This is the second post in the CUDA Refresher series, which has the goal of refreshing key concepts in CUDA, tools, and optimization for beginning or intermediate developers.
Advancements in science and business drive an insatiable demand for more computing resources and acceleration of workloads. Parallel programming is a profound way for developers to accelerate their applications. However, it has some common challenges.
The first challenge is to simplify parallel programming to make it easy to program. Easy programming attracts more developers and motivates them to port many more applications on parallel processors. The second challenge is to develop application software that transparently scales its parallelism to leverage the increasing number of processor cores with GPUs.
In this post, I discuss how CUDA meets those challenges. I also lay out how to get started with installing CUDA.
Introducing CUDA
NVIDIA invented the CUDA programming model and addressed these challenges. CUDA is a parallel computing platform and programming model for general computing on graphical processing units (GPUs). With CUDA, you can speed up applications by harnessing the power of GPUs.
NVIDIA released the first version of CUDA in November 2006 and it came with a software environment that allowed you to use C as a high-level programming language. There are thousands of applications accelerated by CUDA, including the libraries and frameworks that underpin the ongoing revolution in machine learning and deep learning.
Easy to program
For easy adoption, CUDA provides a simple interface based on C/C++. A great benefit of the CUDA programming model is that it allows you to write a scalar program. The CUDA compiler uses programming abstractions to leverage parallelism built in to the CUDA programming model. This lowers the burden of programming. Here are some basics about the CUDA programming model.
The CUDA programming model provides three key language extensions to programmers:
- CUDA blocks—A collection or group of threads.
- Shared memory—Memory shared within a block among all threads.
- Synchronization barriers— Enable multiple threads to wait until all threads have reached a particular point of execution before any thread continues.
The following code example shows the CUDA kernel that adds two vectors, A and B. The output is another vector, C. The kernel code executes on the GPU and is scalar in nature because it adds two vectors in such a way that it looks like adding two scalar numbers.
When this code runs on GPU, it runs in a massively parallel fashion. This is because each element of the vector is executed by a thread in a CUDA block and all threads run in parallel and independently. This simplifies the parallel programming overhead.
/** CUDA kernel device code - CUDA Sample Codes
* Computes the vector addition of A and B into C. The three vectors have the same number of elements as numElements.
*/
__global__ void vectorAdd( float *A, float *B, float *C, int numElements) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements) {
C[i] = A[i] + B[i];
}
}
Easy to scale
The CUDA programming model allows scaling software transparently with an increasing number of processor cores in GPUs. You can program applications using CUDA language abstractions. Any problem or application can be divided into small independent problems and solved independently among these CUDA blocks. Each CUDA block offers to solve a sub-problem into finer pieces with parallel threads executing and cooperating with each other. The CUDA runtime decides to schedule these CUDA blocks on multiprocessors in a GPU in any order. This allows the CUDA program to scale and run on any number of multiprocessors.
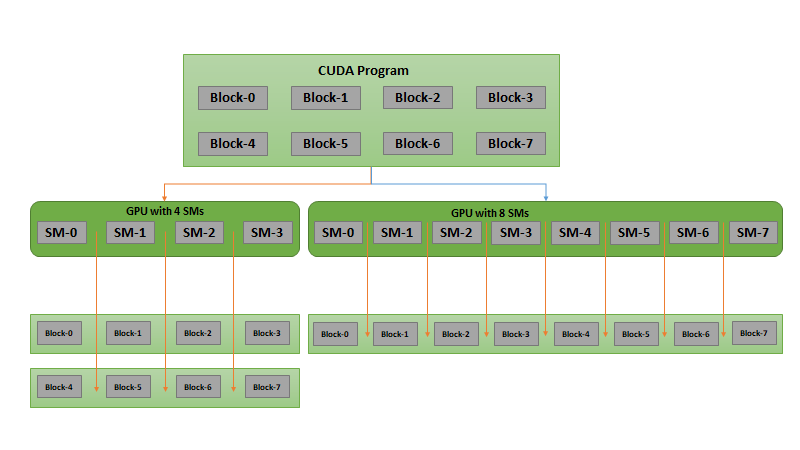
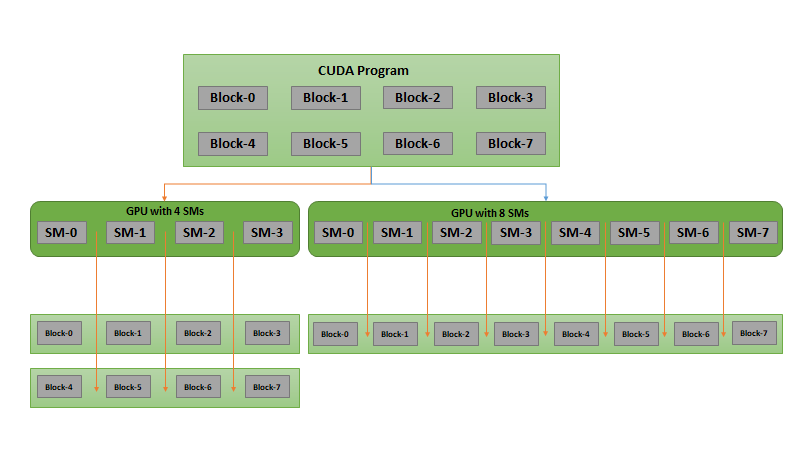
Figure 1 shows this concept. The compiled CUDA program has eight CUDA blocks. The CUDA runtime can choose how to allocate these blocks to multiprocessors as shown with streaming multiprocessors (SMs).
For a smaller GPU with four SMs, each SM gets two CUDA blocks. For a larger GPU with eight SMs, each SM gets one CUDA block. This enables performance scalability for applications with more powerful GPUs without any code changes.
Installing CUDA
Here’s how to get a system ready for CUDA installation. After CUDA is installed, you can start writing parallel applications and take advantage of the massive parallelism available in GPUs.
Here are the requirements for running CUDA on your system:
You need a CUDA-compatible GPU to run CUDA programs. CUDA-compatible GPUs are available every way that you might use compute power: notebooks, workstations, data centers, or clouds. Most laptops come with the option of NVIDIA GPUs. NVIDIA enterprise-class GPUs Tesla and Quadro—widely used in datacenter and workstations—are also CUDA-compatible. Every major cloud provider has GPU-based instances where you can run CUDA programs.
- A supported version of an OS with a GCC compiler and tool chain
For the supported list of OS, GCC compilers, and tools, see the CUDA installation Guides.
- NVIDIA CUDA Toolkit
NVIDIA provides the CUDA Toolkit at no cost. The toolkit includes GPU-accelerated libraries, a compiler, development tools, and the CUDA runtime.
For more information, see the CUDA Programming Guide.
