The rapid development of solutions using retrieval augmented generation (RAG) for question-and-answer LLM workflows has led to new types of system architectures. Our work at NVIDIA using AI for internal operations has led to several important findings for finding alignment between system capabilities and user expectations.
We found that regardless of the intended scope or use case, users generally want to be able to execute non-RAG tasks like performing document translation, editing emails, or even writing code. A vanilla RAG application might be implemented so that it executes a retrieval pipeline on every message, leading to excess usage of tokens and unwanted latency as irrelevant results are included.
We also found that users really appreciate having access to a web search and summarization capability, even if the application is designed for accessing internal private data. As a example, we used Perplexity’s search API to meet this need.
In this post, we share a basic architecture for addressing these issues, using routing and multi-source RAG to produce a chat application that is capable of answering a broad range of questions. This is a slimmed-down version of an application and there are many ways to build a RAG-based application, but this can help get you going. For more information, see the /NVIDIA/GenerativeAIExamples GitHub repo.
In particular, we highlight how to use LlamaIndex, NVIDIA NIM microservices, and Chainlit to rapidly deploy this application. You can use this project as inspiration for the NVIDIA and LlamaIndex Developer Contest, showcasing innovative uses of these technologies in real-world applications and a chance to win exciting prizes.
We found a tremendous amount of synergy between these technologies. NVIDIA NIM microservices and their LlamaIndex connectors make it effortless to develop LLM applications with self-managed or hosted LLMs. Chainlit and LlamaIndex Workflow events fit together nicely due to their shared event-driven architecture, which makes it easy to provide a user interface with detailed information on the full trace of an LLM response. We outline more of the system details in this post.
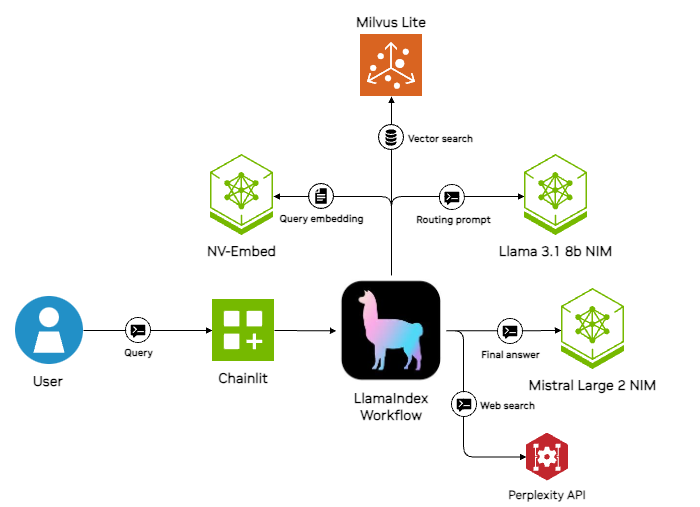
NIM inference microservices for LLM deployment
Our project was built around NVIDIA NIM microservices for several models, including the following:
- Meta’s llama-3.1-70b-instruct
- NVIDIA’s nv-embed-v1 for text embeddings
- Mistral’s nv-rerankqa-mistral-4b-v3 for reranking
Despite not having any machine learning engineers or LLM inference specialists on our team, we requested and deployed our own instance of llama-3.1-70b-instruct using a NIM container running on an NVIDIA A100-equipped node (8 GPUs) in just a few hours. This helped us circumvent issues with availability and latency that we found with some enterprise LLM APIs.
To try out the NIM APIs, sign up for an account at build.nvidia.com and obtain an API key. To use the API key in this project, make sure it is available in a .env file located in the project directory. LlamaIndex connectors for NVIDIA models and APIs are available in the Python package llama-index-llms-nvidia. For more information about the performance benefits for NIM-based LLM deployment, see Optimizing Inference Efficiency for LLMs at Scale with NVIDIA NIM Microservices.
