
Speaker diarization is the process of segmenting audio recordings by speaker labels and aims to answer the question “Who spoke when?”. It makes a clear distinction when it is compared with speech recognition.
Before you perform speaker diarization, you know “what is spoken” but you don’t know “who spoke it”. Therefore, speaker diarization is an essential feature for a speech recognition system that enriches the transcription with speaker labels. That is, conversational speech recordings can never be considered to be fully transcribed without a speaker diarization process because transcriptions without speaker labels cannot inform you who is speaking to whom.
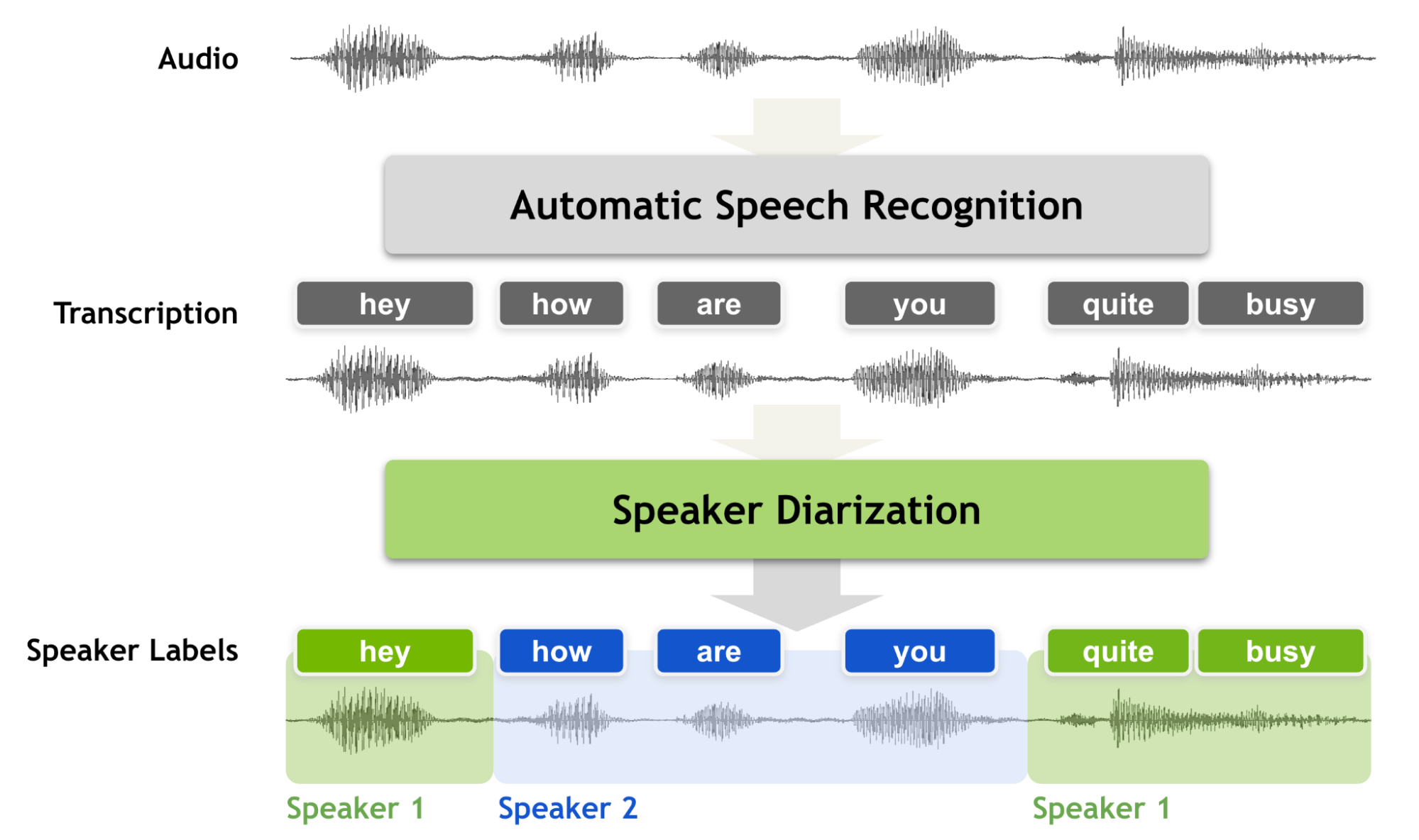
Speaker diarization must produce accurate timestamps as speaker turns can be extremely short in conversational settings. We often use short back-channel words such as “yes”, “uh-huh,” or “oh.” These words are challenging for machines to transcribe and identify the speaker.
