
As of March 18, 2025, NVIDIA Triton Inference Server is now part of the NVIDIA Dynamo Platform and has been renamed to NVIDIA Dynamo Triton, accordingly.
In many production-level machine learning (ML) applications, inference is not limited to running a forward pass on a single ML model. Instead, a pipeline of ML models often needs to be executed. Take, for example, a conversational AI pipeline that consists of three modules: an automatic speech recognition (ASR) module to convert the input audio waveform to text, a large language model (LLM) module to understand the input and provide a relevant response, and a text-to-speech (TTS) module to produce speech from the output of the LLM.
Or, consider a text-to-image application where the pipeline consists of an LLM and a diffusion model, which are used to encode the input text and synthesize an image from the encoded text, respectively. Furthermore, many applications require some preprocessing steps on the input data before feeding it to the ML models, or postprocessing steps on the output of these models. For example, input images might need to be resized, cropped, and decoded before being fed to computer vision models, or text inputs need to be tokenized before being fed to an LLM.
In recent years, the number of parameters in ML models has skyrocketed, and they are increasingly tasked with serving very large consumer bases; hence, optimizing the inference pipeline has become more critical than ever before. Tools like NVIDIA TensorRT and FasterTransformer optimize individual deep learning models for lower latency and higher throughput when performing inference on GPUs.
However, our overarching goal is not to speed up the inference on individual ML models, but the entire inference pipeline. For example, when serving models on GPU, having preprocessing and postprocessing steps on CPU slows down the performance of the entire pipeline even when the model execution step is fast. The most efficient solution for an inference pipeline is to have preprocessing, model execution, and postprocessing steps all running on GPUs. The efficiency of this end-to-end inference pipeline on GPU comes from the following two key factors.
- Data does not need to be copied back and forth between CPU (host) and GPU (device) in between pipeline steps.
- Strong computational power of the GPU is utilized for the entire inference pipeline.
NVIDIA Triton Inference Server is open-source inference serving software to deploy and run models at scale on both CPU and GPU. Among many features, NVIDIA Triton supports ensemble models, which enable you to define the inference pipeline as an ensemble of models in the form of a Directed Acyclic Graph (DAG). NVIDIA Triton will handle the execution of the entire pipeline. The ensemble model defines how the output tensor of one model is fed as an input to the other.
Using NVIDIA Triton ensemble models, you can run the entire inference pipeline on GPU or CPU or a mix of both. This is useful when preprocessing and postprocessing steps are involved, or when there are multiple ML models in the pipeline where the outputs of a model feed into another. For use cases where the pipeline includes loops, conditionals, or other custom logic, NVIDIA Triton supports Business Logic Scripting (BLS).
This post focuses on ensemble models only. It walks you through the steps to create an end-to-end inference pipeline with multiple models using different framework backends. NVIDIA Triton provides the flexibility of constructing a model pipeline using multiple framework backends and running them on GPU or CPU, or a mix of both. We will explore the following three ways to run the pipeline.
- The entire pipeline is executed on CPU.
- Preprocessing and postprocessing steps run on CPU and the model execution runs on GPU.
- The entire pipeline is executed on GPU.
We will also highlight the advantages of running the entire inference pipeline on GPU using NVIDIA Triton Inference Server. We focus on the CommonLit Readability Kaggle challenge for predicting complexity rates for literary passages for grades 3-12, using NVIDIA Triton for the entire inference pipeline. Note that NVIDIA Triton 22.11 was used for the purposes of this blog post. You can also use later releases of NVIDIA Triton, provided that you use matching versions across backends (denoted as <xx.yy>) to avoid possible compatibility errors.
Model creation
For this task, train two separate models: BERT Large trained using PyTorch and a random forest regressor trained using cuML. Name these models bert-large and cuml. Both models will take in the preprocessed excerpts as input and output a score, or complexity rate.