LlamaIndex Workflow events
Our first version of this application was built around LlamaIndex’s ChatEngine class, which provided a turnkey solution for deploying a conversational AI assistant backed by a vector database. While this worked well, we found that we wanted to inject additional steps to augment context and toggle features in a way that required more extensibility.
Fortunately, LlamaIndex Workflow events provided precisely the solution that we needed with its event-driven, step-based approach for controlling an application’s execution flow. We found it much easier and faster to extend our application as Workflow events while still retaining key LlamaIndex functionality such as vector stores and retrievers when necessary.
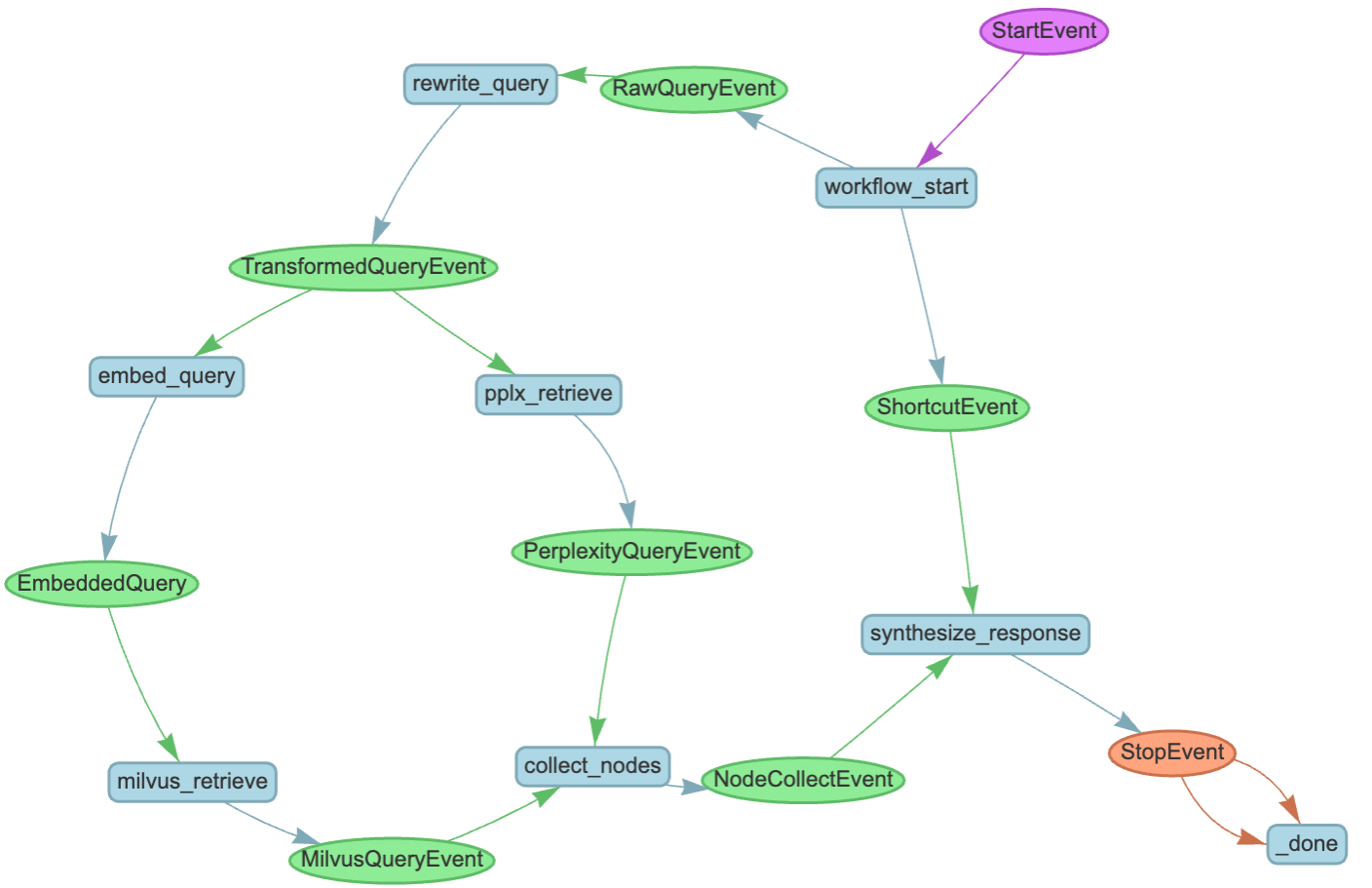
Figure 2 shows our Workflow event, which we explain more about later in this post.