While segmenting audio recordings in terms of speaker identity, speaker diarization requires fine-grained decisions on relatively short segments, ranging from a few tenths of a second to several seconds. Making accurate, fine-grained decisions on such short audio segments is challenging because it is less likely to capture reliable speaker traits.
In this post, we discuss how this problem can be addressed by introducing a new technique called the multi-scale approach and multiscale diarization decoder (MSDD) to handle multi-scale inputs.
Mechanism of multi-scale segmentation
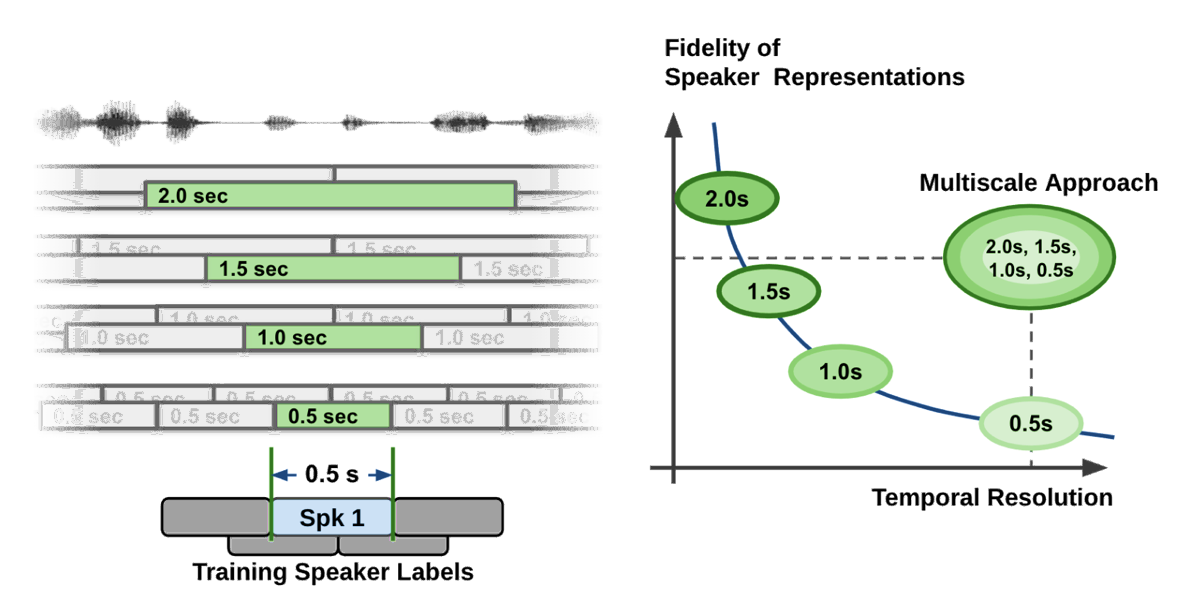
Extracting long audio segments is desirable in terms of the quality of speaker characteristics. However, the length of audio segments also limits the granularity, which leads to a coarse unit length for speaker label decisions. Speaker diarization systems are challenged by a trade-off between temporal resolution and the fidelity of the speaker representation, as shown by the curve shown in Figure 2.
During the speaker feature extraction process in the speaker diarization pipeline, the temporal resolution is inevitably sacrificed by taking a long speech segment to obtain high-quality speaker representation vectors. In plain and simple language, if you try to be accurate on voice characteristics, then you have to look into a longer span of time.
At the same time, if you look into a longer span of time, you have to make a decision on a fairly long span of time. This leads to coarse decisions (temporal resolution is low). Think about the fact that even human listeners cannot accurately tell who is speaking if only half a second of recorded speech is given.
In most diarization systems, an audio segment length ranges from 1.5~3.0 seconds becausesuch numbers make a good compromise between the quality of speaker characteristics and temporal resolution. This type of segmentation method is known as a single-scale approach.
Even with an overlap technique, the single-scale segmentation limits the temporal resolution to 0.75~1.5 seconds, which leaves room for improvement in terms of temporal accuracy.
