
Identity-based attacks are on the rise, with phishing remaining the most common and second-most expensive attack vector. Some attackers are using AI to craft more convincing phishing messages and deploying bots to get around automated defenses designed to spot suspicious behavior.
At the same time, a continued increase in enterprise applications introduces challenges for IT teams who must support, secure, and manage these applications, often with no increase in staffing.
The number of connected devices continues to grow, introducing security risks due to an increase in the attack surface. This is compounded by potential vulnerabilities associated with each device.
While there are many security tools and applications available to help enterprises defend against attacks, integrating and managing a large number of tools introduces more cost, complexity, and risk.
Cybersecurity is among the top three challenges for CEOs, second to environmental sustainability and just ahead of tech modernization. Generative AI can be transformational for cybersecurity. It can help security analysts find the information they need to do their jobs faster, generate synthetic data to train AI models to identify risks accurately, and run what-if scenarios to better prepare for potential threats.
Using AI to keep pace with an expanding threat landscape
Cybersecurity is a data problem, and the vast amount of data available is too large for manual screening and threat detection. This means human analysts can no longer effectively defend against the most sophisticated attacks because the speed and complexity of attacks and defenses exceed human capacity. With AI, organizations can achieve 100 percent visibility of their data and quickly discover anomalies, enabling them to detect threats faster.
Although the exponentially increasing quantity of data poses a challenge for threat detection, AI-based approaches to cyber defense require access to training data. In some cases, this isn’t readily available, because organizations don’t typically share sensitive data. With generative AI, synthetic data can help address the data gap and improve cybersecurity AI defense.
One of the most effective ways of synthesizing and contextualizing data is through natural language. The advancements of large language models (LLMs) are expanding threat detection and data generation techniques that improve cybersecurity.
This post explores three use cases showing how generative AI and LLMs improve cybersecurity and provides three examples of how AI foundation models for cybersecurity can be applied.
Copilots boost the efficiency and capabilities of security teams
Staffing shortages for cybersecurity professionals persist. Security copilots with retrieval-augmented generation (RAG) enable organizations to tap into existing knowledge bases and extend the capabilities of human analysts, making them more efficient and effective.
Copilots learn from the behaviors of security analysts, adapt to their needs, and provide relevant insights that guide them in their daily work, all in a natural interface. Organizations are quickly discovering the value of RAG chatbots.
By 2025, two-thirds of businesses will leverage a combination of generative AI and RAG to power domain-specific, self-service knowledge discovery, improving decision efficacy by 50%1.
In addition to not having enough cybersecurity personnel, organizations are challenged in training new and existing employees. With copilots, cybersecurity professionals can get near real-time responses and guidance on complex deployment scenarios without the need for additional training or research.
While security copilots can bring transformational benefits to an organization, they’re only useful when they can provide fast, accurate, and up-to-date information. The NVIDIA AI Chatbot with Retrieval-Augmented Generation workflow provides a great starting point. It demonstrates how to build agents and chatbots that can retrieve the most up-to-date information in real-time and provide accurate responses in natural language.
Generative AI can dramatically improve common vulnerability defense
Patching software security issues are becoming increasingly challenging as the number of reported security flaws in the common vulnerabilities and exposures (CVEs) database hit a record high in 2022. With over 200,000 cumulative vulnerabilities reported as of the third quarter of 2023, it’s clear that a traditional approach to scanning and patching has become unmanageable.
Organizations that deploy risk-based analysis experience less costly breaches compared to those that rely solely on CVE scoring to prioritize vulnerabilities. Using generative AI, it’s possible to improve vulnerability defense while decreasing the load on security teams.
Using the NVIDIA Morpheus LLM engine integration, NVIDIA built a pipeline to address CVE risk analysis with RAG. Security analysts can determine whether a software container includes vulnerable and exploitable components using LLMs and RAG.
This method enabled analysts to investigate individual CVEs 4X faster, on average, and identify vulnerabilities with high accuracy so patches could be prioritized and addressed accordingly.
