To help people who suffer from hearing loss, Researchers from Columbia University just developed a deep learning-based system that can help amplify specific speakers in a group, a breakthrough that could lead to better hearing aids.
“The brain area that processes sound is extraordinarily sensitive and powerful; it can amplify one voice over others, seemingly effortlessly, while today’s hearings aids still pale in comparison,” said Nima Mesgarani, PhD, a principal investigator at Columbia’s Mortimer B. Zuckerman Mind Brain Behavior Institute.
Mesgarani and his team just published a new paper in the May 15 issue of Science Advances describing the technique.
“By creating a device that harnesses the power of the brain itself, we hope our work will lead to technological improvements that enable the hundreds of millions of hearing-impaired people worldwide to communicate just as easily as their friends and family do,” Masgarani said.
Using NVIDIA TITAN Xp GPUs, with CUDA, and the cuDNN-accelerated PyTorch deep learning framework, the team trained a deep neural network on dataset containing over 30 hours of voice, to automatically separate speech from speakers in mixed audio.
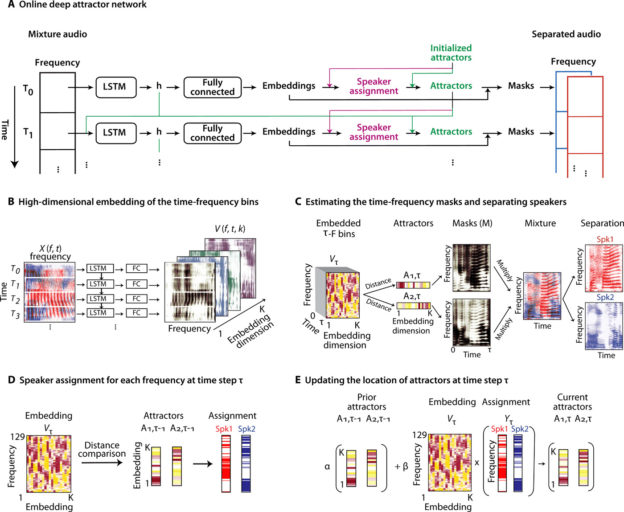
“The neural network that embeds consists of a four-layer long short-term memory (LSTM) network, followed by a fully connected layer (FC),” the team explained in their paper.
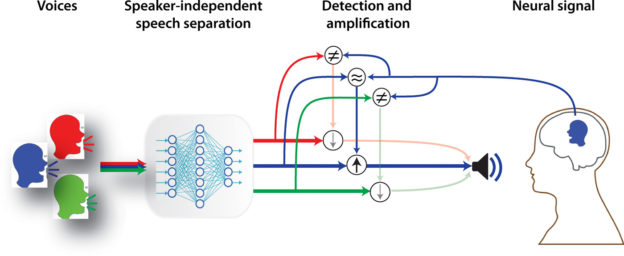
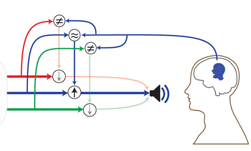
To test the feasibility of using the algorithm as a speech separation network in a brain-controlled hearing device, the team used data from three neurosurgical patients undergoing treatment for epilepsy.
“Although we used invasive neural recordings to test our system, previous research has already shown that attention decoding is also possible with noninvasive neural recordings, including scalp EEG with different or the same gender mixtures, around the ear EEG electrodes, and in-ear EEG recordings,” the team said.
For inference, in this case performing speaker-independent speech separation, as well as detection and amplification, the team relied on NVIDIA Tesla GPUs.
The work represents a feasible solution for creating a brain-controlled hearing device, a device that has the potential to help hearing-impaired patients more easily communicate in crowded spaces.
