
Wherever you look these days, you can find AI affecting your life in one way or another. Whether it’s the Netflix recommendation system or self driving cars, the use of deep learning is becoming ever more prevalent throughout our lives and is starting to make increasingly more crucial decisions. Since AI is becoming ingrained in our lives, you’d expect it to be safe and fool proof, right? Well, that’s not necessarily the case. The potential exists for bad actors to trick deep learning systems into misinterpreting the input on purpose causing it to give a wrong answer. We present a method for preventing these intentional misclassifications to help maintain trust in complex AI systems.
Shortly after Alexnet brought neural networks back into the main stream in 2012 [Krizhevsky et al. 2012 ], people were immediately beginning to find ways to manipulate the fundamental structure of these tools. The first well known case of this came from Ian Goodfellow and team after they discovered an odd quirk in the behavior of neural networks while studying it’s application to computer vision. Their findings showed that if you perturb the pixel values in an image in such a way that it’s imperceptible to the human eye, you can cause a misclassification with the neural net, which assigns a high probability to this new class.
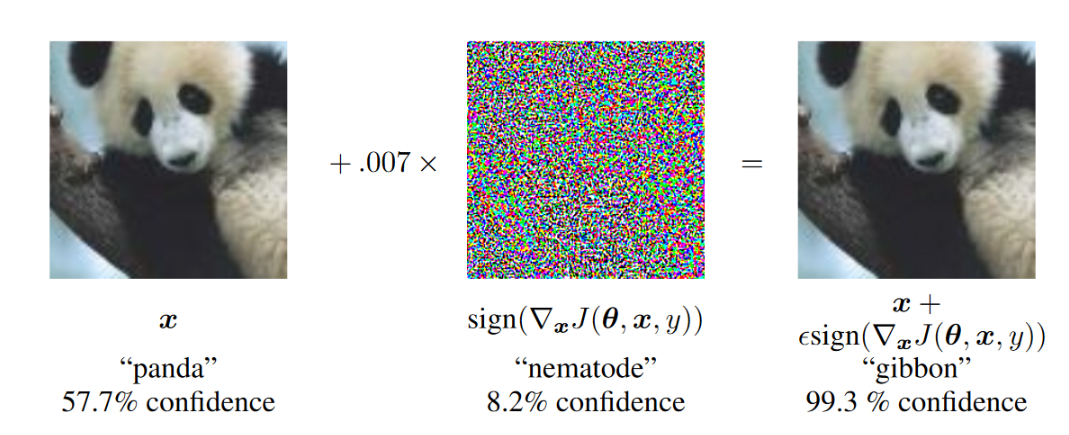
For example, if a neural net was created to classify cats and dogs and given an image of a dog that was perturbed, the neural net would assign a high probability to class cat while it still looked like the original dog to a human) [Szegedy et al. 2013]. This can be seen in figure 1 below where the original image, the perturbations themselves, and the final combined image can be seen next to one another. They termed this phenomena ‘adversarial examples’ and it has since expanded from just computer vision to every application of neural networks, such as audio detection.

These attacks work so well because they take advantage of neural networks linearity in high dimensional spaces, finding the right set of pixels to change to be able to push the classification over the classifier’s decision boundary. They also have a peculiar transferability property that allows the adversarial examples to be effective on neural networks trained on a similar dataset (i.e both datasets were facial recognition datasets, but not necessarily the same faces).
The same optimizations tools developed to help us train neural nets can be used to implement adversarial attacks with relative ease. This has made research into new attacks fast and efficient, so a cat-and-mouse game has developed in building new defenses and then defeating them with new attacks.
In the rest of this article you’ll learn about defenses that currently work, such as adversarial training, as well as some of the defenses that were thought to be cutting edge, but were later defeated, such as gradient masking. You’ll also get an understanding of some of the attacks that exist out there to defeat these defenses, such as BPDA and EOT. Finally, you’ll be introduced to our new defense, called the Barrage of Random Transforms, that seems to be quite promising compared to its predecessors. The hope is that you walk away from this post having a better understanding of the threats that current AI systems face so you can begin building your systems with a security oriented mindset!
Defenses against Adversarial Examples
A multitude of research exists into ways to prevent these sorts of attacks on neural networks. Much of this work focuses around images where the answer, visually, is clearly “panda”, but the network is very confident with the label “gibbon” (see Figure 2 below). This helps motivate why this is such a problem, especially when considering future applications like self-driving cars, a common motivator for research in this field. So, how can you defend against such attacks?
One of the most well known methods is called adversarial training, first implemented by Ian Goodfellow and team in their original paper on the subject [Szegedy et al. 2013]. This fairly straightforward method takes adversarial examples trained on your neural network and adds them to the training dataset for the network to be further trained on. Since adversarial training requires generating new attacks at every training step and strong attacks take multiple iterations, applying it can increase training time by orders of magnitude. While adversarial training has been found to be state-of-the-art for many tasks [Athalye et al. 2018], it does not seem to scale to larger problems like ImageNet [Kurakin et al. 2017].