User interface via Chainlit
Chainlit includes several features that helped speed up our development and deployment. It supports progress indicators and step summaries using the chainlit.Step decorator, and LlamaIndexCallbackHandler enables automatic tracing. We used a Step decorator for each LlamaIndex Workflow event to expose the application’s inner workings without overwhelming the user.
Chainlit’s support for enterprise authentication and PostgreSQL data layer was also crucial for production.
Setting up the project environment, dependencies, and installation
To deploy this project, clone the repository located at /NVIDIA/GenerativeAIExamples and create a virtual Python environment, running the following commands to create and activate the environment before installing dependencies:
mkdir .venv
pip -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Configuration
After you’ve installed the dependencies, make sure that you have a .env file located in the top-level directory of the project with values for the following:
NVIDIA_API_KEY: Required. You can get an API key for NVIDIA’s services from build.nvidia.com.PERPLEXITY_API_KEY. Optional. If it is not provided, then the application runs without using Perplexity’s search API. To obtain an API key for Perplexity, follow the instructions.
Project structure
We organized the project code into separate files:
- LlamaIndex
Workflow(workflow.py): Routes queries and aggregates responses from multiple sources. - Document ingestion (
ingest.py): Loads documents into a Milvus Lite database, which is a simple way to start with Milvus without containers. Milvus Lite’s main limitation is inefficient vector lookup so consider switching to a dedicated cluster when document collections grow. The ingestion module uses LlamaIndex’sSimpleDirectoryReaderto parse and load PDFs. - Chainlit application (
chainlit_app.py): The Chainlit application contains functions triggered by events, with the main function (on_message) activating on user messages. - Configuration (
config.py): To play around with different model types, edit the default values. Here, you can select different models for routing and chat completion as well as the number of past messages used from chat history for each completion, and the type of model used by Perplexity for web search and summarization.
You can also tweak the prompts listed in prompts.py to fit your use case.
Building the core functionality
This application integrates LlamaIndex and NIM microservices via Chainlit. To show how to implement this logic, we’ll work through the following steps:
- Creating the user interface
- Implementing the
Workflowevent - Integrating NIM microservices
Creating the user interface
Here’s how this project is implemented, beginning with the Chainlit application in chainlit_app.py. Create a list of Starter objects in the set_starter function to prepopulate initial questions as clickable buttons. These help guide users on possible actions or questions and can route them to specific features.
The main chat functionality, managed in the main function, handles message history using the cl.user_session variable. This isn’t required for Chainlit to show conversation history but enabled us to keep state on the client side rather than within LlamaIndex objects.
This approach made prototyping more straightforward and facilitated transitioning to a traditional user-frontend-backend application, unlike the stateful LlamaIndex ChatEngine, which complicates REST API deployment.
When the Workflow is invoked using workflow.run, a series of asynchronous function calls is triggered through the Workflow, which requires only the current user query and the past chat messages as inputs. When a streaming response is generated, use the stream_token method on Chainlit’s Message class to show it in the user interface. We also added a small amount of HTML with styling to show the token count and time elapsed.
