When you purchased your last car, did you check for safety ratings or quality assurances from the manufacturer. Perhaps, like most consumers, you simply went for a test drive to see if the car offered all the features and functionality you were looking for, from comfortable seating to electronic controls.
Audits and quality assurance are the norm across many industries. Consider car manufacturing, where the production of the car is followed by rigorous tests of safety, comfort, networking, and so on, before deployment to end users. Based on this, we ask the question, “How can we design a similarly motivated auditing scheme for deep learning models?”
AI has enjoyed widespread success in real-world applications. Current AI models—deep neural networks in particular—do not require exact specifications of the type of desired behavior. Instead, they require large datasets for training, or a designed reward function that must be optimized over time.
While this form of implicit supervision provides flexibility, it often leads to the algorithm optimizing for behavior that was not intended by the human designer. In many cases, it also leads to catastrophic consequences and failures in safety-critical applications, such as autonomous driving and healthcare.
As these models are prone to failure, especially under domain shifts, it is important to know before their deployment when they might fail. As deep learning research becomes increasingly integrated with real world applications, we must come up with schemes of formally auditing deep learning models.
Semantically aligned unit tests
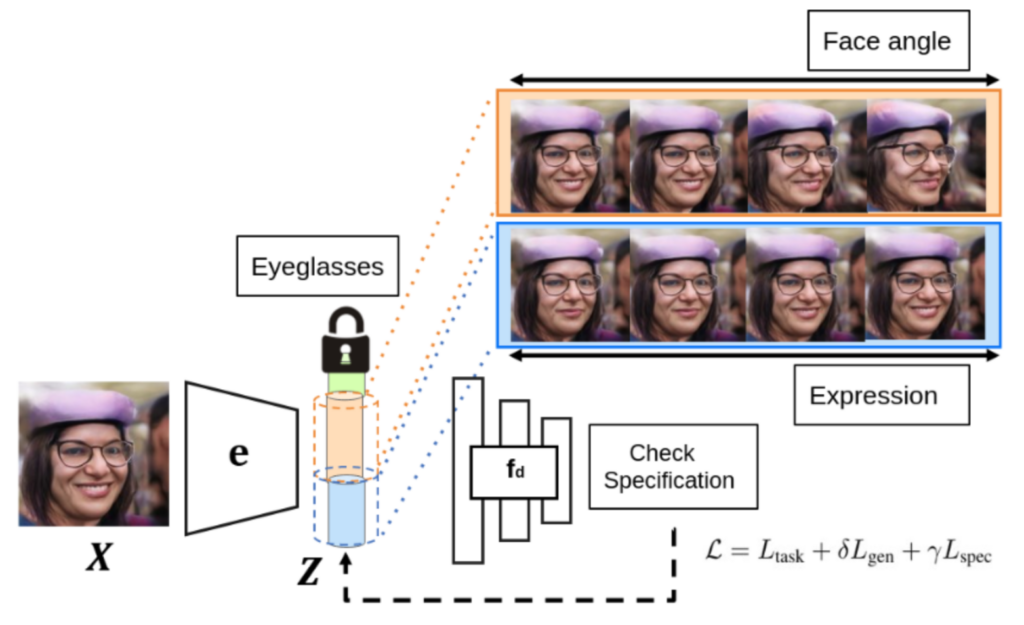
One of the biggest challenges in auditing is in understanding how we can obtain human-interpretable specifications that are directly useful to end users. We addressed this challenge through a sequence of semantically aligned unit tests. Each unit test verifies whether a predefined specification (for example, accuracy over 95%) is satisfied with respect to controlled and semantically aligned variations in the input space (for example, in face recognition, the angle relative to the camera).
We perform these unit tests by directly verifying the semantically aligned variations in an interpretable latent space of a generative model. Our framework, AuditAI, bridges the gap between interpretable formal verification of software systems and scalability of deep neural networks.
