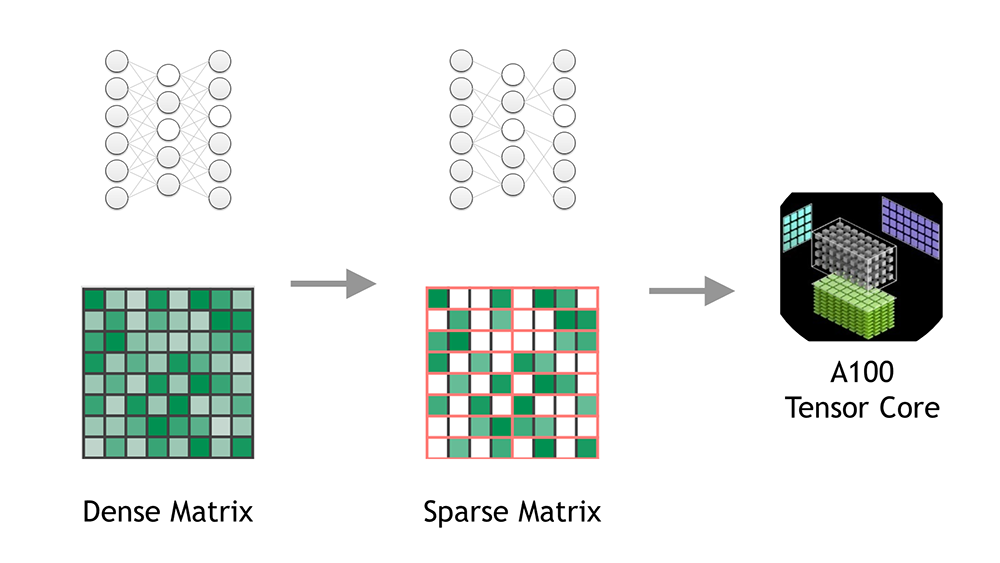
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA TensorRT Acceleration
The training stage of deep learning (DL) models consists of learning numerous dense floating-point weight matrices, which results in a massive amount of...
Accelerating Inference with Sparsity Using the NVIDIA Ampere Architecture and NVIDIA TensorRT
This post was updated July 20, 2021 to reflect NVIDIA TensorRT 8.0 updates. When deploying a neural network, it's useful to think about how the network could...
Exploiting NVIDIA Ampere Structured Sparsity with cuSPARSELt
Deep neural networks achieve outstanding performance in a variety of fields, such as computer vision, speech recognition, and natural language processing. The...
Organizations of all kinds are incorporating AI into their research, development, product, and business processes. This helps them meet and exceed their...
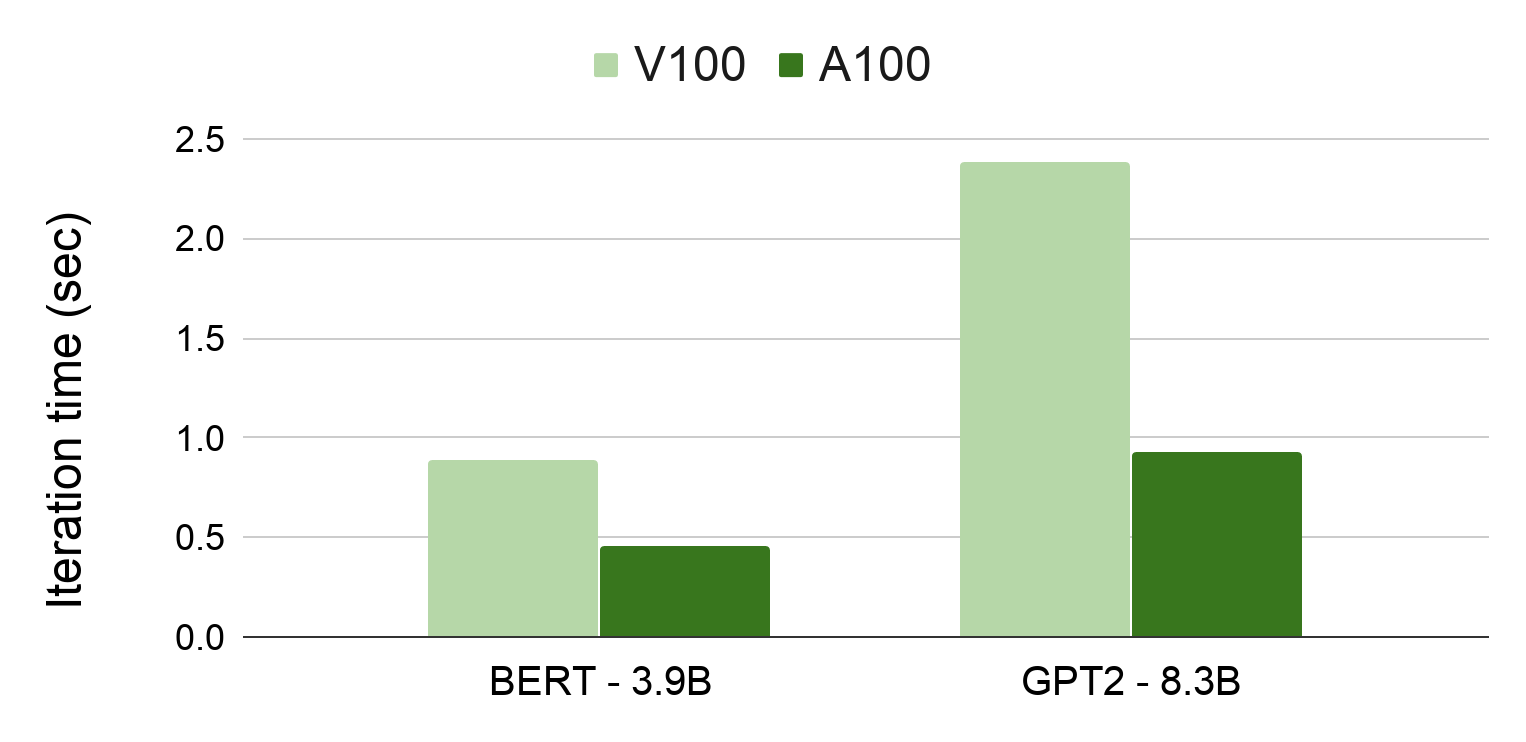
State-of-the-Art Language Modeling Using Megatron on the NVIDIA A100 GPU
Recent work has demonstrated that larger language models dramatically advance the state of the art in natural language processing (NLP) applications such as...
Today, during the 2020 NVIDIA GTC keynote address, NVIDIA founder and CEO Jensen Huang introduced the new NVIDIA A100 GPU based on the new NVIDIA Ampere GPU...