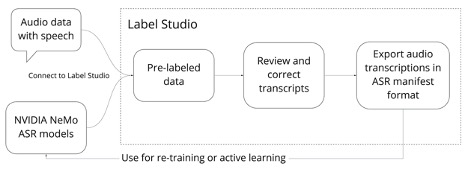
You can save time and produce a more accurate result when processing audio data with automated speech recognition (ASR) models from NVIDIA NeMo and Label Studio.
NVIDIA NeMo provides reusable neural modules that make it easy to create new neural network architectures, including prebuilt modules and ready-to-use models for ASR. With the power of NVIDIA NeMo, you can get audio transcriptions from the pretrained speech recognition models. Add Label Studio and its open-source data labeling capabilities to the mix and you can improve the transcription quality even further.
Solution
Follow the steps in this post to set up NVIDIA NeMo ASR with Label Studio to produce high-quality audio transcripts.
- Connect the NVIDIA NeMo model to transcribe audio files in Label Studio automatically.
- Set up the audio transcription project.
- Validate and export revised audio transcripts from Label Studio.
- Fine-tune a NeMo ASR model with the revised audio transcripts from Label Studio.
Prerequisites
Before you start, make sure that you have the following resources:
- Audio data files. This audio might be recordings of customer service calls, phone orders, sales conversations, or other recorded audio with people talking. The audio files must be in one of the following file formats:
- WAV
- AIFF
- MP3
- AU
- FLAC
- Label Studio installed. Install Label Studio using your preferred method on your local machine or a cloud server. For more information, see Quickstart in the Label Studio documentation.
- NeMo toolkit installed
Free audio data
If you don’t have any audio data in mind, you can use an example dataset or a historical audio dataset:
- The LJ Speech Dataset is a public domain dataset of passages from nonfiction books.
- Librispeech also provides an open-source ASR corpus on Open SLR.
There are a number of other ASR datasets that you can use. For more information, see Datasets — Introduction. You can also use public domain audio recording collections on the Library of Congress website, such as the Sports Byline collection of interviews with American baseball players.
After you identify the audio to transcribe, you can start processing it.
Install Label Studio ML backend
After you install Label Studio, install the Label Studio machine learning backend. From the command line, run the following command:
git clone https://github.com/heartexlabs/label-studio-ml-backend
Set up the environment:
cd label-studio-ml-backend # Install label-studio-ml and its dependencies pip install -U -e . # Install the nemo example dependencies pip install -r label_studio_ml/examples/requirements.txt
Connect the NVIDIA NeMo model to transcribe audio files in Label Studio automatically
To prelabel the data with predictions from a pretrained ASR model, set up the NeMo toolkit as a machine learning backend in Label Studio. The Label Studio machine learning backend lets you use a pretrained model to prelabel your data.
Label Studio includes an example using the pretrained QuartzNet15x5 model developed with NeMo from the NGC cloud, but you can set up a different model with your data if another one is a better fit. For more information, see the list of ASR models available from NeMo.
From the command line, set up NeMo as a machine learning backend and start a new Label Studio project with the model.
- Install the NeMo toolkit in a Docker container or using
pip. - Download a NeMo ASR model. The provided Label Studio example script downloads the pretrained QuartzNet model from the NGC cloud. To use a different model, download that model from NGC.
- From the command line, start the Label Studio machine learning backend.
label-studio-ml init my_model --from label_studio_ml/examples/nemo/asr.py - Start the machine learning backend. By default, the model starts on localhost with port 9090.
label-studio-ml start my_model - Start Label Studio with the model.
label-studio start my_project --ml-backends http://localhost:9090
Set up the audio transcription project
After you start Label Studio, import your audio data and set up the right template to configure labeling. The audio transcription template is the best one for automated speech recognition and makes it easy to annotate the audio data.