As the first model, fine-tune the transformer-based bert-large model from the pretrained Hugging Face model bert-large-uncased which has 340 M parameters. Fine-tune the model for the task by adding a linear layer that maps BERT’s last hidden layer to a single output value.
Use root mean square loss, Adam optimizer with weight decay, and 5-fold cross-validation for fine-tuning. Serialize the model as a TorchScript file (named model.pt) by passing a sample input through the model and tracing the model with the following commands:
traced_script_module = torch.jit.trace(bert_pytorch_model,
(example_input_ids, example_attention_mask))
traced_script_module.save("model.pt")
As the second model, use cuML random forest regressor with 100 trees and a maximum depth of 16 for each tree. Generate the following features for the tree-based model: number of words per excerpt, number of distinct words per excerpt, number of punctuations, number of sentences per excerpt, average number of words per sentence, number of stop words per excerpt, average number of stop words per sentence, frequency distribution of the N most frequent words across the corpus, and frequency distribution of the N least frequent words across the corpus.
Use N=100, such that the random forest takes in a total of 207 features. Serialize the trained cuML model as a Treelite checkpoint (named checkpoint.tl) by converting the cuML model instance using the following command:
cuml_model.convert_to_treelite_model().to_treelite_checkpoint('checkpoint.tl')Note that the Treelite version associated with the model needs to match the Treelite version in the NVIDIA Triton container used for inference.
Running ML models on NVIDIA Triton
Each model that is to be deployed in NVIDIA Triton must include a model configuration. By default, NVIDIA Triton will try to create the configuration automatically using the model metadata when such data is available. You can provide the model configuration file manually in cases where model metadata is not sufficient, or to override the inferred settings. See triton-inference-server/server on GitHub for more details.
To run BERT Large which is in PyTorch format on NVIDIA Triton, use the PyTorch (LibTorch) backend. Add the following line to the model configuration file to specify this backend:
backend: "pytorch"To run the tree-based random forest model on NVIDIA Triton, use the FIL (Forest Inference Library) backend by adding the following to the model configuration file:
backend: "fil"Moreover, add the following lines to the model configuration file to specify that the provided model is in Treelite binary format:
parameters {
key: "model_type"
value: { string_value: "treelite_checkpoint" }
}
Finally, in each model configuration file, include either instance_group[{kind:KIND_GPU}] or instance_group[{kind:KIND_CPU}], depending on whether the model is to be served on GPU or CPU.
The resulting model repository directory structure up to this point is as follows:
.
├── bert-large
│ ├── 1
│ │ └── model.pt
│ └── config.pbtxt
└── cuml
├── 1
│ └── checkpoint.tl
└── config.pbtxt
Preprocessing and postprocessing
Preprocessing and postprocessing can be performed outside the NVIDIA Triton server or incorporated as part of an ensemble of models in NVIDIA Triton. For this example, preprocessing and postprocessing consist of operations performed in Python. Use the Python backend to run these operations as part of an ensemble.
If the default Python version shipped in the NVIDIA Triton server container can run your Python models, you can ignore the following sections and jump directly to the section below titled ‘Comparing inference pipelines.’ Otherwise, you will need to create a custom Python backend stub and a custom execution environment, which are explained below.
Custom Python backend stub
Python backend uses a stub process to connect the model.py file to the NVIDIA Triton C++ core. Python backend can use the libraries that are installed in the current Python environment (virtual environment or Conda environment) or in the global Python environment.
Note that this assumes that the Python version used to compile the backend stub is the same as the one used to install the dependencies. The default Python version in the NVIDIA Triton container used at the time of writing is 3.8. If the Python version for which you need to run preprocessing and postprocessing does not match what is in the NVIDIA Triton container, you need to compile a custom Python backend stub.