Implementing the Workflow event
The RAG logic is contained within the QueryFlow class in workflow.py, composed of multiple steps defined as methods of QueryFlow. Each method is triggered when the events in its signature occur. Passing lists of nodes between steps using the nodes attribute was an easy way to structure the Workflow. A node represents a discrete unit of information within LlamaIndex.
Here are the Workflow steps:
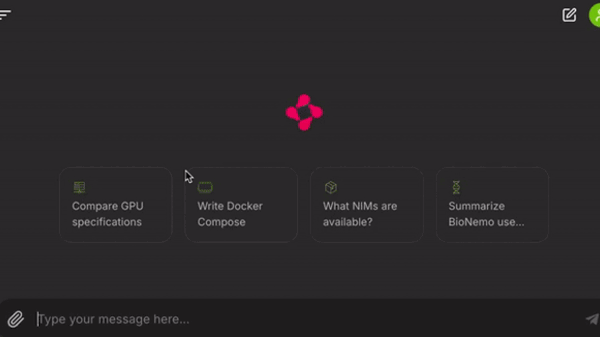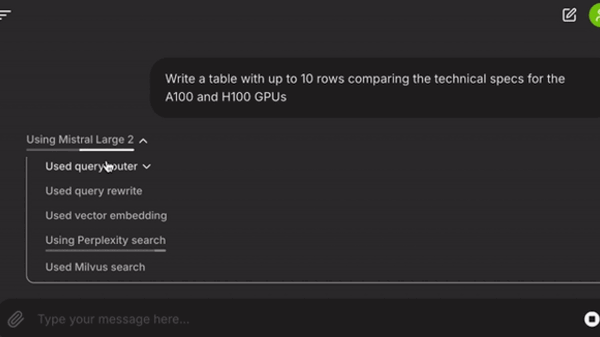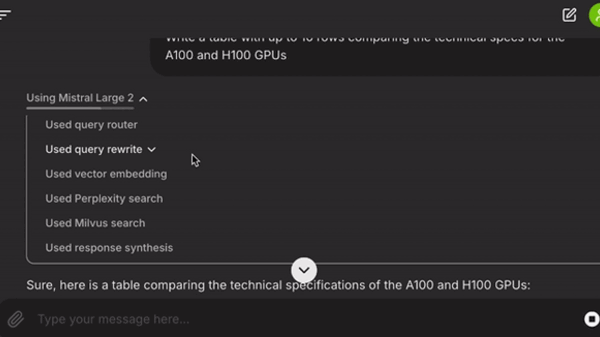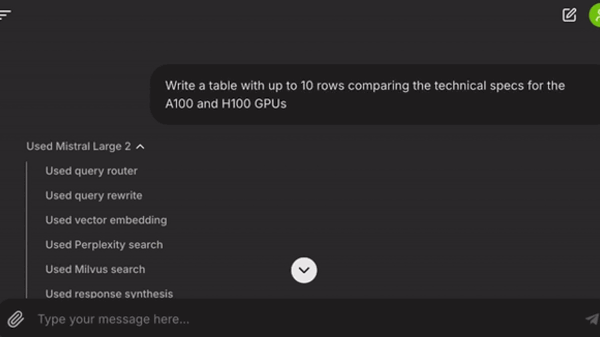
workflow_start: Adds the user query and chat history to the workflow’s context (ctx.data) and routes between RAG and non-RAG queries usingLLMTextCompletionProgram. Depending on the result, it generates eitherRawQueryEvent(triggers RAG logic) orShortcutEvent(triggers immediate response synthesis).rewrite_query: Transforms the user’s query for better search results by removing instruction keywords like “email” and “table” that can hinder document lookup. It triggers TransformedQueryEventfor the Milvus retrieval and Perplexity search steps.embed_query: Produces a vector embedding for the transformed query.milvus_retrieve: Uses the vector embedding for a vector search.pplx_retrieve: Uses the LlamaIndex connector for the Perplexity search API to get web search results, summarized as a single node.collect_nodes: Combines results from Milvus and Perplexity retrievals. This step triggers once both retrieval events are completed. Adding a reranker here could prioritize high-value nodes.