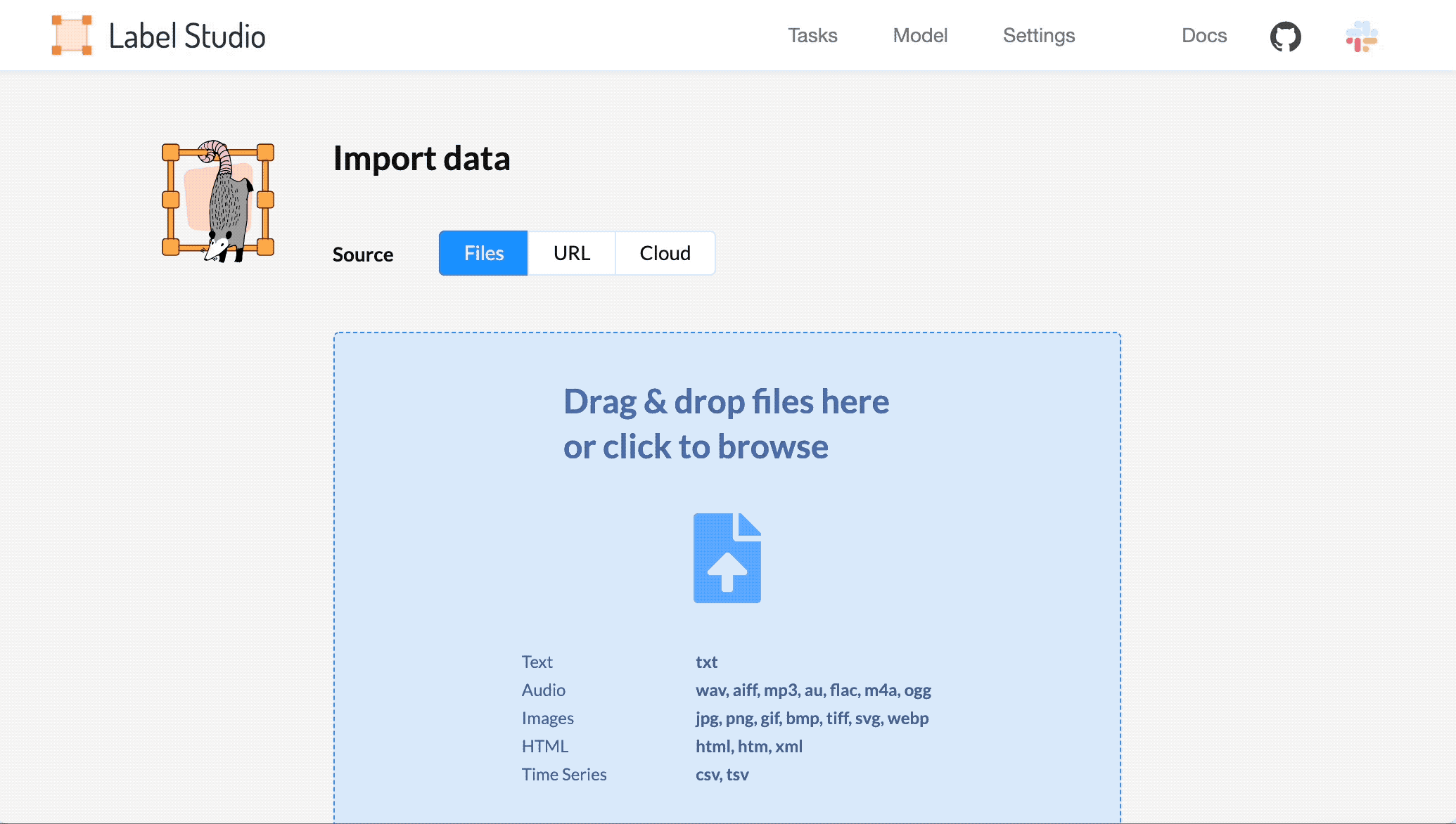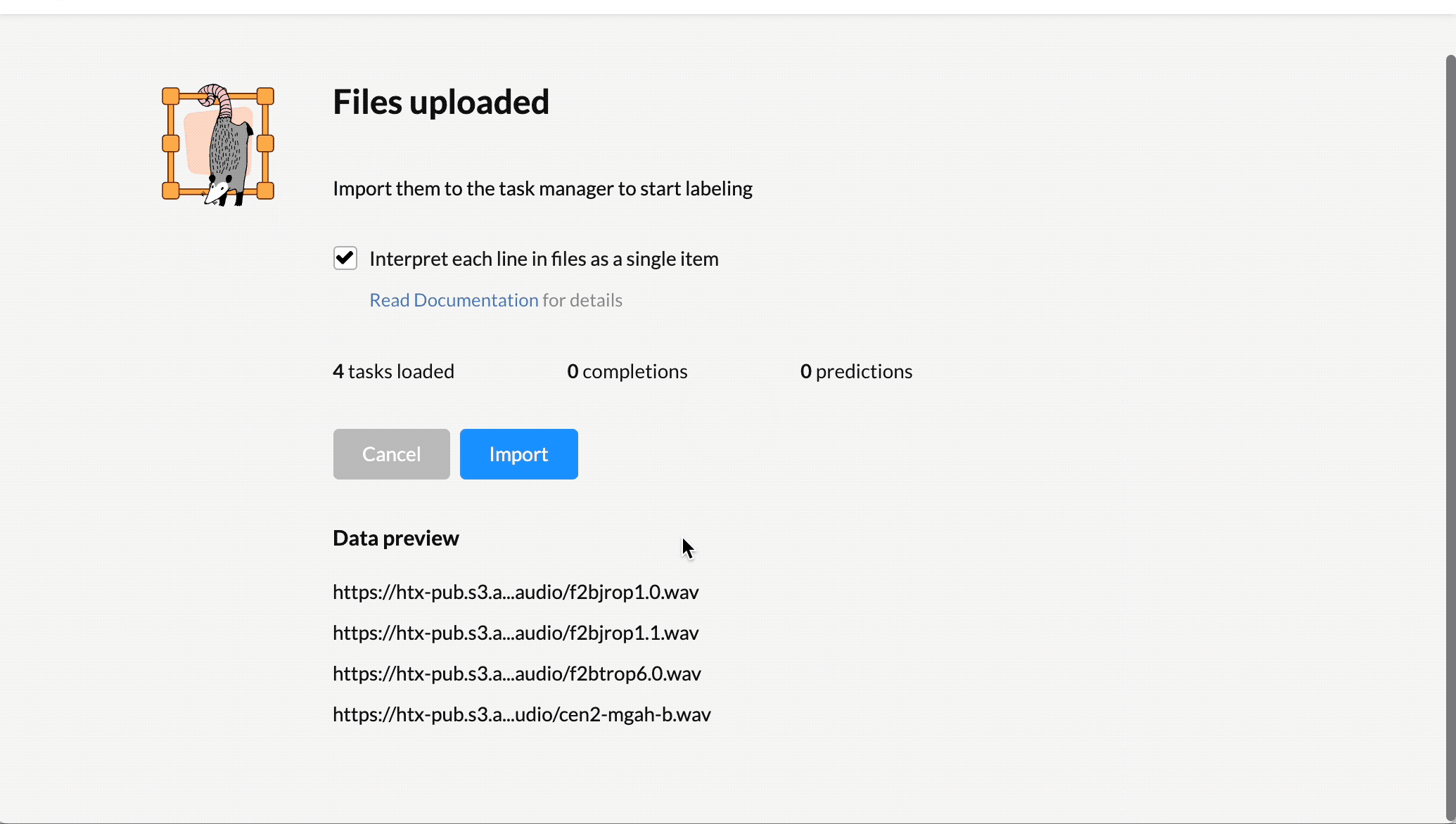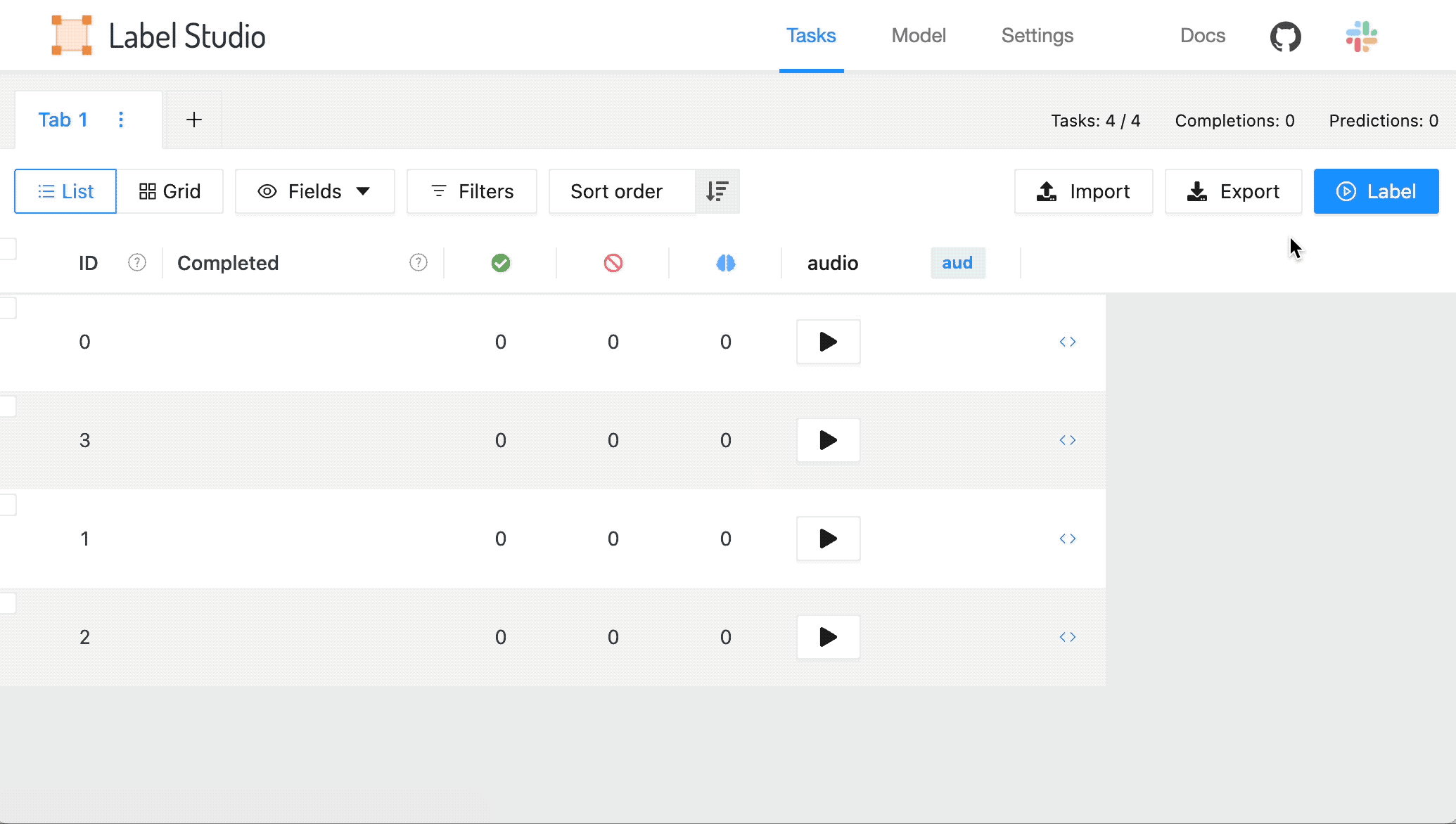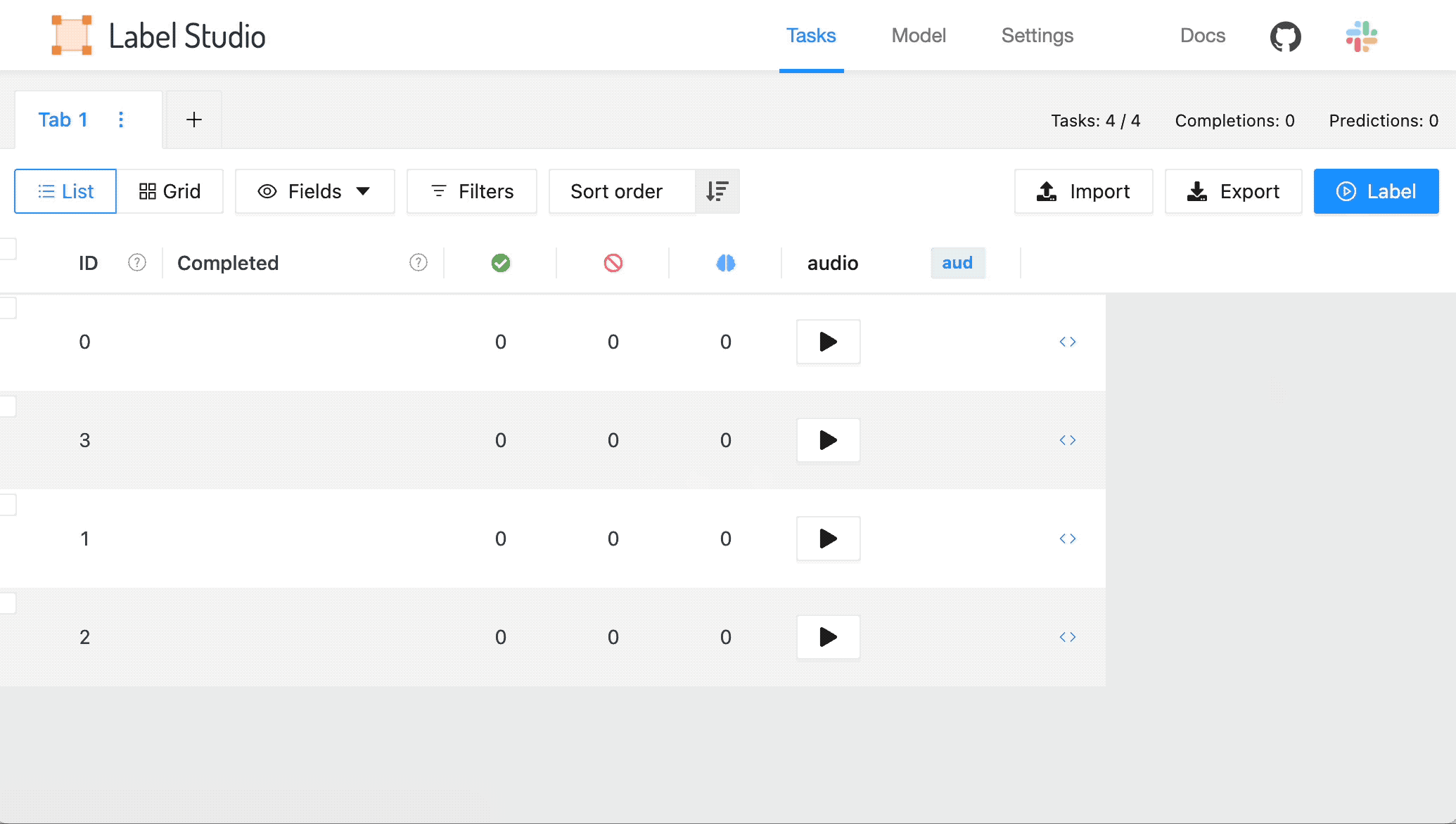
Open Label Studio, import your data, and select the template.
- Choose Import and import your audio data as plain text or JSON files referencing valid URLs for the audio files hosted in online storage such as Amazon S3. For more information, see Get data into Label Studio.
2. From the Tasks list, choose Settings.
3. On the Labeling Interface tab, browse the templates and select the Automated Speech Recognition template.
4. Choose Save.