To create a custom Python backend stub, install conda, cmake, rapidjson, and libarchive inside the NVIDIA Triton container. Next, create a Conda virtual environment (see the documentation) and activate it using the following commands:
conda create -n custom_env python=<python-version>
conda init bash
bash
conda activate custom_envReplace <python-version> with the version of interest, such as 3.9. Then clone the Python backend repo and compile the Python backend stub using the code below:
git clone https://github.com/triton-inference-server/python_backend -b r<xx.yy>
cd python_backend
mkdir build && cd build
cmake -DTRITON_ENABLE_GPU=ON -DCMAKE_INSTALL_PREFIX:PATH=`pwd`/install ..
make triton-python-backend-stubNote that <xx.yy> must be replaced with the NVIDIA Triton container version. Running the commands above results in the creation of the stub file named triton-python-backend-stub. This Python backend stub can now be used to load libraries that are installed with a matching version of Python.
Custom execution environment
If you want to use different Python environments for different Python models, you need to create a custom execution environment. To create the custom execution environment for our Python models, the first step is to install any necessary dependencies in the Conda environment that is already activated. Then run conda-pack to package our custom execution environment as a tar file. This creates a file named custom_env.tar.gz.
At the time of writing, NVIDIA Triton only supports conda-pack for the purpose of capturing the execution environment. Note that when working from within an NVIDIA Triton Docker container, the packages included in the container are also captured within the execution environment created by conda-pack.
Using the Python backend stub and custom execution environment
After creating the Python backend stub and the custom execution environment, copy the two resulting files from the container to the local system where the model repository lies. In the local system, copy the stub files into the model directory for each Python model that needs to use the stub (that is, the preprocessing and postprocessing models). For these models, the directory structure is as follows:
model_repository
├── postprocess
│ ├── 1
│ │ └── model.py
│ ├── config.pbtxt
│ └── triton_python_backend_stub
└── preprocess
├── 1
│ └── model.py
├── config.pbtxt
└── triton_python_backend_stubFor the preprocessing and postprocesing models, you also need to provide the path to the custom execution environment’s tar file in the configuration file. For example, the configuration file for the preprocessing model will include the following code:
name: "preprocess"
backend: "python"
...
parameters: {
key: "EXECUTION_ENV_PATH",
value: {string_value: "path/to/custom_env.tar.gz"}
}For this step to work, store custom_env.tar.gz in a path that the NVIDIA Triton Inference Server container has access to.
Structure of model.py files for preprocessing and postprocessing
Each Python model needs to follow a particular structure as described in the documentation. Define the following three functions within the model.py file:
1. initialize (optional, run when loading the model): Used to load necessary components before inference to reduce the overhead for each client request. Specifically for preprocessing, load the cuDF tokenizer that will be used to tokenize excerpts for BERT-based models. Also load a list of stop words used for random forest feature generation as part of the input to the tree-based models.
2. execute (required, run when inference is requested): Takes in an inference request, modifies the input, and returns an inference response. Since preprocess is the entry point of the inference, the input needs to be moved to the GPU if inference is to be performed on GPU.
Move the excerpt input tensor to GPU by creating an instance of cudf.Series and then tokenize the entire batch of excerpts on GPU by taking advantage of the cuDF tokenizer loaded in initialize.
Similarly, generate the tree-based features using string manipulation and then normalize the features using CuPY arrays operating on GPU. To output the tensors on GPU, use toDlpack and from_dlpack (see the documentation) to package the tensor into the inference response.
Finally, to keep the tensors on GPU and avoid copying to CPU between the steps in the ensemble, add the following to the configuration file of each model:
parameters: {
key: "FORCE_CPU_ONLY_INPUT_TENSORS"
value: {
string_value:"no"
}
}The input scores for postprocess are already on GPU, so just ensemble the scores again with CuPY arrays and output a final pipeline score. For the case where postprocessing is done on CPU, move the output of the ML models to CPU at the preprocessing step.
3. finalize (optional, run when unloading the model): Enables you to complete any necessary cleanups before unloading the model from NVIDIA Triton server.
Comparing inference pipelines
This section introduces different inference pipelines and compares them in terms of latency and throughput.
