
When comparing the eight NVIDIA L4 to the Dual Intel Xeon 8480, the NVIDIA system provides cost savings of up to 75%.
Partner success stories
We want to showcase some of the achievements and experiences of our partners, highlighting their accomplishments using VMAF-CUDA and NVIDIA GPUs in their software and video processing pipelines. The valuable feedback provided by Snap, as a beta tester, significantly contributed to the development of VMAF-CUDA.
Snap
Snap tracks video quality metrics over time, which includes CUDA-accelerated VMAF to ensure that transcode quality is consistent per variant.
They are currently using VMAF-CUDA for Snapchat Memories to determine if a particular encode meets the quality threshold and re-transcode if required. The introduction of VMAF-CUDA has optimized the processing pipeline. Previously, the high computational costs of VMAF calculations deterred Snap from using optimal transcode settings. However, thanks to VMAF-CUDA, they can evaluate Snapchat Memories after each transcode and re-encode with optimized settings with little overhead.
Snap generally observed a 2.5x speedup in processing time, attributing this improvement to the ability to run VMAF calculations exclusively on the GPU. This shift has made it far more cost-effective to run VMAF compared to the CPU-based methods. Snap is using Amazon EC2 g4dn.2xlarge instances with T4 GPUs for its VMAF calculations.
CUDA accelerated VMAF makes previously unfeasible projects possible for Snap. Snap is looking to expand its use of VMAF-CUDA to other applications and completely transition from CPU-based to GPU-based VMAF computations.
V-Nova
V-Nova is exploring the benefits of CUDA-accelerated VMAF calculation for several use cases. These include its usefulness in both offline metric calculation and real-time decision-making within the LCEVC (MPEG-5 Part 2) encoding process. The integration of VMAF-CUDA can significantly accelerate offline metric calculations.
V-Nova’s video quality tools, including Video Quality Framework and Parallel Performance Runner (PAPER), processed approximately 20K encoding jobs weekly in 2023. VMAF-CUDA has demonstrated the ability to speed up metric calculation by at least 2x.
Looking ahead to the medium and long term, the real-time, in-loop VMAF calculation facilitated by VMAF-CUDA could offer additional benefits for algorithmic enhancements, such as optimizing LCEVC mode decisions and rate control for this metric.
More resources
For more information about VMAF and related topics such as VMAF hacking, see the following resources. Be sure to attend our NVIDIA GTC 2024 session, VMAF CUDA: Running at Transcode Speed.
