
Synthetic data isn’t about creating new information. It’s about transforming existing information to create different variants. For over a decade, synthetic data has been used to improve model accuracy across the board—whether it is transforming images to improve object detection models, strengthening fraudulent credit card detection, or improving BERT models for QA.
What’s new? With the advent of large language models (LLMs), both the motivation for generating synthetic data and the techniques for generating it have been supercharged.
Enterprises across industries are generating synthetic data to fine-tune foundation LLMs for various use cases, such as improving risk assessment in finance, optimizing supply chains in retail, improving customer service in telecom, and advancing patient care in healthcare.
Today, Meta released Llama 3.1 405B, their most powerful open LLM that can be used for both batch and online inference. It can also serve as a base to do specialized pretraining or fine-tuning for a specific domain. Given the size of the model and the amount of data it was trained on, it’s well-suited for synthetic data generation.
In this blog post, we’ll cover a few application cases for synthetic data generation and dive deep into one of them.
LLM-powered synthetic data for generative AI
Let’s take a look at a few of the high-level application cases for synthetic data in the generative AI space where you can use the Llama 3.1 405B to get started.
Using LLM-generated synthetic data to improve language models
There are broadly two approaches that are considered for generating synthetic data for tuning models—knowledge distillation and self-improvement.
Knowledge distillation is the process of translating the capabilities of a larger model into a smaller model. This isn’t possible by simply training both models on the same dataset as the smaller model may not “learn” the most accurate representation of the underlying data. In this case, we can use the larger model to solve a task and use that data to make the smaller model imitate the larger one.
Self-improvement involves using the same model to criticize its own reasoning and is often used to further hone the model’s capabilities. Both these approaches can be used to leverage the Llama 405B model to improve smaller LLMs.
Let’s take a look at a few ways how this can be achieved. Training an LLM involves a three-step process: pretraining, fine-tuning, and alignment.
Pretraining: This involves using an extremely large corpus of information to train the model on how the general structure of a language is organized. While for a generic LLM, this is typically done with Internet-scale data, for any domain-specific LLMs, we need to imbue the specifics on that domain (think LLM for geometry, LLM for radiology, and LLM for telco). This is called domain adaptive pretraining (DAPT). Another example of the application of synthetic data in the pretraining stage is the popular Phi-1.5 model, where a large model was used to synthesize data for imbuing logical reasoning at the pretraining stage.
Fine-tuning: Once the model is trained for general language structure, the next step is to fine-tune it for following specific instructions. For example, tuning the model to be better at reading comprehension-type extractive questions, improving logical reasoning, achieving better code generation, and function calling fall under this category. Self-Instruct, WizardCoder, Alpaca, and more employ these techniques to create task-specific fine-tuning data. Refer to this example for curating domain-specific data to learn more.
Alignment: Lastly, we want to ensure that the style and tone of an LLM response align with the user’s expectations, such as sounding conversational, having appropriate verbosity, complexity, coherence, and other user-defined attributes. This can be achieved by using a pipeline that has an instruct model and a reward model. The chat model creates multiple responses and the reward model gives feedback about the quality of the response. This technique falls under the umbrella of reinforcement learning from AI feedback (RLAIF). This notebook will walk you through how the new Llama 405B model together with the NVIDIA 340B Reward model can be used to generate synthetic data for model alignment.
Using LLM-generated synthetic data to improve other models and systems
Since the application space for synthetic data is vast, let’s focus this discussion on LLM-adjacent models and LLM-powered pipelines.
Retrieval-augmented generation (RAG) uses both an embedding model to retrieve the relevant information and an LLM to generate the answer. The embedding model generates a mathematical representation for the semantics of text. We can use LLMs to parse through underlying documents and synthesis data for both evaluating and fine-tuning the embedding model.
Similar to RAG, any agentic pipeline can be evaluated and its component models fine-tuned. This can be achieved by building simulations with LLM-powered agents. These simulations can also be used to study behavioral patterns. Furthermore, personas can be induced into LLMs to generate task-specific data at scale.
Synthetic data to evaluate RAG
To crystalize the discussion above, let’s think through a basic pipeline for one of the use cases discussed above—generating evaluation data for retrieval. Follow along with this notebook.
The primary challenges for curating data for evaluating a retrieval pipeline are:
- Diversity: The questions shouldn’t focus on a single aspect of information or just have extractive questions.
- Complexity: Generated questions should require some reasoning or multiple pieces of evidence to answer the question.
We’ll focus on diversity, but to explore the complexity angle—the key is to find chunks with overlapping points of information. A couple of approaches to finding overlapping information are calculating Jaccard similarity over sentence-level semantics and leveraging long context models to draw correlations across chunks from the same document.