Preprocessing and postprocessing on CPU, ML model inference on GPU
This setup uses NVIDIA Triton to perform inference on the ML models, while performing preprocessing and postprocessing using CPUs on a local machine where the client lies (Figure 1). In the preprocessing model, for a given batch of text excerpts, tokenize the excerpts using the BERT tokenizer and generate the tree-based features for the cuML model.
Then send the output of the preprocessing model as an inference request to NVIDIA Triton. NVIDIA Triton then performs inference on the ML models on GPU and returns a response. Postprocess this response locally on CPU to produce the output score.
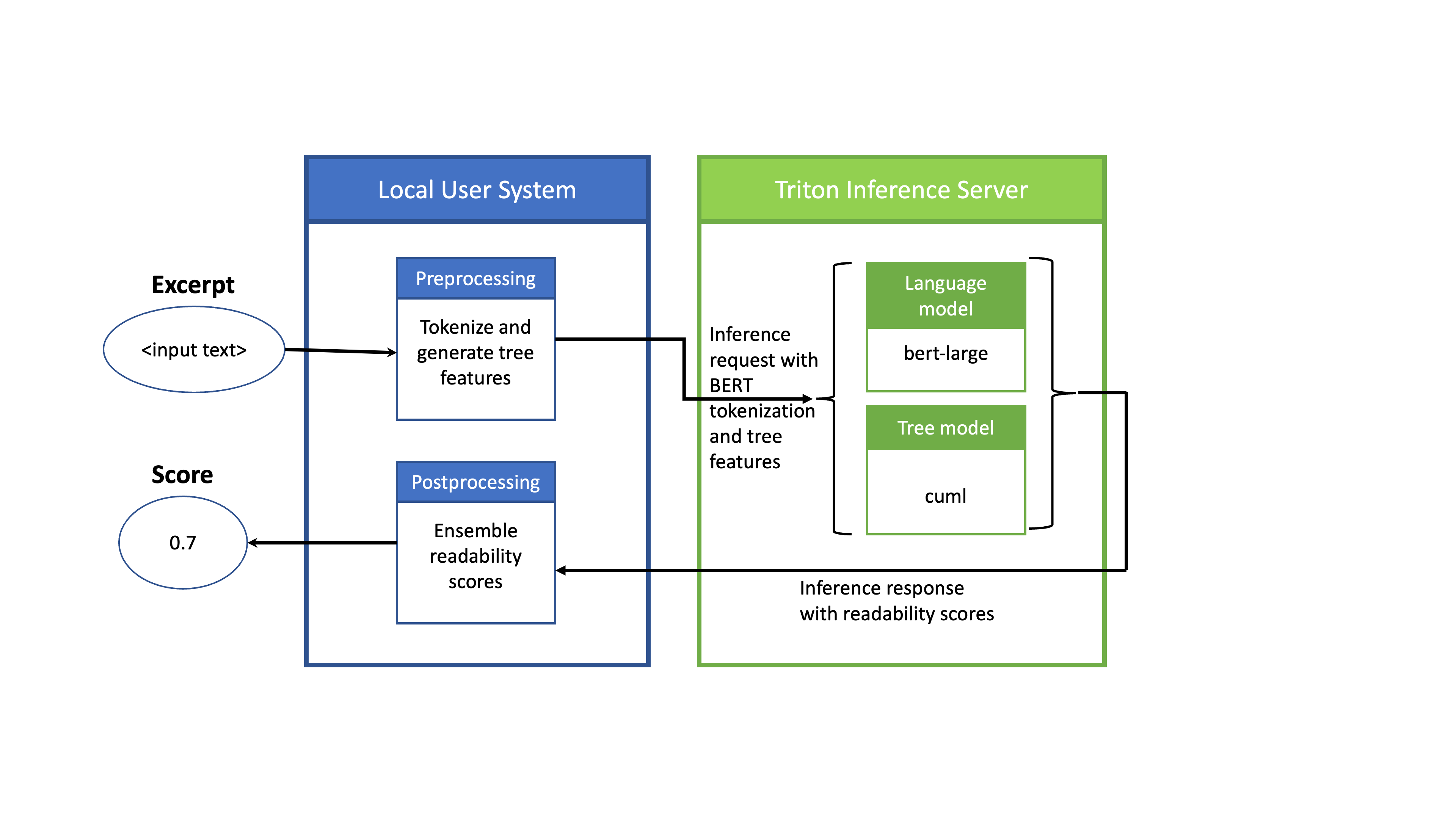
Executing the entire pipeline in NVIDIA Triton on GPU
In this setup, execute the entire inference pipeline on GPU using NVIDIA Triton. For this example, the pipeline and flow of data within NVIDIA Triton can be seen in Figure 2.