Having a coarse temporal resolution not only deteriorates the performance of diarization but also decreases speaker counting accuracy since short speech segments are not captured properly. More importantly, such coarse temporal resolution in the speaker timestamps makes the matching between the decoded ASR text and speaker diarization result more error-prone.
To tackle the problem, we proposed a multi-scale approach, which is a way to cope with such a trade-off by extracting speaker features from multiple segment lengths and then combining the results from multiple scales. The multi-scale technique achieves state-of-the-art accuracy on the most popular speaker diarization benchmark datasets. It is already part of the open-source conversational AI toolkit NVIDIA NeMo.
Figure 2 shows the key technical solutions of multi-scale speaker diarization.
The multi-scale approach is fulfilled by employing multi-scale segmentation and extracting speaker embeddings from each scale. On the left side of Figure 2, four different scales in a multi-scale segmentation approach are performed.
During the segment affinity calculation process, all the information from the longest scale to the shortest scale is combined, yet a decision is made only for the shortest segment range. When combining the features from each scale, the weight of each scale largely affects the speaker diarization performance.
Multiscale diarization pipeline with neural models
Because scale weights largely determine the accuracy of the speaker diarization system, the scale weights should be set to have the maximized speaker diarization performance.
We came up with a novel multi-scale diarization system called multiscale diarization decoder (MSDD) that dynamically determines the importance of each scale at each time-step.
Speaker diarization systems rely on the speaker characteristics captured by audio feature vectors called speaker embeddings. The speaker embedding vectors are extracted by a neural model to generate a dense floating point number vector from a given audio signal.
MSDD takes the multiple speaker embedding vectors from multiple scales and then estimates desirable scale weights. Based on the estimated scale weights, speaker labels are generated. The proposed system weighs more on the large scale if the input signals are considered to have more accurate information on certain scales.
Figure 3 shows the data flow of the proposed multiscale speaker diarization system. Multi-scale segments are extracted from audio input, and corresponding speaker embedding vectors for multi-scale audio input are generated by using the speaker embedding extractor (TitaNet).
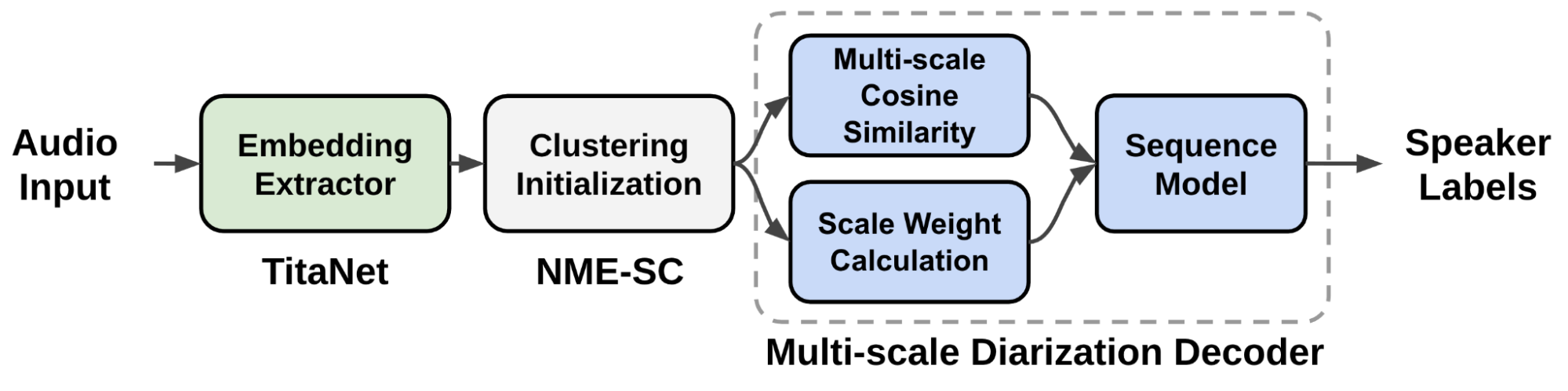
The extracted multi-scale embeddings are processed by clustering algorithm to provide an initializing clustering result to the MSDD module. The MSDD module uses cluster-average speaker embedding vectors to compare these with input speaker embedding sequences. The scale weights for each step are sestimated to weigh the importance of each scale.
