
This post is the first in a series that shows you how to use Docker for object detection with NVIDIA Transfer Learning Toolkit (TLT). For part 2, see Using the NVIDIA Isaac SDK Object Detection Pipeline with Docker and the NVIDIA Transfer Learning Toolkit.

The modular and easy-to-use perception stack of the NVIDIA Isaac SDK continues to accelerate the development of various mobile robots. Isaac SDK 2020.1 includes support for object detection for robots that must determine the identity and position of objects to perform intelligent operations such as delivering payloads or bin-picking for manufacturing and assembly lines.
One of the difficult aspects of building a reliable perception system is the gathering of diverse, realistically labeled, training data for a specific application. The Isaac SDK approach uses the simulation capabilities of the NVIDIA GPU-powered Isaac Sim to generate photorealistic synthetic datasets and use them for training robust object-detection models.
In this post, we explore how the Isaac SDK can be used to generate synthetic datasets from simulation and then use this data to fine-tune an object detection deep neural network (DNN) using the NVIDIA Transfer Learning Toolkit (TLT). In addition, we show how the Isaac SDK accelerated inference components enable real-time object detection for a factory intralogistics environment.
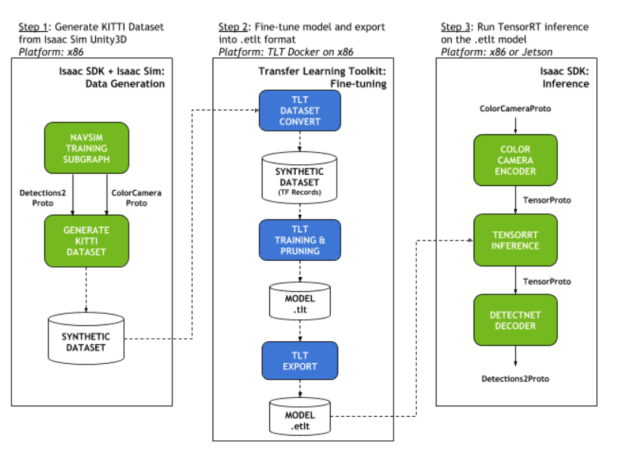
Object detection pipeline with the Isaac SDK
The object detection workflow in the Isaac SDK uses the NVIDIA object detection DNN architecture, DetectNetv2. It is available on NVIDIA NGC and is trained on a real image dataset. Tools integrated with the Isaac SDK enable you to generate your own synthetic training dataset and fine-tune the DNN with the TLT. The fine-tuned DetectNetv2 can then be used for inference in your robotics applications.
Figure 2 shows the overview of the workflow for the following tasks:
- Generate the KITTI dataset from Isaac Sim Unity3D.
- Fine-tune the model and export into the .etlt format.
- Run TensorRT inference on the .etlt model.
The following sections describe each of these steps. For more information, see Object Detection with DetectNetv2.
Generate the dataset
Isaac Sim 2020.1 enables the generation of synthetic, photorealistic datasets by rendering 3D object models in environments that can be customized to look like the target environment where the robot will be deployed.
The advantages of using simulation to create data include the following:
- Automatic labeling—Ground truth bounding boxes are computed per object instance and are used to create the training labels for each sample.
- Procedural generation of large datasets—Randomization is controlled for various simulation aspects, such as lighting, backgrounds, camera angles, occlusions, and image post-processing (temperature, saturation, contrast, and exposure), with infinite combinations. Multiple training scenarios can also be set up to simulate situations corresponding to the robot hardware (sensor mount) and the expected deployment environment.
- Simulation of sensor hardware—Camera settings such as field of view and focal length can be modified to match the sensor hardware mounted on the robot that will run inference.
For more information about the creation of custom scenarios, see Getting Started with Editor Mode.
Figures 3 and 4 show the generation of heavy occlusions for an industrial cart-detection use case and multiple stacked boxes for the box-detection use case. This helps train the networks to be robust to these scenarios. The cart, box, and occlusion/distractor object models are included with Isaac Sim Unity3D as assets.