Diversity stems from different perspectives. For example, consider the following passage.
The proposed acquisition of GreenTech Inc. by SolarPower Corporation stands as one of the most notable transactions in the renewable energy sector this year. Valued at $3 billion, the deal aims to combine GreenTech’s cutting-edge battery technology with SolarPower’s extensive solar panel manufacturing and distribution network. The anticipated operational synergies are expected to result in a 20% reduction in production costs and a 15% increase in revenue over the next two years. However, the transaction is under intense scrutiny from regulatory bodies due to potential antitrust concerns. The Federal Trade Commission (FTC) has indicated that the merger could potentially create a monopoly in the renewable energy storage market, potentially stifling competition and innovation.
SolarPower has committed to maintaining GreenTech’s research and development (R&D) center, which employs over 500 scientists and engineers, as an independent entity to preserve its innovative culture. Additionally, all existing employment contracts will be honored, alleviating concerns about potential layoffs. The merger agreement includes a $150 million breakup fee, payable to GreenTech if SolarPower fails to secure the necessary regulatory approvals, thereby mitigating financial risks for GreenTech should the deal fall through.
The agreement includes detailed representations and warranties, specifying the accuracy of financial statements, the absence of undisclosed liabilities, and compliance with applicable laws. It also entails a thorough indemnification process to protect both parties against potential breaches of these representations and warranties. SolarPower and GreenTech have agreed to covenants that restrict GreenTech from incurring new debt, issuing additional shares, or significantly altering business operations without SolarPower’s consent prior to the deal’s closure. These covenants are designed to preserve the value of GreenTech and ensure a smooth transition post-merger. The agreement further outlines a comprehensive due diligence process, including environmental assessments and audits of GreenTech’s intellectual property portfolio, to ensure all assets and liabilities are accurately accounted for before the finalization of the transaction.
The European Commission is also reviewing the merger to assess its impact on the EU market, particularly regarding competition and market dominance. This evaluation involves submitting detailed filings that include market analyses, competitive impact assessments, and economic justifications for the merger. The review process requires both companies to respond promptly to inquiries and provide comprehensive documentation. Additionally, to secure approval, SolarPower and GreenTech may need to make concessions, such as divesting certain business units or assets, to alleviate concerns about reduced competition. Ensuring compliance with the EU Merger Regulation involves not only addressing competitive effects but also ensuring that the merger aligns with broader EU policies on market fairness and consumer protection.
A financial analyst is interested in the financial performance of the two companies before and after the merger. Legal experts may be interested in the legal scrutiny the company has faced from the FTC, EU, and other parties. A journalist would be looking to understand the main points.
All these are valid viewpoints and user personas, and since they approach the same information with different points of view, an evaluation pipeline also needs to accommodate the same. So, let’s design a pipeline that takes in documents and personas and gives out questions in a tone that the persona will ask them in.

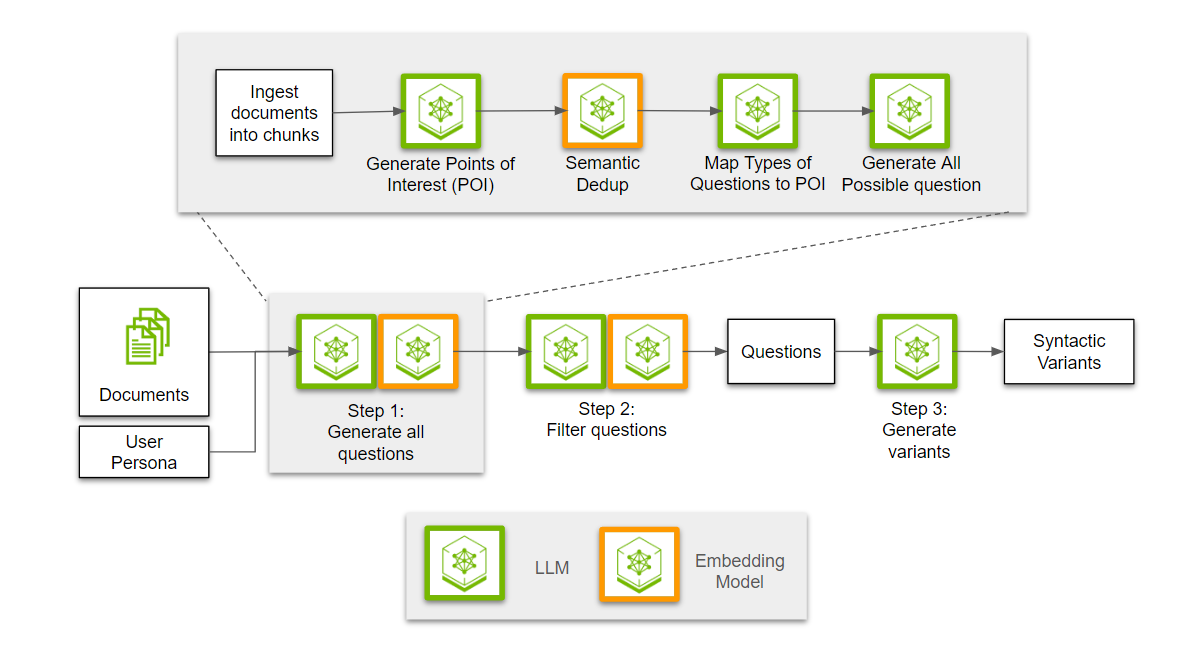
Conceptually, this pipeline has three main steps as seen in Figure 1.