Finally, the sequence model is trained to output speaker label probabilities for each speaker.
MSDD mechanism
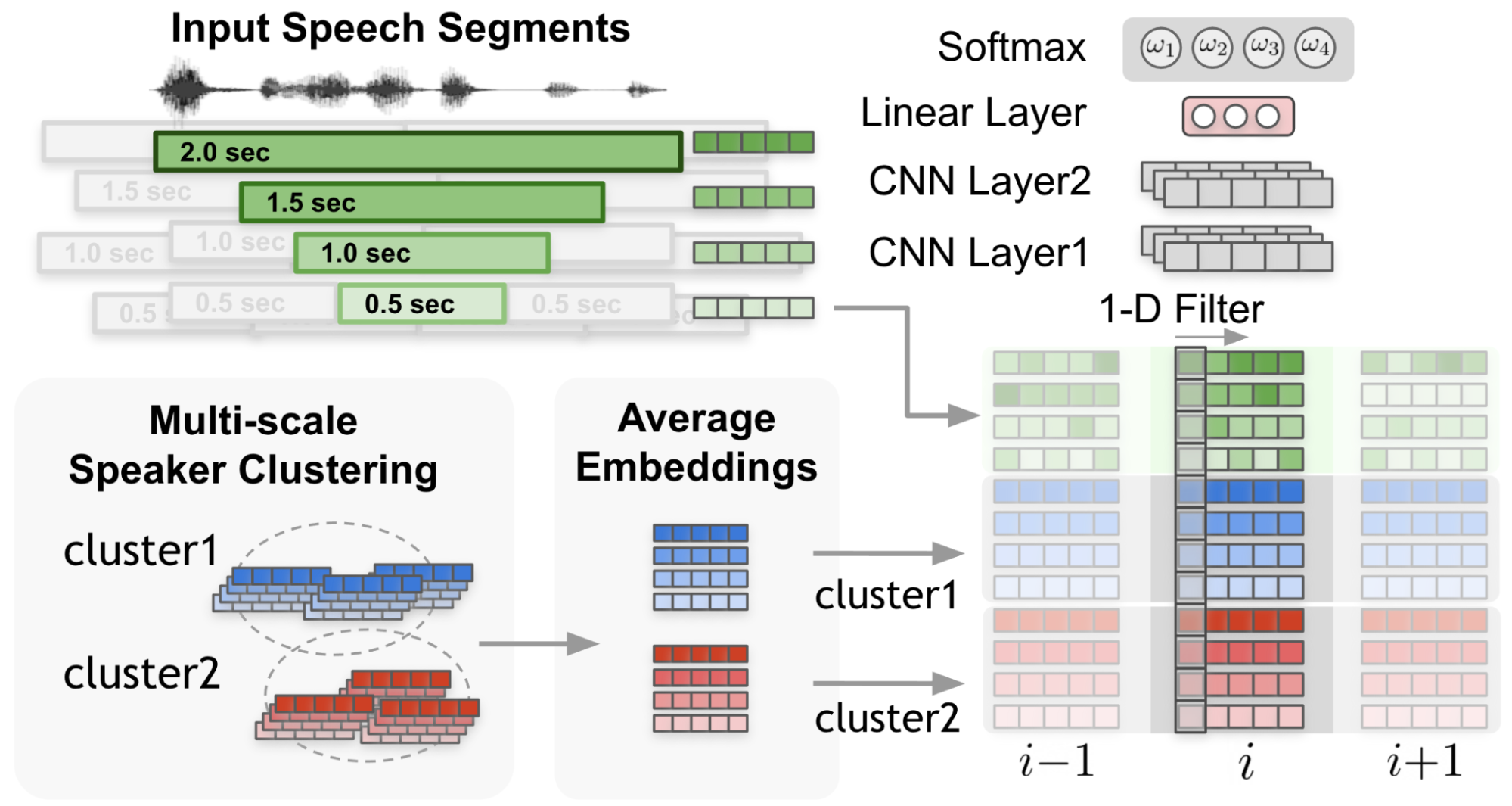
In Figure 4, the 1-D filter captures the context from the input embeddings and cluster average embeddings.