Validate and output the model predictions
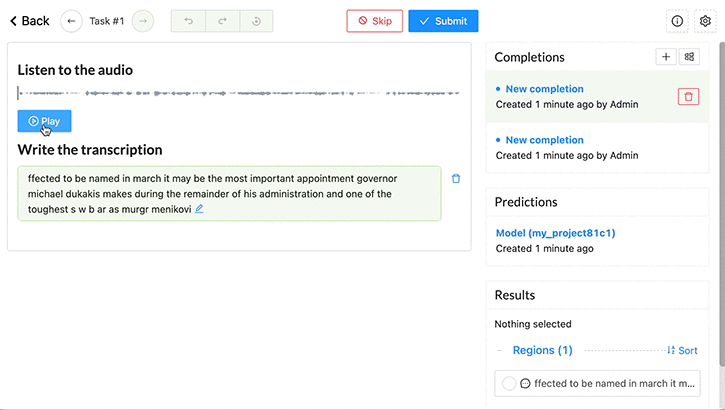
As an annotator, review the tasks for the audio data on the task interface and validate. If necessary, correct the transcript predicted by the NeMo speech model.
- From the list of tasks in Label Studio, choose Label.
- For each audio sample, listen to the audio and review the transcription produced by the NeMo model as part of the prelabeling process.
- If any words in the transcript are incorrect, update them.
- Save the changes to the transcript. Choose Submit to submit the transcript and review the next audio sample.
Next, export the completed audio transcripts from Label Studio in the proper format expected by the NeMo model, as described in NeMo ASR collection in the NVIDIA NeMo documentation.
To export the completed audio, do the following:
- From the list of tasks in Label Studio, choose Export.
- Select the audio transcript JSON format called ASR_MANIFEST.
For more information about the available export formats in Label Studio, see Export results from Label Studio.
Use high-quality transcripts to fine-tune your ML model
When you’re done processing the audio and adjusting the transcribed text, you’re left with audio transcripts that you can use to retrain the ASR models included in NeMo. Label Studio produces annotations that are fully compatible with NeMo training.
To update the QuartzNet model checkpoint, you can do it in a few lines of code, train the model from scratch, or use PyTorch Lightning. Examples are also available in the NeMo Jupyter notebook. For more information, see Transfer Learning in the ASR with NeMo Jupyter notebook.
By using Label Studio and NeMo together, you can save time processing each audio file from scratch. NeMo gives you a highly accurate prediction right away, and Label Studio helps make that prediction perfect. Try it today!