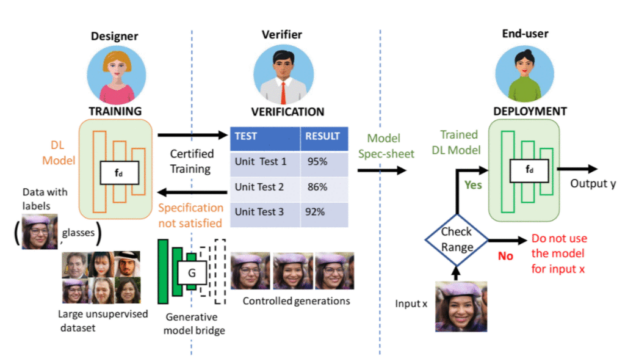
Consider a typical machine learning production pipeline with three parties: the end user of the deployed model, verifier, and model designer. The verifier plays the critical role of verifying whether the model from the designer satisfies the need of the end user. For example, unit test 1 could be verifying whether a given face classification model maintains over 95% accuracy when the face angle is within d degrees. Unit test 2 could be checking under what lighting condition the model has over 86% accuracy. After verification, the end user can then use the verified specification to determine whether to use the trained DL model during deployment.
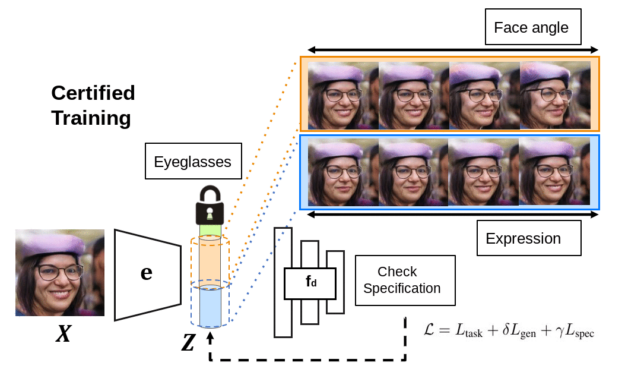
Verified deployment
To verify the deep network for semantically aligned properties, we bridge it with a generative model, such that they share the same latent space and the same encoder that projects inputs to latent codes. In addition to verifying whether a unit test is satisfied, we can also perform certified training to ensure that the unit test is likely to be satisfied in the first place. The framework has appealing theoretical properties, and we show in our paper how the verifier is guaranteed to be able to generate a proof of whether the verification is true or false. For more information, see Auditing AI models for Verified Deployment under Semantic Specifications.
Verification and certified training of neural networks for pixel-based perturbations covers a much narrower range of semantic variations in the latent space, compared to AuditAI. To perform a quantitative comparison, for the same verified error, we project the pixel-bound to the latent space and compare it with the latent-space bound for AuditAI. We show that AuditAI can tolerate around 20% larger latent variations compared to pixel-based counterparts as measured by L2 norm, for the same verified error. For the implementation and experiments, we used NVIDIA V100 GPUs and Python with the PyTorch library.
In Figure 3, we show qualitative results for generated outputs corresponding to controlled variations in the latent space. The top row shows visualizations for AuditAI, and the bottom row shows visualizations for pixel-perturbations for images of class hen on ImageNet, chest X-ray images with the condition pneumonia, and human faces with different degrees of smile respectively. From the visualizations, it is evident that wider latent variations correspond to a wider set of semantic variations in the generated outputs.
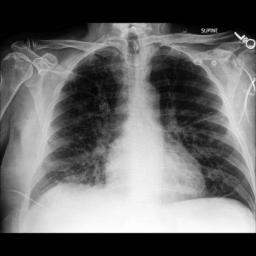


Figure 3. Top row: AuditAI visualizations, Bottom row: Visualizations for pixel-perturbations
Future work
In this paper, we developed a framework for auditing of deep learning (DL) models. There are increasingly growing concerns about innate biases in the DL models that are deployed in a wide range of settings and there have been multiple news articles about the necessity for auditing DL models before deployment. Our framework formalizes this audit problem, which we believe is a step towards increasing safety and the ethical use of DL models during deployment.
One of the limitations of AuditAI is that its interpretability is limited by that of the built-in generative model. While exciting progress has been made for generative models, we believe it is important to incorporate domain expertise to mitigate potential dataset biases and human error in both training and deployment.
Currently, AuditAI doesn’t directly integrate human domain experts in the auditing pipeline. It indirectly uses domain expertise in the curation of the dataset used for creating the generative model. Incorporating the former would be an important direction for future work.
Although we have demonstrated AuditAI primarily for auditing computer vision classification models, we hope that this would pave the way for more sophisticated domain-dependent AI-auditing tools and frameworks in language modeling and decision-making applications.
Acknowledgments
This work was conducted wholly at NVIDIA. We thank our co-authors De-An Huang, Chaowei Xiao, and Anima Anandkumar for helpful feedback, and everyone in the AI Algorithms team at NVIDIA for insightful discussions during the project.