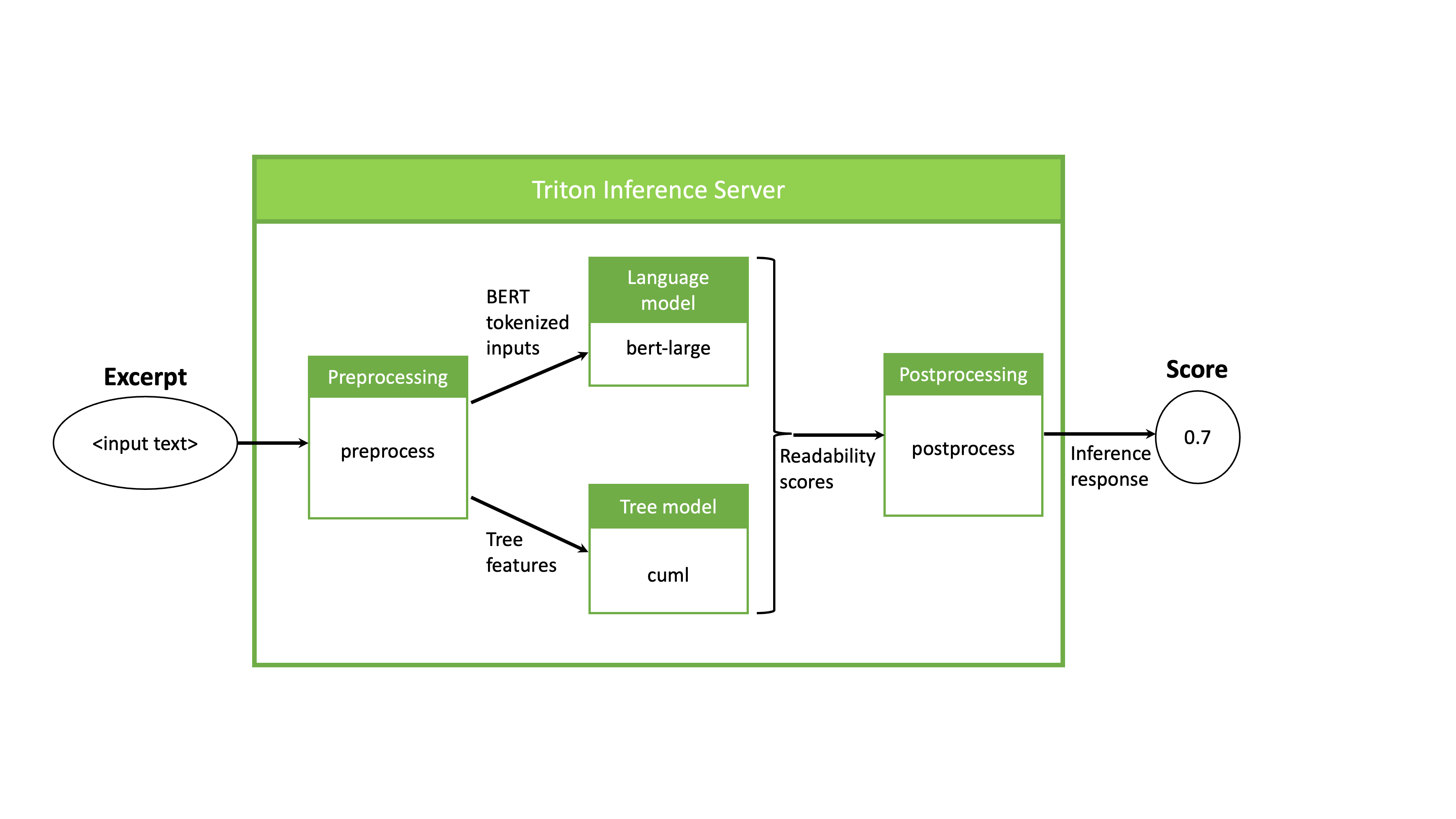
The pipeline begins with a preprocessing model that takes an excerpt of text as input, tokenizes the excerpt for BERT, and extracts features for the random forest model. Next, the two ML models are run simultaneously on the output of the preprocessing model, each generating a score indicating the complexity rate of the input text. Finally, the resulting scores are combined in a postprocessing step.
