To help people with speech impairments better interact with every-day smart devices, Google researchers have developed a deep learning-based automatic speech recognition (ASR) system that aims to improve communications for people with amyotrophic lateral sclerosis (ALS), a disease that can affect a person’s speech.
The research, part of Project Euphoria, is an ASR platform that performs speech-to-text transcription.
“This work presents an approach to improve ASR for people with ALS that may also be applicable to many other types of non-standard speech,” the Google researchers stated in a blog post.
The approach relies on a high-quality ASR model trained on thousands of hours of standard speech taken from YouTube videos, fine-tuned for individuals with non-standard speech using four NVIDIA V100 GPUs, with the cuDNN-accelerated TensorFlow deep learning framework. For the finetuning, the team collected a dataset of voice recordings from ALS patients at the ALS Therapy Development Institute.
“Using a two-step training approach that starts with a baseline “standard” corpus and then fine-tunes the training with a personalized speech dataset, we have demonstrated significant improvements for speakers with atypical speech over current state-of-the-art models,” the Google team said.
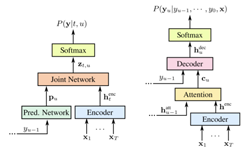
In developing their model, the team explored two neural architectures, an RNN-Transducer (RNN-T) architecture, and a Listen, Attend, and Spell (LAS) architecture.
For the RNN-T network, the model is based on an encoder and decoder network, which is bi-directional and requires the entire audio sample to perform speech recognition.
For the second model, LAS, an attention-based, sequence-to-sequence model, the model produces word pieces that are a linguistic representation between words.
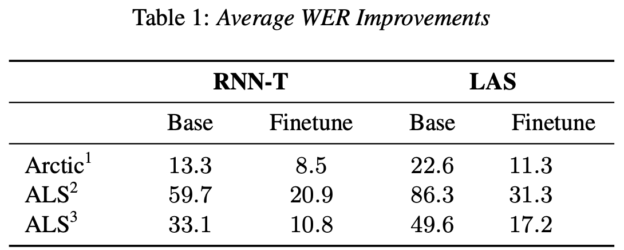
“The relative difference between the base model and the fine-tuned model demonstrates that the majority of the improvement comes from the fine-tuning process,” the researchers stated. “We hope that continued research in this area will help voice interfaces become accessible to more people, especially those who need it most.”
The researchers will present their work next month at the Interspeech 2019 Conference.
The Google team has published a blog and released a paper about the work.