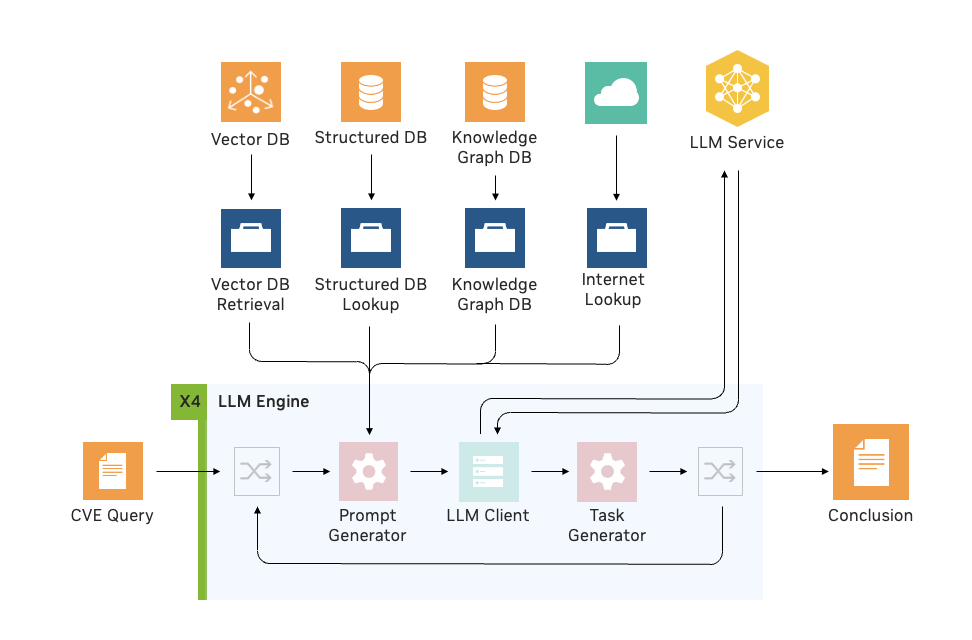
Foundation models for cybersecurity
While pretrained models are useful for many applications, there are times when it’s beneficial to train a custom model from scratch. This is helpful when there’s a specific domain with a unique vocabulary or the content has properties that do not conform to traditional language paradigms and structures.
In cybersecurity, this is observed with certain types of raw logs. Think about a book and how words form sentences, sentences form paragraphs, and paragraphs form chapters. There’s an inherent structure that is part of the language model. Contrast that to data contained in a format like JSON-lines or CEF. Proximity of the data keys and values doesn’t have the same meaning.
Using custom foundation models presents multiple opportunities.
- Addressing the data gap: while making better use of the influx of data can lead to improved cybersecurity, the quality of the data matters. When there is a lack of available training data, the accuracy of detecting threats is compromised. Generative AI can help address the data gap with synthetic data generation, or by using large models to generate data to train smaller models.
- Performing “what if” scenarios: novel threats are challenging to defend against without data sets to build the defenses. Generative AI can be used for attack simulations and to perform “what if” scenarios—to test against attack patterns that haven’t yet been experienced. This dynamic model training, based on evolving threats and changing patterns in data can help to improve overall security.
- Feed downstream anomaly detectors: use large models to generate data that train downstream, lightweight models used for threat detection, which can reduce infrastructure costs while keeping the same level of accuracy.
NVIDIA performed many experiments and trained several cybersecurity-specific foundation models, including one based on GPT-2 style models referenced as CyberGPT. One of those is a model that is trained on identity data (including application logs like Azure AD). With this model, one can generate highly realistic synthetic data that addresses a data gap and can perform “what if” scenarios.
Figure 2 shows the Rogue2 F1 scores for CyberGPT models of various sizes, with each instance achieving around 80% accuracy. This means that 8 out of 10 logs generated are virtually indistinguishable from logs generated by real network users.
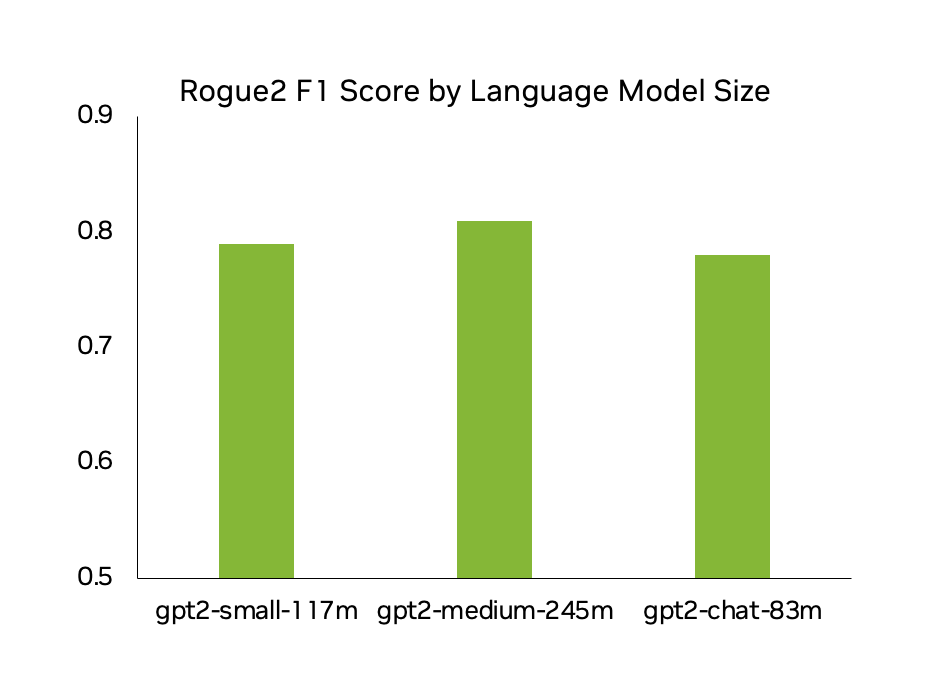
As for training times, a supercomputer isn’t necessary to realize quality results. In testing, training times were as low as 12 GPU hours for a GPT-2-small model with character-level tokenization. This model is trained on 2.3M rows of over 100 user logs with 1,000 iterations. This model was trained on multiple types of data, including Azure, SharePoint, Confluence, and Jira.