To have NVIDIA Triton run the execution pipeline above, create an ensemble model called ensemble_all. This model has the same model directory structure as any other model, except that it does not store any model, and consists of only a configuration file. The directory for the ensemble model is shown below:
├── ensemble_all
│ ├── 1
│ └── config.pbtxt
In the configuration file, first specify the ensemble model name and backend using the following script:
name: "ensemble_all"
backend: "ensemble"
Next, define the endpoints of the ensemble, namely the input and output of the ensemble model:
input [
{
name: "excerpt"
data_type: TYPE_STRING
dims: [ -1 ]
},
{
name: "BERT_WEIGHT"
data_type: TYPE_FP32
dims: [ -1 ]
}
]
output {
name: "SCORE"
data_type: TYPE_FP32
dims: [ 1 ]
}
The input to the pipeline is of variable length, hence use -1 for the dimension parameter. The output is a single floating point number.
To create the pipeline and data flow through different models, include an ensemble_scheduling section. The first model is called preprocess, which takes in the excerpt as input and outputs BERT token identifiers and attention masks, as well as tree features. The first step of the scheduling is shown in the following portion of the model configuration:
ensemble_scheduling {
step [
{
model_name: "preprocess"
model_version: 1
input_map {
key: "INPUT0"
value: "excerpt"
}
output_map {
key: "BERT_IDS"
value: "bert_input_ids",
}
output_map {
key: "BERT_AM"
value: "bert_attention_masks",
}
output_map {
key: "TREE_FEATS"
value: "tree_feats",
}
},
Each element in the step section specifies the model to be used and how the inputs and outputs of the model are mapped to tensor names recognized by the ensemble scheduler. These tensor names are then used to identify the individual inputs and outputs.
For example, the first element in step specifies that version one of the preprocess model should be used, the content of its input "INPUT0" is provided by "excerpt" tensor, and the content of its output "BERT_IDS" will be mapped to "bert_input_ids" tensor for later use. Similar reasoning applies to the other two outputs of preprocess.
Continue adding steps to the configuration file to specify the entire pipeline, passing the outputs of preprocess into the inputs of bert-large and cuml:
{
model_name: "bert-large"
model_version: 1
input_map {
key: "INPUT__0"
value: "bert_input_ids"
}
input_map {
key: "INPUT__1"
value: "bert_attention_masks"
}
output_map {
key: "OUTPUT__0"
value: "bert_large_score"
}
},Finally, by adding the following lines to the configuration file, pass each of these scores to the postprocessing model to compute the average of scores and provide a single output score, as shown below:
{
model_name: "postprocess"
model_version: 1
input_map {
key: "BERT_WEIGHT_INPUT"
value: "BERT_WEIGHT"
}
input_map {
key: "BERT_LARGE_SCORE"
value: "bert_large_score"
}
input_map {
key: "CUML_SCORE"
value: "cuml_score"
}
output_map {
key: "OUTPUT0"
value: "SCORE"
}
}
}
]
The simplicity of scheduling the entire pipeline within the configuration file of the ensemble model demonstrates the flexibility of using NVIDIA Triton for end-to-end inference. To add another model or add another data processing step, edit the configuration file of the ensemble model and update the corresponding model directory.