- Step 1: Generate all possible questions, which would be of interest to the personas.
- Step 2: Filter all the generated questions.
- Step 3: Induce the persona’s writing style.
Step 1: Generating questions
Before diving into question generation, we need to ingest the document and create chunks out of it. For the rest of this discussion, let’s use Figure 1 as the reference chunk of text.
User persona is just a description of the user who may be asking the question. Refer to the following examples.
Persona 1
Joan is a very senior financial analyst and focuses on using econometrics to recommend investment strategies. Joan is used to having a team of analysts who they can ask for information, so they may not be up to date with the specifics so they may ask vague questions. However, they are very knowledgeable about the general topic.
Persona 2
Padma is a seasoned corporate litigator with over 10 years of experience in handling complex legal cases for large corporations. She has a no-nonsense approach and is known for her sharp analytical mind and attention to detail.
Persona 3
Aaron is an underconfident journalism major and thus doesn’t probe the underlying material too deeply. He is still new to the English language so doesn’t have that much proficiency. He also has a bad habit of sensationalizing things.
Once ingested, an LLM extracts points of interest from the given chunk for each of the personas. Multiple personas can have similar points of interest, so we use an embedding model to run semantic deduplication. This maps out different interesting pieces of information in a passage.
The other aspect of diversity is the type of questions being asked. We need to ask questions that are extractive, abstractive, comparative, and so on, and not just straight “how/what” questions. To that end, the next step is to identify the types of questions that are applicable to each point of interest given the information in the passage.
Lastly, with the chunk-interest-question type triplet, we generate all possible questions. Directing the questions of generation using personas and types of questions enables developers to steer the questions generated toward the types of questions their users would ask.
Sample areas of interest and types of questions:
- Antitrust regulatory scrutiny: abstractive, diagnostic
- Operational synergies: extractive, abstractive
- Innovation preservation: extractive, abstractive, diagnostic
- EU merger regulation: abstractive, diagnostic, extractive, aggregative
Sample questions:
- What potential risks or drawbacks might arise from the merger between SolarPower Corporation and GreenTech Inc., and how do the companies plan to mitigate them?
- How might the European Commission’s review of the merger impact the terms of the agreement, and what concessions might SolarPower and GreenTech need to make to secure approval?
- What strategic benefits do SolarPower and GreenTech hope to achieve through the merger, and how do they plan to integrate their operations to realize these benefits,
- What are the three main benefits of the proposed acquisition of GreenTech Inc. by SolarPower Corporation, and how do they relate to the company’s operations and finances?
- How many regulatory bodies are reviewing the merger, and what are the specific concerns they are addressing in their evaluations?
- What concessions or divestitures might SolarPower Corporation and GreenTech Inc. need to make in order to secure approval for the merger from the European Commission, and how might these concessions impact the company’s operations and market position?
- What is the primary concern of the FTC regarding the proposed acquisition of GreenTech Inc. by SolarPower Corporation, and how might this problem impact the renewable energy storage market?