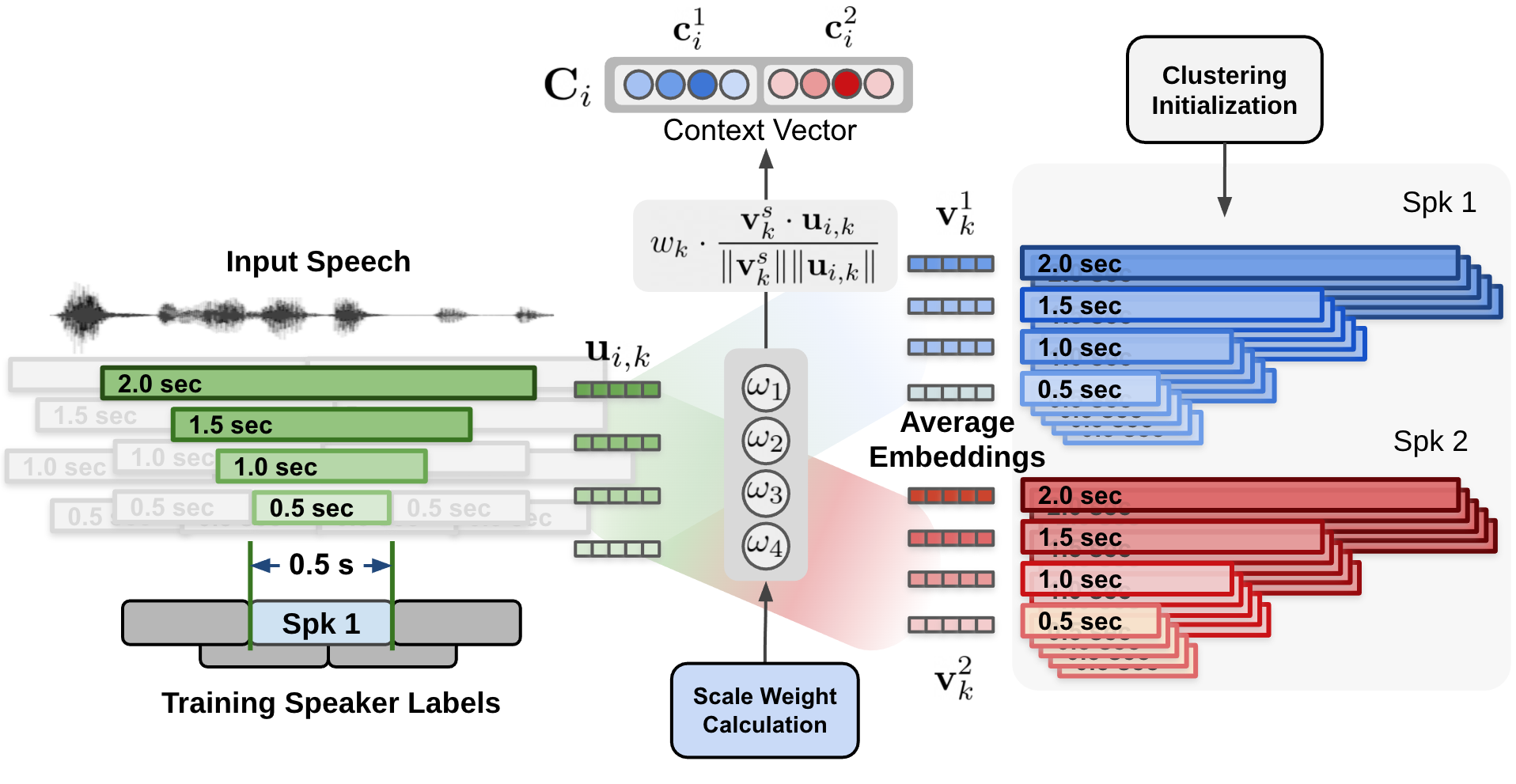
In Figure 5, cosine similarity values from each speaker and each scale are weighted by the scale weights to form a weighted cosine similarity vector.
The neural network model MSDD is trained to take advantage of a multi-scale approach by dynamically calculating the weight of each scale. MSDD takes the initial clustering results and compares the extracted speaker embeddings with the cluster-average speaker representation vectors.