Note that the max_batch_size defined in the ensemble configuration file must be less than or equal to the max_batch_size defined in each model. The entire model directory, including the ensemble model, is shown below:
├── bert-large
│ ├── 1
│ │ └── model.pt
│ └── config.pbtxt
├── cuml
│ ├── 1
│ │ └── checkpoint.tl
│ └── config.pbtxt
├── ensemble_all
│ ├── 1
│ │ └── empty
│ └── config.pbtxt
├── postprocess
│ ├── 1
│ │ ├── model.py
│ └── config.pbtxt
└── preprocess
├── 1
│ ├── model.py
└── config.pbtxt
To tell NVIDIA Triton to execute all the models on GPU, include the following line in each model’s configuration file (except in the ensemble model’s configuration file):
instance_group[{kind:KIND_GPU}]Executing entire pipeline in NVIDIA Triton on CPUTo have NVIDIA Triton execute the entire pipeline on CPU, repeat all the steps outlined for running the pipeline on GPU. Replace the instance_group[{kind:KIND_GPU}] with the following line in each configuration file:
instance_group[{kind:KIND_CPU}]Results
We compared the following three inference pipelines in terms of latency and throughput using a GCP a2-highgpu-1g VM:
- Full pipeline executed by NVIDIA Triton on Intel Xeon CPU at 2.20 GHz
- ML model execution performed by NVIDIA Triton on NVIDIA A100 40 GB GPU, preprocessing and postprocessing performed locally on Intel Xeon CPU at 2.20 GHz
- Full pipeline executed by NVIDIA Triton on NVIDIA A100 40 GB GPU
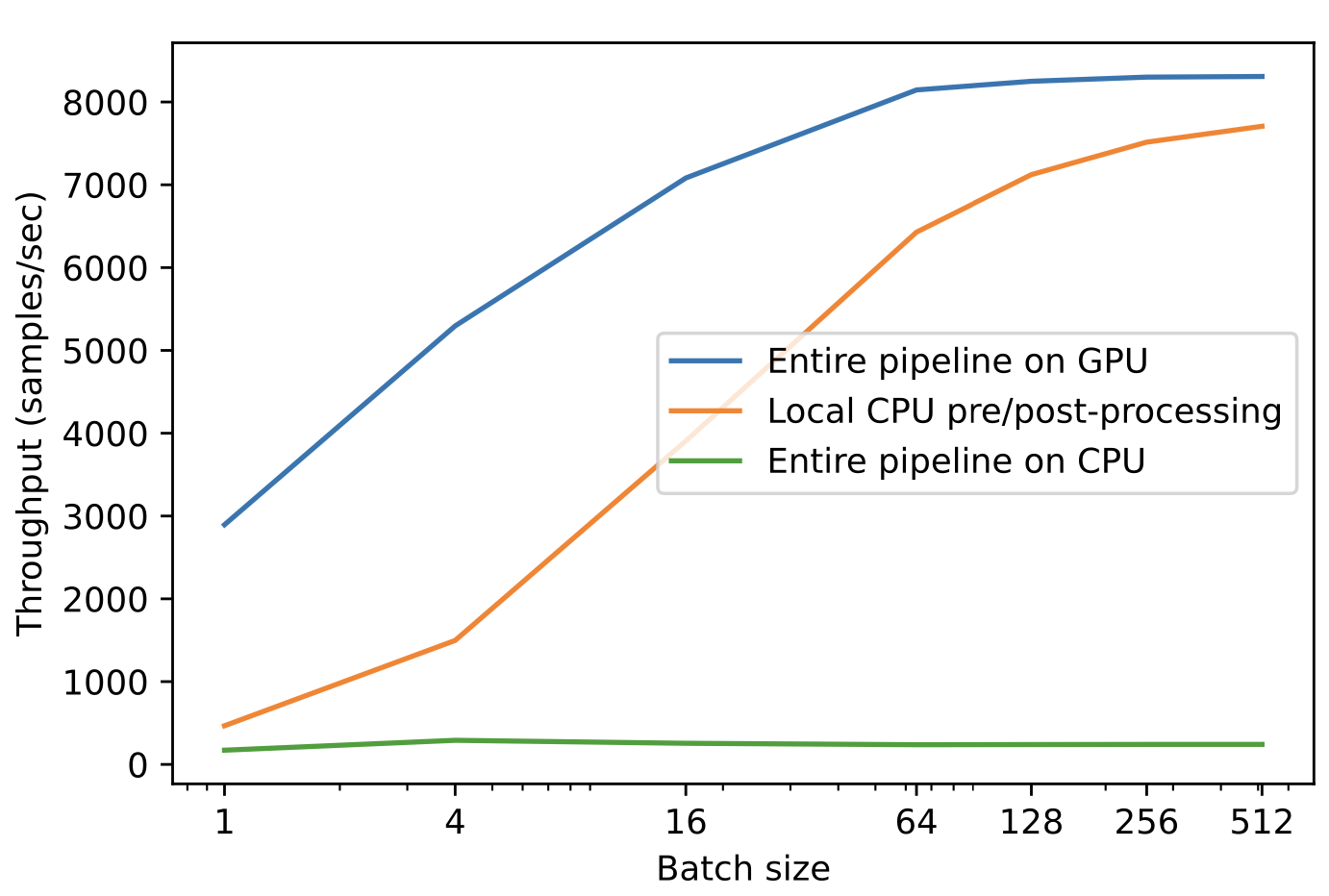
The advantage of running the entire pipeline on GPU using NVIDIA Triton is evident from the results in Table 1. For larger batch sizes and tensor sizes, the improvement in throughput is more pronounced. NVIDIA A100 40 GB model execution pipelines are much more efficient than the full pipeline on Intel Xeon CPU at 2.20 GHz. There is further improvement when moving preprocessing and postprocessing from CPU to GPU.