ready = ctx.collect_events(
qe,
expected=[
MilvusQueryEvent,
PerplexityQueryEvent,
],
)
if ready is None:
logger.info("Still waiting for all input events!")
return None
response_synthesis: Builds a prompt string with past chat history context and retrieved documents. We manually form this string, though LlamaIndex templating could also be used. This step triggersStopEvent, ending theWorkflowevent and returning a response to the Chainlit application by generatingCompletionResponseobjects for each token produced by the LLM.
To summarize, a user’s query first goes through a routing step in which the LLM decides if it is worthwhile to use retrieval to look up documents to answer the query. If not, a follow-up completion call is used to produce an answer.
This branch is triggered when users want to use the LLM to perform tasks that don’t need retrieval, such as editing an email or summarizing a passage of existing text. If retrieval is selected, the user’s query is transformed into a more search-appropriate form. This is then used for vector lookup of ingested documents using the NVIDIA embedding model as well as a Milvus vector store.
The texts returned from these steps are then augmented with the results of a search using Perplexity’s API, which can find data from the web to form its answers. Finally, these results are used for response synthesis. Figure 2 shows the diagram generated using llama-index-utils-workflow.
Integrating NIM microservices
Using NVIDIA NIM microservices for LLM and embedding functionality was quick, thanks to the connectors available from the llama-index-llms-nvidia and llama-index-embeddings-nvidia packages.
As there’s a range of models available from build.nvidia.com, we could pick the small, fast-executing model Meta’s meta/llama-3.1-8b-instruct for routing queries while also using a larger model, Mistral’s mistralai/mistral-large-2-instruct with superior reasoning abilities to produce the final response.
Another good choice for a high-performing, large model would be Meta’s meta/llama-3.1-405b-instruct.
A great advantage for using NIM microservices is that if you want to move to an on-premises or self-managed LLM inference deployment, there are no code changes required beyond setting the base_url parameter for the LLM creation. Otherwise, it’s identical!
You can toggle between the NVIDIA inference public-facing APIs documented at build.nvidia.com or a self-managed Llama 3.1 deployments. This gives a great deal of flexibility to try several models for prototyping before deciding what type of NIM microservice that you want to manage and deploy yourselves.
Extra features
While some of these are beyond the scope of this post, here are a few more features that are easy to add on to enhance value:
- Multimodal ingestion by using vision-language models (VLMs) to read tables, perform optical character recognition, and caption images. You can find many of these at Vision Language Models.
- User chat history with Chainlit’s Postgres connector. To persist user conversations, you can supply PostgreSQL connection details to Chainlit using the functionality of
chainlit.data_layer. - RAG reranking with the NVIDIA Mistral-based reranker.
- Adding citations by prompting the LLM to use HTML styling to show hyperlinked citations with answers.
- Error handling and timeout management to enhance reliability. While APIs like Perplexity are powerful for answering a broad range of queries, their execution time can be highly variable due to the complexity of the underlying components involved. Setting reasonable timeouts and gracefully recovering when such answers are not available rapidly is an important step towards a production-ready application.
Explore advanced chat functionality with the NVIDIA and LlamaIndex Developer Contest
We hope this post has been a useful resource for you as you learn more about generative AI and the ways that NIM microservices and LlamaIndex Workflow events can be used together for the fast development of advanced chat functionality.
If you’re inspired by this project, consider participating in the NVIDIA and LlamaIndex Developer Contest to build your own AI-powered solutions for a chance to win cash prizes, an NVIDIA GeForce RTX 4080 SUPER GPU, DLI credits, and more.
If you’re interested in learning more or exploring similar applications, consider diving into the code here, or experiment with other similar reference applications from the GenerativeAI Examples repo on GitHub.