Most importantly, the weight of each scale at each time step is determined through a scale weighting mechanism where the scale weights are calculated from a 1-D convolutional neural networks (CNNs) applied to the multi-scale speaker embedding inputs and the cluster average embeddings (Figure 3).
The estimated scale weights are applied to cosine similarity values calculated for each speaker and each scale. Figure 5 shows the process of calculating the context vector by applying the estimated scale weights on cosine similarity calculated (Figure 4) between cluster-average speaker embedding and input speaker embeddings.
Finally, each context vector for each step is fed to a multi-layer LSTM model that generates per-speaker speaker existence probability. Figure 6 shows how speaker label sequences are estimated by the LSTM model and context vector input.
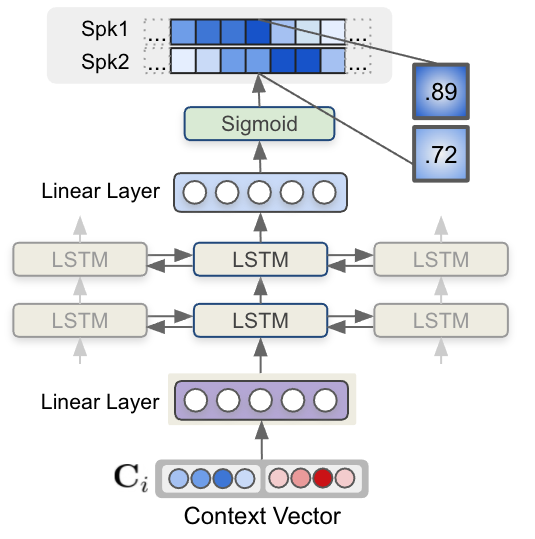
Figure 6, sequence modeling using LSTM takes the context vector input and generates speaker labels. The output of MSDD is the probability values of speaker existence at each timestep for two speakers.
The proposed speaker diarization system is designed to support the following features:
- Flexible number of speakers
- Overlap-aware diarization
- Pretrained speaker embedding model
Flexible number of speakers
MSDD employs pairwise inference to diarize conversation with arbitrary numbers of speakers. For example, if there are four speakers, six pairs are extracted, and inference results from MSDD are averaged to obtain results for each of the four speakers.
Overlap-aware diarization
MSDD independently estimates the probability of two speaker labels of two speakers at each step (Figure 6). This enables overlap detection where two speakers are speaking at the same time.
Pretrained speaker embedding model
MSDD is based on the pretrained embedding extractor (TitaNet) model. By using a pretrained speaker model, you can use the neural network weights learned from a relatively large amount of single-speaker speech data.
In addition, MSDD is designed to be optimized with a pretrained speaker to fine-tune the entire speaker diarization system on a domain-specific diarization dataset.
Experimental results and quantitative benefits
The proposed MSDD system has several quantitative benefits: superior temporal resolution and improved accuracy.
Superior temporal resolution
While the single-scale clustering diarizer shows the best performance at a 1.5-second segment length where the unit decision length is 0.75 seconds (half-overlap), the proposed multi-scale approach has a unit decision length of 0.25 seconds. The temporal resolution can be even more enhanced by using a shorter shift length that requires more steps and resources.
Figure 2 shows the concept of the multi-scale approach and the unit decision length of 0.5 seconds. Merely applying 0.5-second segment length to a single-scale diarizer significantly drops the diarization performance due to the degraded fidelity of speaker features.
Improved accuracy
Diarization error rate (DER) is calculated by comparing hypothesis timestamps and ground-truth timestamps. Figure 7 shows the quantified performance of the multi-scale diarization approach over the state-of-the-art and single-scale clustering methods.