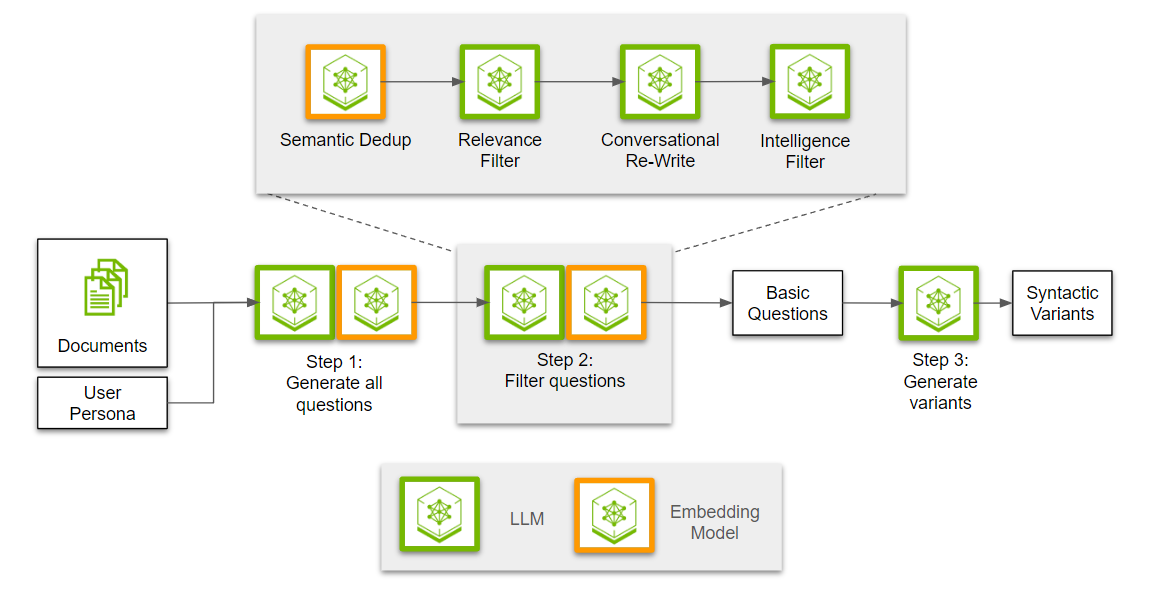
Step 2: Filtering questions
Once the questions are generated, the next step is filtering and extracting the most useful subset. The first step is to deduplicate across all the questions that have been generated. We need a deduplication pass, as different points of interest can make use of adjacent points of information and spawn across overlapping questions.
Next, we use an LLM as a judge to determine the relevance of the question to the underlying passage. With this, we are trying to ensure that the question is completely answerable by the information present in the passage. This is followed up by rewriting all relevant questions to have a conversational tone. Lastly, we have another filter to categorize and filter out questions that may be too general.
Step 3: Imbuing persona style
In the first two steps, we created and curated diverse questions. The final step is to imbue the writing style of the personas with all the questions.

Using LLMs, we first formulate the writing styles from the given persona description. Then using these writing styles, the questions are re-written.
Writing style samples
Padma’s writing style is characterized by clarity, precision, and a formal tone. She writes in a direct and assertive manner, using simple and concise language to convey complex ideas. Her sentences are well-structured and logically connected, reflecting her analytical mind and attention to detail. She avoids using emotional language, personal opinions, or rhetorical flourishes, instead focusing on presenting facts and arguments in a clear and objective manner. Her writing is free of ambiguity and vagueness, with each point carefully supported by evidence and reasoning. The overall tone is professional and authoritative, commanding respect and attention from the reader. While her writing may not be engaging or persuasive in a creative sense, it is highly effective in conveying her message and achieving her goals in a corporate litigation context.
Aaron’s writing is marked by a lack of depth and analysis, often skimming the surface of complex issues. His sentences are short and simple, reflecting his limited proficiency in English. Despite his best efforts, errors in grammar, syntax, and word choice are common. To compensate for his lack of confidence, Aaron often resorts to sensationalism, exaggerating or distorting facts to make them more attention-grabbing. His tone is hesitant and uncertain as if he’s not quite sure of himself. Overall, Aaron’s writing style is more akin to a tabloid journalist than a serious news reporter.
At the end of this three-step pipeline, we end up with questions like:
- In light of the prevailing regulatory framework, what additional policy directives is it likely that the proposed merger will need to conform to secure approval from the relevant authorities?
- What specific aspects of the SolarPower and GreenTech merger are currently under review by the relevant regulatory authorities?
- Will GreenTech’s brainiacs get the boot if the R&D center stays solo after the big buyout?
These questions have implicit ground-truth labels to their specific chunks and can thus be used for evaluating various retrieval pipelines. If you are interested in the granular details or want to learn how to improve and customize this pipeline for your use case, refer to this Jupyter Notebook.
Takeaways
Synthetic data generation is a critical workflow for enterprises to fuel their domain-specific generative AI applications. The new Llama 3.1 405B model, when paired with the NVIDIA Nemotron-4 340B reward model, generates synthetic data, enabling enterprises to build more accurate, domain-specific custom models.
RAG pipelines are critical for LLMs to generate grounded responses based on up-to-date information, and the accuracy of these responses depends on the quality of the pipeline. The synthetic data generation workflow described above can help evaluate the RAG for enterprises.
To get started with Llama 3.1 and NVIDIA Nemotron-4 models, visit ai.nvidia.com.
