
Looking to reveal secrets of days past, historical scholars across the globe spend their life’s work translating ancient manuscripts. A team at the University of Notre Dame looks to help in this quest, with a newly developed machine learning model for translating and recording handwritten documents centuries old.
Using digitized manuscripts from the Abbey Library of Saint Gall, and a machine learning model that takes into account human perception, the study offers a notable improvement in the capabilities of deep learning transcription.
“We’re dealing with historical documents written in styles that have long fallen out of fashion, going back many centuries, and in languages like Latin, which are rarely ever used anymore. You can get beautiful photos of these materials, but what we’ve set out to do is automate transcription in a way that mimics the perception of the page through the eyes of the expert reader and provides a quick, searchable reading of the text,” Walter Scheirer, senior author and an associate professor at Notre Dame said in a press release.
Founded in 719, the Abbey Library of Saint Gall holds one of the oldest and richest library collections in the world. The library houses approximately 160,000 volumes and 2,000 manuscripts, dating back to the eighth century. Hand-written on parchment paper in languages rarely used today, many of these materials have yet to be read—a potential fortune of historical archives, waiting to be unearthed.
Machine learning methods capable of automatically transcribing these types of historical documents have been in the works, however challenges remain.
Up until now, large datasets have been necessary to boost the performance of these language models. With the vast number of volumes available, the work takes time, and relies on a relatively small number of expert scholars for annotation. Missing knowledge, such as the Medieval Latin dictionary that has never been compiled, poses even greater obstacles.
The team combined traditional machine learning methods with the science of visual psychophysics, which studies the relationship between the physical world and human behavior, to create more information-rich annotations. In this case, they incorporated the measurements of human vision into the training process of the neural networks when processing the ancient texts.
“It’s a strategy not typically used in machine learning. We’re labeling the data through these psychophysical measurements, which comes directly from psychological studies of perception—by taking behavioral measurements. We then inform the network of common difficulties in the perception of these characters and can make corrections based on those measurements,” Scheirer said.
To train, validate, and test the models the researchers used a set of digitized handwritten Latin manuscripts from St. Gall dating back to the ninth century. They asked experts to read and enter manual transcriptions from lines of text into custom designed software. Measuring the time for each transcription, gives insight into the difficulty of words, characters, or passages. According to the authors, this data helps reduce errors in the algorithm and provides more realistic readings.
All of the experiments were run using the cuDNN-accelerated PyTorch deep learning framework and GPUs. “We definitely could not have accomplished what we did without NVIDIA hardware and software,” said Scheirer.
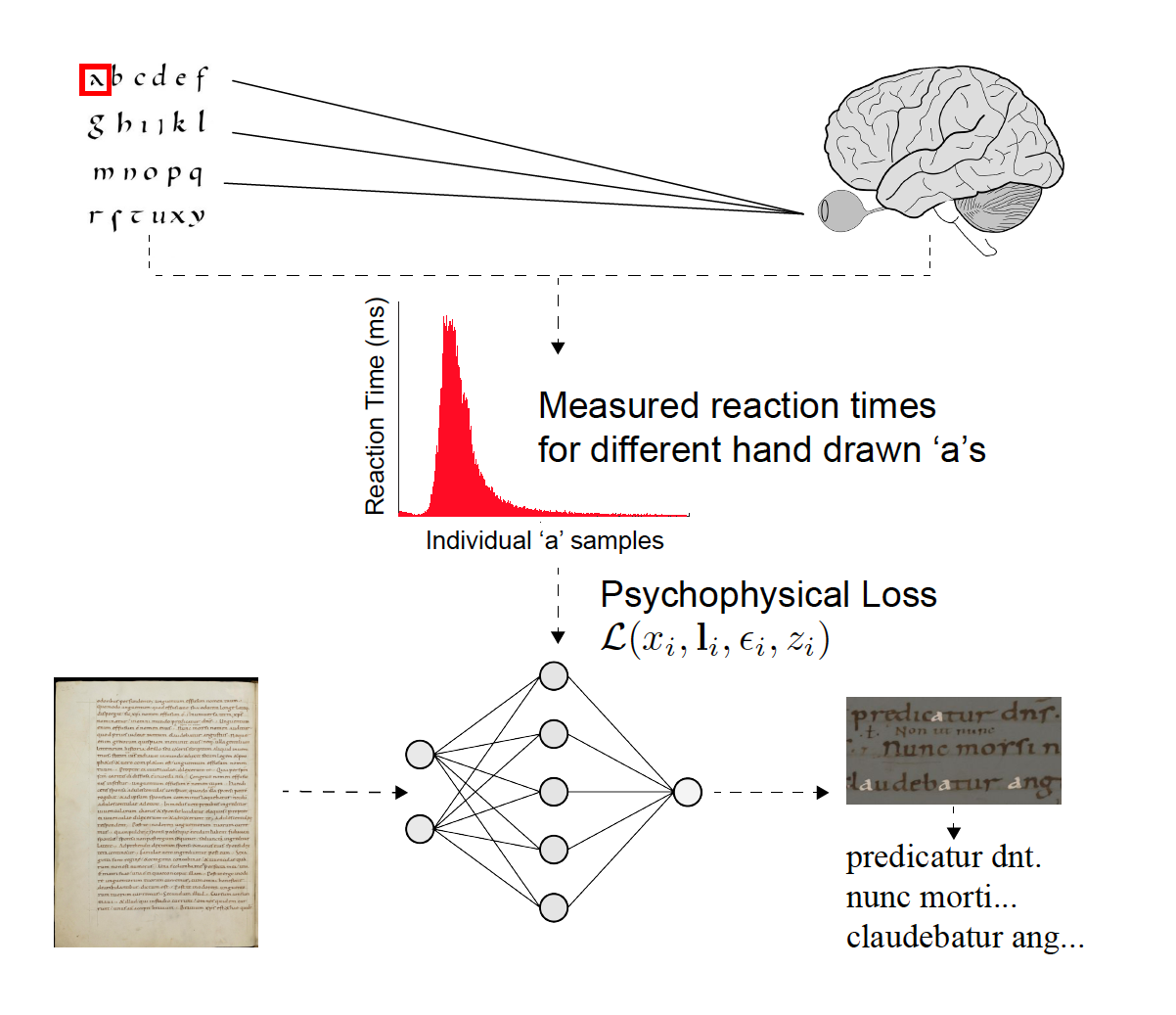
The research introduces a novel loss formulation for deep learning that incorporates measurements of human vision, which can be applied to different processing pipelines for handwritten document transcription. Credit: Scheirer et al/IEEE
There are still areas the team is working to improve. Damaged and incomplete documents, along with illustrations and abbreviations pose a special challenge for the models.
“The inflection point AI reached thanks to Internet-scale data and GPU hardware is going to benefit cultural heritage and the humanities just as much as other fields. We’re just scratching the surface of what we can do with this project,” said Scheirer.
Read the full article in IEEE Transactions on Pattern Analysis and Machine Intelligence >>
Read more >>