
Researchers at MIT and Stanford University developed a deep learning system that can process sounds just like humans. The method, which is the first model of its kind, can replicate listening tasks such as identifying a musical genre or identifying words.
The researchers built the model to shed light on how the human brain may be performing listening tasks. The results suggest there may be a hierarchical organization in the human auditory cortex, the researchers said.
“Perhaps the most significant departure from previous auditory models is that our model performs real-world tasks on par with human listeners,” the researchers wrote in their research paper. “Achieving human performance on everyday perceptual tasks was unheard of until just a few years ago but is now attainable in an increasing number of domains due to the efficacy of deep learning.”
Using NVIDIA TITAN X GPUs with the cuDNN-accelerated TensorFlow deep learning framework, the team trained their neural networks on over 180,000 labeled songs, and more than 165 natural sounds such as an alarm clock, basketballs dribbling, applause, flushing, and even the sound of walking on heels. The team also trained the system to recognize over 500 words for the speech recognition task.
Once trained, the system used the same NVIDIA GPUs used for training to complete two tasks — identify words positioned at the midpoint of a two-second excerpt, and to identify 41 musical genres by only listening to a two-second music clip. To make the tasks more challenging and realistic, the researchers superimposed over 165 natural sounds during the different tests to emulate a real-world experience.
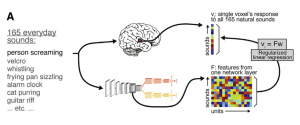
“The idea is over time the model gets better and better at the task,” Alexander Kell, an MIT graduate student and one of the lead authors, told the MIT News. “The hope is that it’s learning something general, so if you present a new sound that the model has never heard before, it will do well, and in practice that is often the case.”
The team says they will focus on training their network on additional music-related tasks, or tasks not specific to speech or music to yield a better picture of human behavior.
Read more >
AI-Generated Summary
- Researchers at MIT and Stanford University developed a deep learning system that can process sounds like humans, replicating tasks such as identifying musical genres or words.
- The model was trained on over 180,000 labeled songs and more than 165 natural sounds using NVIDIA TITAN X GPUs and the cuDNN-accelerated TensorFlow framework.
- The system was able to identify words and musical genres with high accuracy, even when tested with superimposed natural sounds to simulate real-world conditions.
AI-generated content may summarize information incompletely. Verify important information. Learn more