Researchers from Columbia University used deep learning to enhance speech neuroprosthesis technologies, that can result in accurate and intelligible reconstructed speech from the human auditory cortex.
This research has the potential to one day help patients who have lost their ability to speak, communicate with their loved ones.
“Our approach takes a step toward the next generation of human-computer interaction systems and more natural communication channels for patients suffering from paralysis and locked-in syndromes,” the researchers stated in their paper.
The findings were published this week in Scientific Reports this week.
“Our voices help connect us to our friends, family and the world around us, which is why losing the power of one’s voice due to injury or disease is so devastating,” said Nima Mesgarani, the paper’s senior author and a principal investigator at Columbia University’s Mortimer B. Zuckerman Mind Brain Behavior Institute.“With today’s study, we have a potential way to restore [voice]. We’ve shown that, with the right technology, these people’s thoughts could be decoded and understood by any listener.”
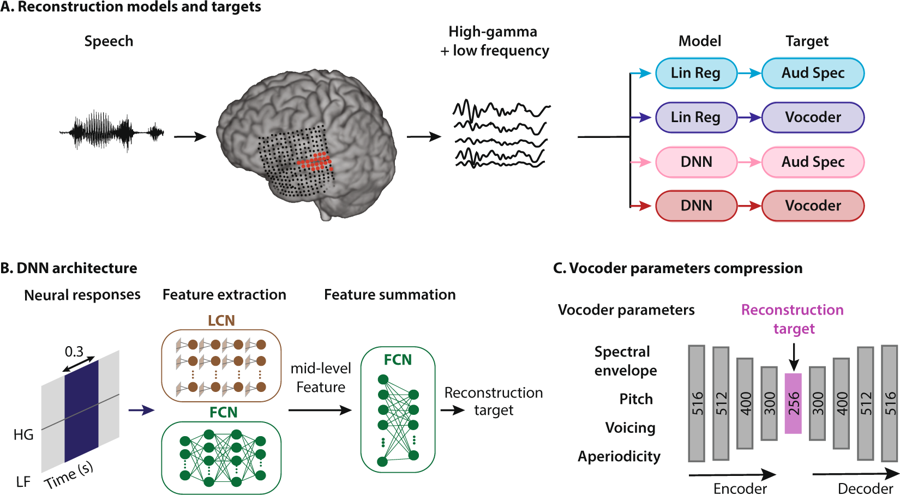
Previous research has indicated that when people speak or imagine speaking, certain patterns, neural data, appear in their brain. Other patterns also emerge when we listen to or imagine someone speaking. Reconstructing speech from these neural responses, recorded from the human auditory cortex, could one day create a direct communication pathway to the brain.
This work was done In conjunction with a neurosurgeon from Northwell Health Physician Partners Neuroscience Institute. This collaboration allowed the collection of data from patients who were already undergoing brain surgery.
Using NVIDIA TITAN and NVIDIA Tesla GPUs, with the cuDNN-accelerated TensorFlow deep learning framework, the researchers were able to develop deep learning models that made possible the production of a computer-generated voice reciting a sequence of numbers with a 75% accuracy level.
Here is an example of the computer generated sounds:
The paper is titled “Towards reconstructing intelligible speech from the human auditory cortex” and the code for performing phoneme analysis, and reconstructing the auditory spectrogram are available on the researcher’s page.
Read more>
AI Researchers Pave the Way For Translating Brain Waves Into Speech
Jan 31, 2019
Discuss (0)
AI-Generated Summary
- Researchers from Columbia University used deep learning to enhance speech neuroprosthesis technologies, potentially helping patients who have lost their ability to speak.
- Using NVIDIA TITAN and NVIDIA Tesla GPUs, the researchers developed deep learning models that reconstructed speech from neural responses recorded from the human auditory cortex with a 75% accuracy level.
- The study's findings, published in Scientific Reports, could lead to more natural communication channels for patients suffering from paralysis and locked-in syndromes, according to Nima Mesgarani.
AI-generated content may summarize information incompletely. Verify important information. Learn more