
As of March 18, 2025, NVIDIA Triton Inference Server is now part of the NVIDIA Dynamo Platform and has been renamed to NVIDIA Dynamo Triton, accordingly.
Ever spotted someone in a photo wearing a cool shirt or some unique apparel and wondered where they got it? How much did it cost? Maybe you’ve even thought about buying one for yourself.
This challenge inspired Snap’s ML engineering team to introduce Screenshop, a service within Snapchat’s app that uses AI to locate and recommend fashion items online that match the style seen in an image.

Screenshop was integrated into the Snapchat app in 2021. It was developed using an open-source object detection and image classification model fine-tuned in-house by Snap’s ML engineers. The model detects the type of clothing item that appears in an image and then passes it to a fashion embeddings model that uses similarity search to find similar-looking items in a fashion catalog.

Screenshop’s AI pipeline was initially built and served using TensorFlow, a widely used open-source framework for developing machine learning and artificial intelligence applications.
Ke Ma, an ML engineer at Snap, highlighted the role of TensorFlow in the early development process. “Screenshop’s deep learning models were initially developed using TensorFlow,” he explained. “Therefore, when the time came to select an inference serving platform, our natural choice was to use TensorFlow’s native serving platform, TFServing.”
Addressing the production challenges of a multiframework AI pipeline
As the Screenshop service gained traction among Snapchat’s user base, the ML team began exploring avenues to refine and improve the service. They quickly discovered that they could enhance the accuracy of the semantic search results by replacing their fashion embeddings model with an alternative model based on a PyTorch framework.
This situation highlighted a typical challenge faced by enterprises deploying AI models in production environments: the dilemma of deploying AI models with different backend frameworks without the need to manage, maintain, and deploy bespoke inference serving platforms for each framework. The quest for a solution led Ke Ma and his team to discover NVIDIA Triton Inference Server.
“We did not want to deploy bespoke inference serving platforms for our Screenshop pipeline, a TFserving platform for TensorFlow, and a TorchServe platform for PyTorch,” explained Ke Ma. “Triton’s framework-agnostic design and support for multiple backends like TensorFlow, PyTorch, and ONNX was very compelling. It allowed us to serve our end-to-end pipeline using a single inference serving platform, which reduces our inference serving costs and the number of developer days needed to update our models in production.”
Triton Inference Server is an open-source AI model-serving platform that streamlines and accelerates the deployment of AI inference workloads in production. It helps enterprises, ML developers, and researchers reduce the complexity of model-serving infrastructure, shorten the time needed to deploy new AI models, and increase AI inferencing and prediction capacity. It supports multiple deep learning and machine learning frameworks including NVIDIA TensorRT, TensorFlow, PyTorch, ONNX, OpenVINO, Python, RAPIDS FIL, and more.
Accelerating time to production with NVIDIA Triton Model Ensembles and Model Analyzer
The team at Snap successfully used NVIDIA Triton Model Ensembles and Model Analyzer features to expedite their migration process off TFServing and onto Triton Inference Server.
By taking advantage of Model Ensembles, a no-code development tool that connects AI models into a single pipeline, the Screenshop development team integrated the pre– and post-processing workflows, created using Python, into their pipeline without writing any code. This enabled them to trigger the entire pipeline with a single inference request. This reduced latency and minimized the back-and-forth networking communication between the different steps.