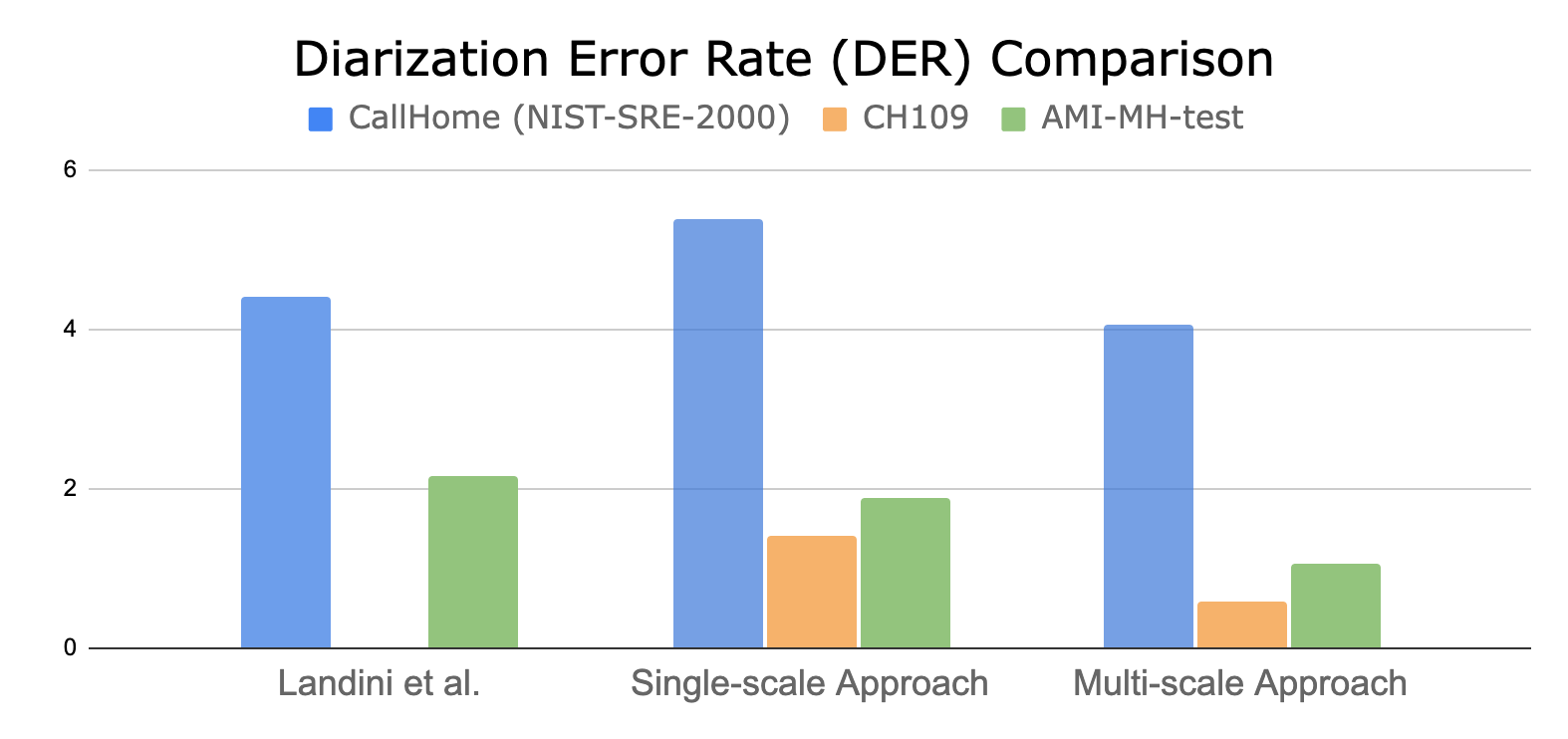
The proposed MSDD approach can reduce DER up to 60% on two-speaker datasets when compared to the single-scale clustering diarizer.
Conclusion
The proposed system has the following benefits:
- This is the first neural network architecture that applies a multi-scale weighting concept with sequence model (LSTM) based speaker label estimation.
- The weighing scheme is integrated in a single inference session and does not require fusion of multiple diarization results as in other speaker diarization systems.
- The proposed multi-scale diarization system enables overlap-aware diarization which cannot be achieved with traditional clustering-based diarization systems.
- Because the decoder is based on a clustering-based initialization, the diarization system can deal with a flexible number of speakers. This indicates that you can train the proposed model on two-speaker datasets and then use it for diarizing two or more speakers.
- While having all previously mentioned benefits, the proposed approach shows a superior diarization performance compared to the previously published results.
There are two future areas of research regarding the proposed system:
- We plan to implement a streaming version of the proposed system by implementing diarization decoder based on short-term window-based clustering.
- The end-to-end optimization from speaker embedding extractor to diarization decoder can be investigated to improve the speaker diarization performance.
For more information, see Multiscale Speaker Diarization with Dynamic Scale Weighting or see the Interspeech 2022 session.