Since this work focuses on images, an alluring idea is to first run the input through an image transform \(\hat{x}=t(x)\), and then classify \(\hat{x}\). Maybe add some blurring, zooming, or wavelet denoising to try and wash away all those small perturbations? This would allow us to apply our domain knowledge (i.e., that we are working on images, and images can be altered without changing their meaning) to help solve the problem. However, Anish Athalye, Nicholas Carlini, and David Wagner recently showed that the “success” of these defenses was a result of gradient masking or stochastic gradients, and showed how to circumvent such problems to defeat the defenses.
In this game of security, both attacker and defender rely on gradient descent to learn. The gradient gives the defender information about how to improve the model; the same gradient tells the attacker how to trick the model! Gradient masking occurs when the defender attempts to hide the gradient from the attacker, often by using a non-differentiable transform or technique. If you can’t differentiate, there is no gradient for the attacker to use! A particular type of gradient masking, known as shattered gradients, makes the defense gradient either non-differentiable, non-existent, or just wrong.
This defense approach worked at first but was eventually defeated by an attack known as Backward Pass Differentiable Approximation (BPDA). To better understand this method, assume that the transform \(f(x)\) that’s masking the gradients is relatively simple; if the image was altered too much no one would be able to predict it correctly. If a gradient from \(f(x)\) is unattainable, you can define a new network \(g(x)\), and train a neural network to approximate \(f(x)\). If \(f(x) \approx g(x)\), then you should also expect \(\nabla_{x} f(x) \approx \nabla_{x} g(x)\). Since the attacker built \(g(x)\), they have no problem getting its gradient \(\nabla_{x} g(x)\), and using that to replace \(\nabla_{x} f(x)\) when running their optimizer. The BPDA network used in this paper is shown in Figure 3 below. In many cases, you don’t even need to train a new network \(g(x)\)! Because \(f(x) \approx x\), a simple approximation of \(\nabla_{x} f(x) \approx \nabla_{x} x = 1\) is often good enough!

Stochastic gradients, another form of gradient masking, randomizes the gradient through the application of arbitrarily ordered transformations to the data in pre-process. After initially being successful, this also proved easily defeated by an attack known as Expectation Over Transform (EOT). This method takes the expected value of the transformations to determine a viable gradient to be used in the attack. This fairly simple method takes the average gradient over many example transformations, and uses the average gradient instead of any individual gradient. This captures information about all the possible transforms, and allows EOT to circumvent such defenses
Our Defense: The Barrage of Random Transforms (BaRT)
The general goal is to find a transformation that can be effective against such strong attacks as BPDA and EOT. The method described here goes beyond using a single defense. Instead, what if you combined dozens of individually weak defenses, could you form a single strong defense? What if you barraged the attacker with a slew of random transforms? While each individual transform could be easily defeated, their combination would be difficult to circumvent. This Barrage of Random Transforms (BaRT) proves to be 24x more accurate than past defenses with a Top-5 accuracy of up to 57.1% while under attack, as shown in table 1.
| Model | Clean Images | Attacked | ||
| Top-1 | Top-5 | Top-1 | Top-5 | |
| Inception v3 | 78 | 94 | 0.7 | 4.4 |
| Inception v3 w/adv. training | 78 | 94 | 1.5 | 5.5 |
| ResNet50 | 76 | 93 | 0.0 | 0.0 |
| ResNet50-BaRT, k=5 | 65 | 85 | 16 | 51 |
| ResNet50-BaRT, k=10 | 65 | 85 | 36 | 57 |
Since a plethora of image transforms have already been tested, we used a convolutional neural network (CNN) on the Imagenet dataset as the backbone of the experiment. Previous work showed that such an ensembling method of defenses could be broken for a small number of transforms (<= 3). This project attempted to prove the previous notion wrong by using an unheard of 25 total transformations.
These included transforms such as color precision reduction, noise injection, FFT perturbation, and several other groupings of similar transforms. We tested each defense individually, confirming that we can defeat any of them with 100% reliability. Then we selected transforms randomly, up to 10 at a time, for each image before being passed on to the CNN to be classified.
While the randomness hurts the accuracy when not under attack, it gives more robustness in the worst-case scenario of a strong and powerful adversary. Check out the video below to see for yourself how all the transformations stacked up can wildly alter the image, while still keeping it’s essence the same. The attacker now has the much more challenging task of finding a single perturbation that could survive all of the possible transformations!
This makes BaRT particularly useful in thwarting targeted attacks. The adversary has the goal of tricking the neural network into making a specific error in a targeted attack (e.g., calling a stop sign a 60 MPH sign). Figure 4 shows that the attacker gets reduced down to a 0% success rate if 10 transforms are applied, meaning the attacker can’t fool this defense into making arbitrary errors.