| Full pipeline on CPU | Pre/postprocess on CPU; ML models on GPU | Full pipeline on GPU | |
| Latency (ms) | 523 | 192 | 31 |
| Throughput (samples/second) for batch size 512 | 242 | 7707 | 8308 |
As shown in Figure 3, the CPU is bottlenecked at very modest batch sizes, and running the entire pipeline on GPU can provide dramatic improvements in throughput.
Conclusion
This post explains how to use NVIDIA Triton Inference Server to run an inference pipeline consisting of preprocessing and postprocessing and a transformer-based language model, as well as a tree-based model to solve a Kaggle challenge. NVIDIA Triton provides the flexibility of using multiple frameworks/backends for the models and preprocessing and postprocessing logic of the same pipeline. These pipelines can be run on CPUs and/or GPUs.
We show that taking advantage of GPUs for preprocessing and postprocessing phases along with model execution reduces the end-to-end latency by a factor of 6x compared to running preprocessing and postprocessing steps on CPU and model execution on GPU. We also show that using NVIDIA Triton enables us to simultaneously execute inference on several ML models and going from one deployment type (all CPUs) to another (all GPUs) requires just a single line of change in the configuration file.
Reach out with questions or feedback. We look forward to seeing inference pipelines take advantage of NVIDIA Triton for other tasks. To download the software and learn more, visit the NVIDIA Triton Inference Server page.
Register for NVIDIA GTC 2023 for free and join us March 20–23 for Taking AI Models to Production: Accelerated Inference with Triton Inference Server and many more related sessions.