When a scene is up and running, an Isaac application establishes communication to the simulator and saves the incoming data samples (images and corresponding labels) to the disk. With Isaac 2020.1, the application to save the dataset can be run with the following command:
bazel run packages/ml/apps/generate_kitti_dataset
The generated dataset adheres to the KITTI format, a common scheme used for object detection datasets that originated from the KITTI vision dataset for autonomous driving. This is the synthetic dataset that can be used to train the detection model.
Fine-tune the model
TLT provides a Docker image that packages the commands described in the next few steps. For more information about starting the Docker container and mounting the synthetic dataset, see Object Detection with DetectNetv2.
After the synthetic dataset is generated, the tlt-dataset-convert command digests this data, partitions it into training and validation sets, and converts the data to TFRecords format according to a configuration file.
Then the tlt-train command optimizes the neural network with the help of the training data given by a user-provided specification file. The specification file allows the user to provide training hyperparameters, the model’s input image size, initialization weights, and more. A pretrained DetectNetv2 trained on a real image dataset is provided by TLT and can be used to initialize model weights using the specification file. Because the model will be used to perform inference on images in the real domain on a real robot, the DetectNetv2 weights are initialized using this pretrained model.
Pruning an object detection DNN can significantly speed up inference times for applications designed for edge devices (such as NVIDIA Jetson Nano), which are integral for the deployment of performant robotics applications. Perform pruning using TLT in two steps:
- Using
tlt-pruneto reduce the complexity and size of the neural network (thus possibly losing some accuracy) - Retraining the pruned model with
tlt-trainto regain accuracy on the dataset.
For more information, see Pruning Models with NVIDIA Transfer Learning Toolkit.
The resulting model can then be exported and directly plugged into the Isaac NVIDIA TensorRT pipeline for running accelerated inference. The tlt-export command exports models to the .etlt (“encrypted TLT”) format which requires a decryption key to create a TensorRT engine .plan file. Isaac SDK inference applications consume the model in .etlt format along with the required encryption key and create a platform-specific TensorRT engine file during application runtime.
For more information about how to train and deploy TLT-trained models, see Training with Custom Pretrained Models Using the NVIDIA Transfer Learning Toolkit.
Run inference
The Isaac SDK provides a subgraph for DetectNetv2 inference, which can be dropped into any Isaac application graph that receives image input. The DetectNetv2 inference subgraph performs the following tasks:
- Accepts the image input as a ColorCameraProto message.
- Resizes and encodes it into a TensorProto message with the ColorCameraEncoder message
- Feeds this tensor into the TensorRTInference message.
Finally, the output tensor from the TensorRT inference is decoded using the DetectNetDecoder, written specifically to convert DetectNetv2 output tensors to the Detections2Proto Isaac message. The Detections2Proto message holds bounding box, confidence, and label information that can be passed downstream to other Isaac nodes and visualized in Isaac WebsightServer.
The Isaac SDK includes a sample application that uses this subgraph, which you can run out-of-the-box with any TLT-trained object detection models. With Isaac 2020.1, the sample application for industrial cart inference on camera feed from a Realsense camera can be run with the following command:
bazel run packages/detect_net/apps:detect_net_inference_app -- --mode realsense
For more information about commands to run this sample application, see TensorRT Inference on TLT models. The commands work on various other input sources: Isaac logs, images on disk, or simulations.
Object detection inference for 3D Object Pose Estimation
The Isaac SDK 3D Object Pose Estimation pipeline uses the bounding boxes output from the DetectNet inference subgraph as regions-of-interest for computing 3D poses. Pose estimation is useful for industrial applications, such as the following:
- To autonomously dock a robot under industrial carts carrying payloads.
- To pick-and-place containers from conveyor belts to industrial palettes using a robotic manipulator.

Figure 5 shows inferred bounding boxes that are used by the Isaac 3D Object Pose Estimation framework for the two use cases.
Runtime performance
A pruned, 368×640 single-class DetectNetv2 tennis ball detection model is included with the Isaac SDK as a sample. With the Isaac TensorRT Inference component, this model has following inference times in FP16 inference mode:
| Platform | Inference time (in milliseconds) |
| Workstation with NVIDIA RTX2080 Ti | 1.08 ms |
| Jetson AGX Xavier (Power mode 0) | 10.5 ms |
| Jetson Nano (Power mode 0) | 30.85 ms |
The Kaya object detection application is a sample included with the Isaac SDK that demonstrates how this model is used for inference on a robot-mounted sensor. The application enables Kaya, the Jetson Nano-powered, three-wheeled, holonomic drive, robotic reference platform, to detect tennis balls using Realsense camera input. For more information about how to train your own models and deploy them to Kaya, see Using the NVIDIA Isaac SDK Object Detection Pipeline with Docker and the NVIDIA Transfer Learning Toolkit.

Conclusion
In this post, you learned how to generate a synthetic dataset using Isaac Sim and the Isaac SDK, and how to feed this data into the TLT to train models on custom objects for sim-to-real transfer.
If you want more information, see Using the NVIDIA Isaac SDK Object Detection Pipeline with Docker and the NVIDIA Transfer Learning Toolkit. The post provides an easy way for you to step through the same workflow of generating synthetic data, fine-tuning for a custom dataset, and performing inference used to deploy detection models for industrial applications, such as BMW’s intralogistics use cases.
For more information, see the following resources:
- Download Isaac SDK 2020.1
- NVIDIA Isaac Documentation
- NVIDIA Isaac: Sample Applications
- GTC Digital: Learn How BMW Uses NVIDIA Technology to Develop the ‘Ultimate Industrial Autonomous Robot
Post your product questions or feedback in the Developer Forums.