The computational burden placed on the adversary is another factor in favor of this defense. While using several transforms took a few hundred milliseconds per image, the attacker’s cost grew disproportionately. Running all the attacks against BaRT took almost a year of DGX compute time. While this isn’t impossible for people to replicate, it harkens to ideas from cryptography. The goal isn’t to make it so there’s provably no possible way to defeat the defense, but to make the cost so insurmountable that they could or would never try.
It’s important to make sure the network is up against the strongest possible adversary when evaluating a new defense. We’ve tried hard to account for every known obfuscated gradient and to include all the best attack practices (given the high cost to perform them!). We’ve also performed more experiments to improve the accuracy of BaRT, and you can find all the details in our CVPR paper.
The only way we could test all of our defenses in an efficient and timely manner throughout this project was by taking advantage of the power of NVIDIA’s GPUs. Using one of NVIDIA’s compute clusters enabled us to run hundreds of jobs, each with 4 32 GB V100s. Given the nature of deep learning tasks, this would take exponentially longer time to run on CPUs. Since the GPU hardware is designed and optimized to run these sorts of algorithms, runtimes proved considerably shorter. Because of the power of NVIDIA GPUs, we were able to push the number of EOT iterations far past anything seen in the literature to an unheard of 40 iterations of attack. We also took advantage of the free NVIDIA GPU Cloud (NGC) services to pull the latest and most up to date pytorch docker containers, which are also optimized on the software level to work best with NVIDIA GPUs, making things run as quickly as possible.
Conclusion
By being a little clever about how we apply domain knowledge, we’ve been able to produce a strong defense against adversarial attacks. In the short term this could have significant value for vulnerable systems, and gives intuition towards more general purpose techniques.
We encourage others working on adversarial attacks to consider them in the context of specific domains. Not every application of machine learning will need to be considered with this challenge; the severity and nature of attacks remain domain dependent. Looking within the field of spam and malware detection as an example, there’s no need to worry about the average user on your network purposefully trying to get their emails caught by spam filters or companies trying to get flagged by anti-virus products. The only worries are spam and malware authors attempting to evade detection. Using domain knowledge, we built a “non-negative network” which exploited the fact that attacks were one-way (spam wants to become benign) so that simple attacks of adding “normal” content would no longer trivially evade detection [Fleshman et al. 2019].
At the same time, we also are looking forward to the new attacks against BaRT! It would be foolish of us to expect perfection, and the knowledge we all gain from the cat-and-mouse game will ultimately improve our defenses, but also help grow our understanding of deep learning as a whole.
We hope this post has enlightened the deep learning community to the possible threats that AI systems face, as well as inspires them to take AI security into consideration when building out their projects. This subject is incredibly important and we would love to hear how you are applying security to your deep learning systems.
Additional Credits
The work and paper described in this blog post was completed in collaboration with Edward Raff, Jared Sylvester, and Mark McLean who collectively represent the Laboratory for Physical Sciences, Booz Allen Hamilton and University of Maryland, Baltimore County.
References
[Krizhevsky et al. 2012 ] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “ImageNet Classification with Deep Convolutional Neural Networks.” Neural Information Processing Systems Conference (NeurIPS), 2012.
[Szegedy et al. 2013] Szegedy, Christian, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus, Intriguing properties of neural networks. arXiv:1312.6199, 2013.
[Goodfellow et al. 2015] Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. “EXPLAINING AND HARNESSING ADVERSARIAL EXAMPLES.” International Conference on Learning Representations (ICLR), 2015.
[Yuan 2016] Jiangye Yuan, Automatic Building Extraction in Aerial Scenes Using Convolutional Networks, arXiv:1602.06564, 2016.
[Pinheiro et al. 2016] SharpMask: Learning to Refine Object Segments. Pedro O. Pinheiro, Tsung-Yi Lin, Ronan Collobert, Piotr Dollàr (ECCV), 2016.
[Kurakin et al. 2017] Kurakin, Alexey, Ian Goodfellow, and Samy Bengio. “Adversarial Machine Learning at Scale.” In International Conference on Learning Representations (ICLR), 2017
[Athalye et al. 2018] Athalye, Anish, Nicholas Carlini, and David Wagner. “Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples.” In International Conference on Machine Learning (ICML), 2018.
[Fleshman et al. 2019] Fleshman, William, Edward Raff, Jared Sylvester, Steven Forsyth, and Mark McLean. “Non-Negative Networks Against Adversarial Attacks.” AAAI-2019 Workshop on Artificial Intelligence for Cyber Security, 2019.
[Raff et al. 2019] Raff, Edward, Jared Sylvester, Steven Forsyth, Mark McLean. “Barrage of Random Transforms for Adversarially Robust Defense.” Computer Vision and Pattern Recognition (CVPR), 2019.