Experiments were also run with tokenizers–primarily character-level tokenizers, off-the-shelf byte pair encoding (BPE) tokenizers, and custom-trained tokenizers. While there are benefits and drawbacks to each, the best performance comes as a result of training custom tokenizers. This not only enables more efficient use of resources due to the custom vocabulary, but it results in reduced tokenization errors and can handle log-specific syntax.
While these results reflect experiments with language models, the same tests with LLMs achieve similar results.
Synthetic data generation provides 100% detection of spear phishing e-mails
Spear phishing e-mails are highly targeted, and therefore, very convincing. The only real difference between a spear phishing (and, in general, any effective phishing campaign) and a benign e-mail is the intent of the sender. This makes spear phishing challenging to defend against with AI because there is a lack of available training data.
To explore the potential of synthetic data generation in enhancing spear phishing e-mail detection, a pipeline was constructed using NVIDIA Morpheus.
With off-the-shelf models, the spear phishing detection pipeline missed 16% (about 600) of malicious e-mails. The uncaught malicious e-mails were then used to create a new synthetic dataset. A new intent model was learned from the synthetically generated e-mails, and integrated into our spear phishing detection pipeline. The addition of this new intent model feature in the detection pipeline resulted in 100% detection of spear phishing e-mails trained solely on synthetic e-mails.
The NVIDIA spear phishing detection AI workflow provides an example of how to build this solution using NVIDIA Morpheus.
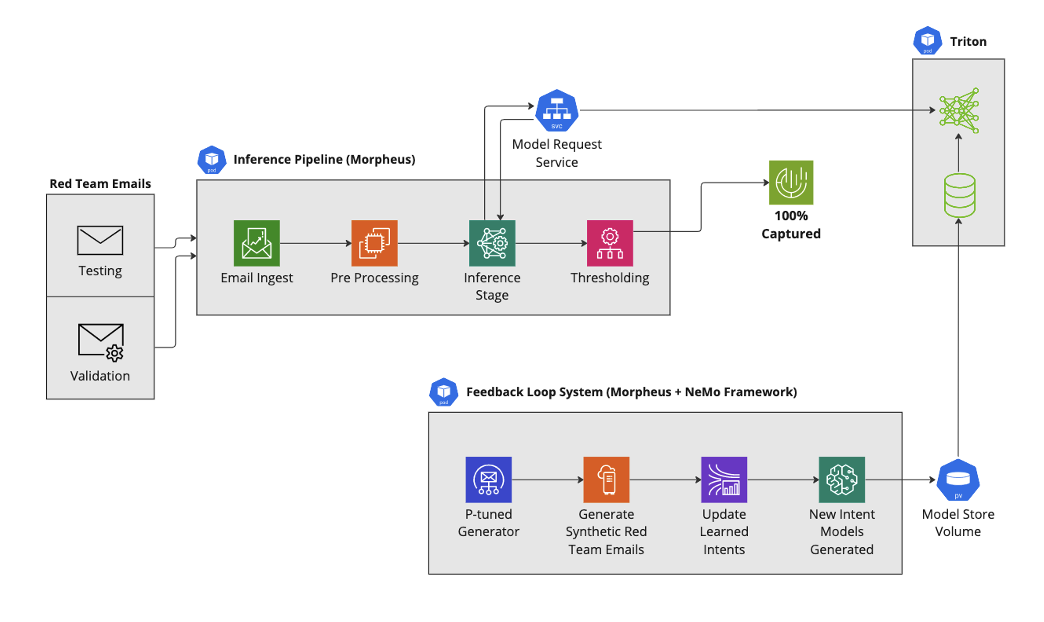
A comprehensive approach to enterprise security
The NVIDIA AI platform is uniquely positioned to help address these challenges–building in security at multiple levels. At the hardware infrastructure level, and beyond the data center perimeter to the edge of every server, while also providing tools that help to secure your data with AI.
Learn more
Watch the session from Bartley Richardson, head of cybersecurity engineering at NVIDIA, to see demonstrations of the use cases illustrated in this post. Learn about integrating language models and cybersecurity featured at NVIDIA LLM Developer Day.
Check out the November 2023 release of NVIDIA Morpheus to access the new LLM engine integration feature, and get started with accelerated AI for cybersecurity.
Find out how NVIDIA NeMo provides an easy way to get started with building, customizing, and deploying generative AI models.
NVIDIA Morpheus and NeMo are included with NVIDIA AI Enterprise, the enterprise-grade software that powers the NVIDIA AI platform.
- IDC FutureScape: Worldwide Artificial Intelligence and Automation 2024 Predictions, #AP50341323, October 2023 ↩︎