Figure 3 shows how a pipeline of pre– and post-processing steps can be built using NVIDIA Triton Model Ensemble without writing code.
The team also capitalized on the capabilities of Triton Inference Server to swiftly pinpoint the best configuration and setup for running their Screenshop pipeline, ensuring maximum throughput within their target latency of 100 ms.
A standout feature of Triton Model Analyzer enables users to experiment with various deployment configurations by adjusting the number of concurrent models loaded on the GPU and the number of requests that are batched together during inference run time. It then visually maps out these configurations on an intuitive chart, facilitating the quick identification and deployment of the most efficient setup for production use.
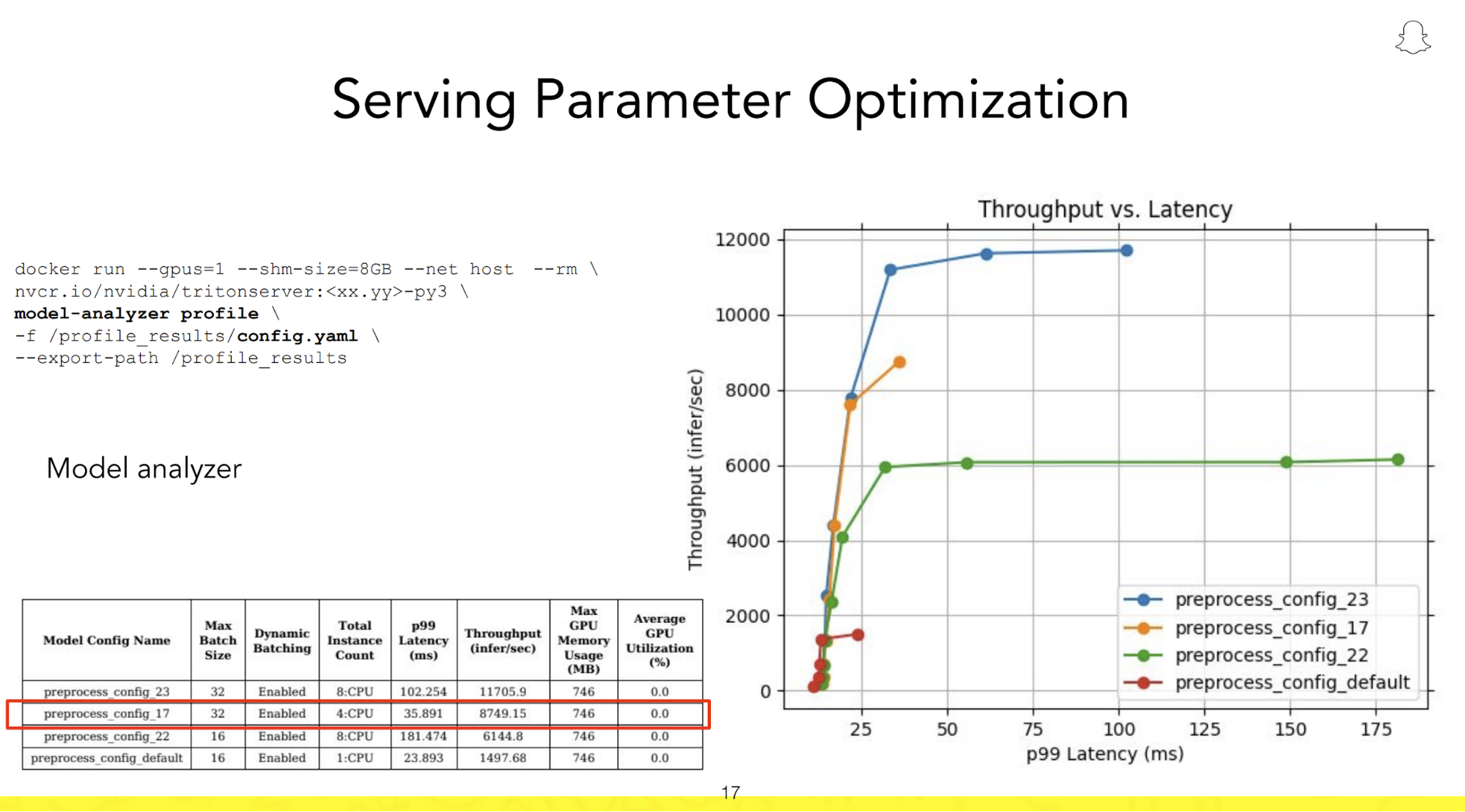
Increasing throughput by 3x and reducing cost by 66% using NVIDIA TensorRT
Following the successful launch of the Screenshop service on Triton Inference Server, Ke Ma and his team remained committed to enhancing their system’s performance and reducing the total cost of ownership. Their efforts led them to NVIDIA TensorRT, an SDK specifically aimed at optimizing inference for AI models on NVIDIA GPUs.
“Thanks to TensorRT, we managed to reduce the precision of our model from FP32 to FP16 without any impact on the quality or accuracy of the service” explained Ke Ma, referring to TensorRT’s quantization features that help reduce the number of memory bits used to represent model parameters.
The Screenshop team applied the default NVIDIA TensorRT settings during the compilation process and immediately witnessed a 3x surge in throughput estimated to deliver a 66% cost reduction, a significant figure considering the number of Snap users relying on the service.
Scaling Triton Inference Server to 1K GPUs to meet Snapchat’s growing user base
Screenshop represents just one of many AI-enabled services in Snapchat that uses Triton Inference Server to efficiently handle inference requests. Triton Inference Server versatility extends across various applications and services, particularly those reliant on optical character recognition (OCR).
“Texts and emojis are a common form of communication among our user base, exceeding 800 million” explained Byung Eun (Logan) Jeon, an ML engineer at Snap, during a recent presentation at GTC. “These texts and emojis are packed with contextual information vital to a wide array of our services from our Beauty Scanner service, which allows users to take a picture of a packaged product to perform a visual search, to our content moderation and policy violation detection services.”
Given the broad and varied demand for OCR-supported services among Snap users, selecting an inference serving platform capable of scaling effectively was paramount for Logan Jeon and his team. Triton Inference Server compatibility with the industry standard Kserve protocol and its ability to monitor and report GPU utilization metrics using Prometheus over standard HTTP protocols made it straightforward for the team to scale their OCR models. They achieved this by integrating Triton Inference Server into their Kubernetes engine orchestrating the server across more than 1K NVIDIA T4 and L4 GPUs at peak, ensuring efficient service delivery.
Effortless transition from Jupiter notebooks to production with business logic scripting
Snapchat’s global adoption required the OCR ML Engineering team to simultaneously manage multiple language-specific object detection and recognition models to accurately process and interpret texts in different languages embedded in images.
During OCR’s research and development stage, the ML team employed custom Python logic to select the appropriate language-specific models to be served during inference. “We utilized Python conditional statements and loops in Jupiter notebooks during testing to dynamically select the correct language-specific model for inference,” explained Logan. “The BLS feature of NVIDIA Triton enabled us to effortlessly transition this custom logic into production, maintaining GPU efficiency and throughput.”
The BLS feature of Triton Inference Server facilitated the smooth transition of the ML team’s custom code from Jupiter notebooks into production, speeding up the time to market for their new OCR-enabled services. BLS is a collection of utility functions within Triton Inference Server that enables you to create a custom script. This script can invoke any model hosted by Triton Inference Server, based on conditions defined in either Python or C++.
Learn more
NVIDIA Triton Inference Server and NVIDIA TensorRT are open-source projects available on GitHub. They are also available as Docker containers that can be pulled from NVIDIA NGC and are part of NVIDIA AI Enterprise, which offers enterprise-grade security, stability, and support.
Enterprises seeking the fastest time to value can use NVIDIA NIM, a set of easy-to-use microservices for accelerated inference on a wide range of AI models, including open-source community and NVIDIA AI Foundation models.
