Posts by Josh Park

Developer Tools & Techniques
Jul 24, 2025
Double PyTorch Inference Speed for Diffusion Models Using Torch-TensorRT
NVIDIA TensorRT is an AI inference library built to optimize machine learning models for deployment on NVIDIA GPUs. TensorRT targets dedicated hardware in...
8 MIN READ

Agentic AI / Generative AI
Mar 10, 2025
Streamline LLM Deployment for Autonomous Vehicle Applications with NVIDIA DriveOS LLM SDK
Large language models (LLMs) have shown remarkable generalization capabilities in natural language processing (NLP). They are used in a wide range of...
7 MIN READ

Computer Vision / Video Analytics
Jan 29, 2024
Emulating the Attention Mechanism in Transformer Models with a Fully Convolutional Network
The past decade has seen a remarkable surge in the adoption of deep learning techniques for computer vision (CV) tasks. Convolutional neural networks (CNNs)...
13 MIN READ

Simulation / Modeling / Design
May 16, 2023
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA TensorRT Acceleration
The training stage of deep learning (DL) models consists of learning numerous dense floating-point weight matrices, which results in a massive amount of...
12 MIN READ
Robotics
Jun 16, 2022
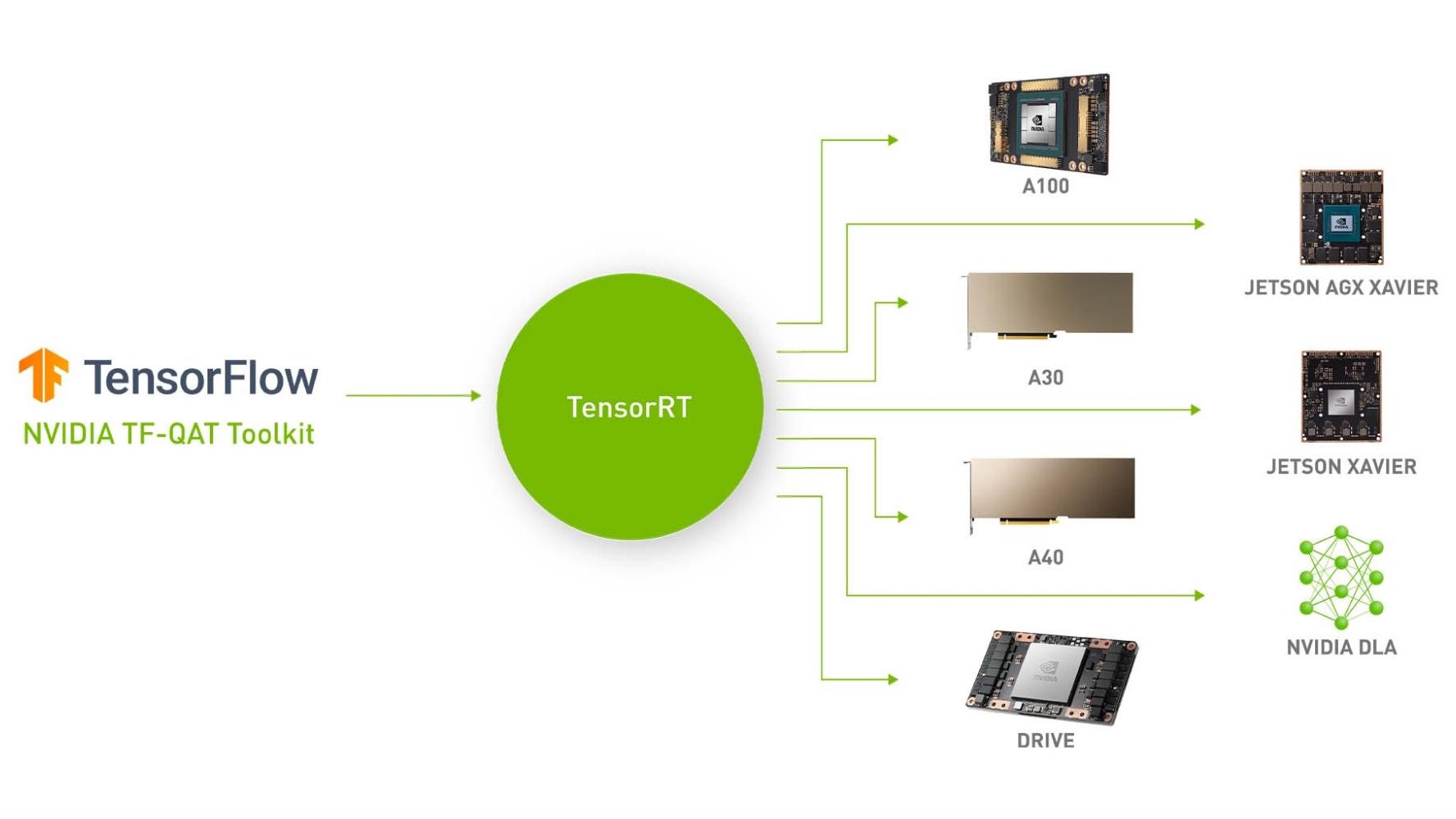
Accelerating Quantized Networks with the NVIDIA QAT Toolkit for TensorFlow and NVIDIA TensorRT
We’re excited to announce the NVIDIA Quantization-Aware Training (QAT) Toolkit for TensorFlow 2 with the goal of accelerating the quantized networks with...
9 MIN READ
Data Science
Jul 20, 2021
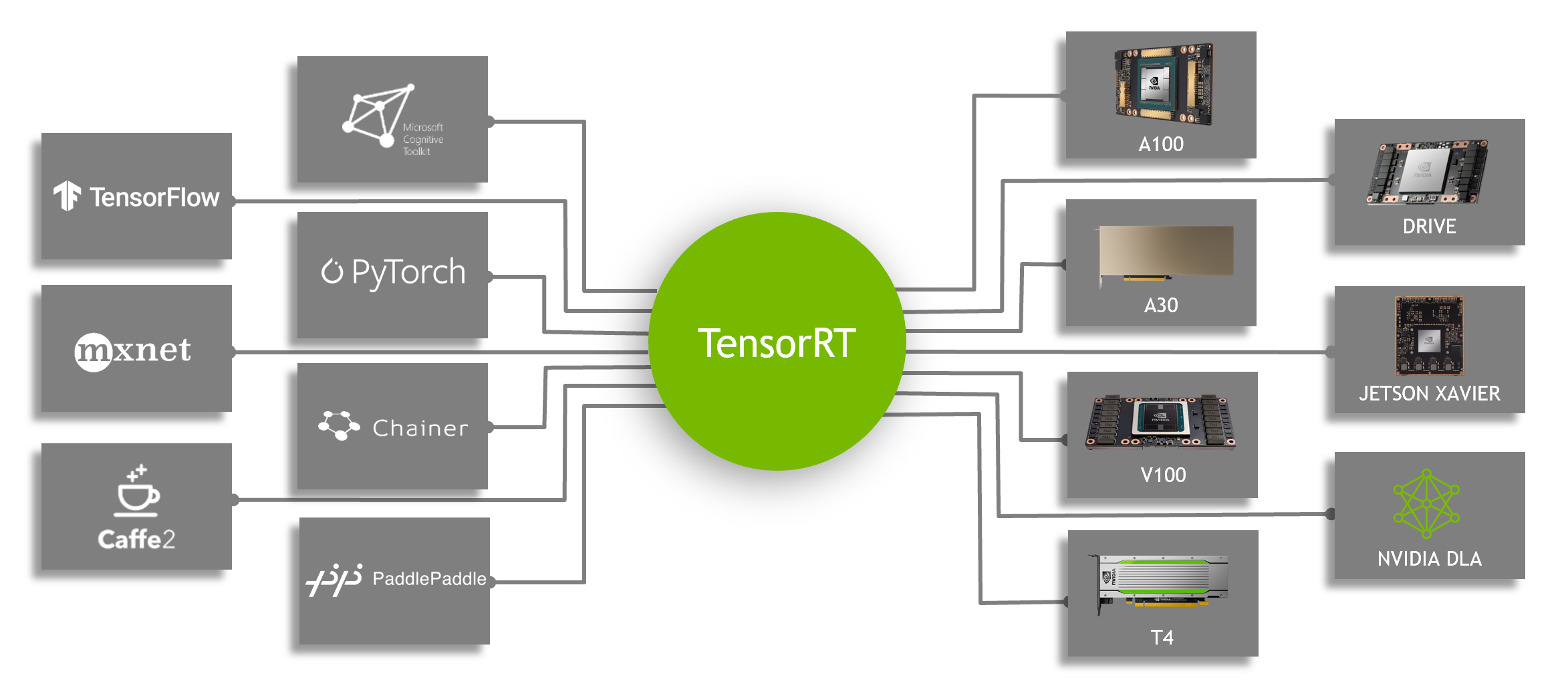
Speeding Up Deep Learning Inference Using TensorFlow, ONNX, and NVIDIA TensorRT
This post was updated July 20, 2021 to reflect NVIDIA TensorRT 8.0 updates. In this post, you learn how to deploy TensorFlow trained deep learning models using...
15 MIN READ