This post was updated July 20, 2021 to reflect NVIDIA TensorRT 8.0 updates.
NVIDIA TensorRT is an SDK for deep learning inference. TensorRT provides APIs and parsers to import trained models from all major deep learning frameworks. It then generates optimized runtime engines deployable in the datacenter as well as in automotive and embedded environments.
This post provides a simple introduction to using TensorRT. You learn how to deploy a deep learning application onto a GPU, increasing throughput and reducing latency during inference. It uses a C++ example to walk you through converting a PyTorch model into an ONNX model and importing it into TensorRT, applying optimizations, and generating a high-performance runtime engine for the datacenter environment.
TensorRT supports both C++ and Python; if you use either, this workflow discussion could be useful. If you prefer to use Python, see Using the Python API in the TensorRT documentation.
Deep learning applies to a wide range of applications such as natural language processing, recommender systems, image, and video analysis. As more applications use deep learning in production, demands on accuracy and performance have led to strong growth in model complexity and size.
Safety-critical applications such as automotive place strict requirements on throughput and latency expected from deep learning models. The same holds true for some consumer applications, including recommendation systems.
TensorRT is designed to help deploy deep learning for these use cases. With support for every major framework, TensorRT helps process large amounts of data with low latency through powerful optimizations, use of reduced precision, and efficient memory use.
The sample application uses input data from Brain MRI segmentation data from Kaggle to perform inference.
Requirements
To follow along with this post, you need a computer with a CUDA-capable GPU or a cloud instance with GPUs and an installation of TensorRT. On Linux, the easiest place to get started is by downloading the GPU-accelerated PyTorch container with TensorRT integration from the NVIDIA Container Registry (on NGC). The link will have an updated version of the container, but to make sure that this tutorial works properly, we specify the version used for this post:
# Pull PyTorch container docker pull nvcr.io/nvidia/pytorch:20.07-py3
This container has the following specifications:
- Ubuntu 18.04
- Python 3.6.10
- CUDA 11.0
- Torch 1.6.0a
- TensorRT 7.1.3
Because you use TensorRT 8 in this walkthrough, you must upgrade it in the container. The next step is to download the .deb package for TensorRT 8 (CUDA 11.0, Ubuntu 18.04), and install the following requirements:
# Export absolute path to directory hosting TRT8.deb export TRT_DEB_DIR_PATH=$HOME/trt_release # Change this path to where you’re keeping your .deb file # Run container docker run --rm --gpus all -ti --volume $TRT_DEB_DIR_PATH:/workspace/trt_release --net host nvcr.io/nvidia/pytorch:20.07-py3 # Update TensorRT version to 8 dpkg -i nv-tensorrt-repo-ubuntu1804-cuda11.0-trt8.0.0.3-ea-20210423_1-1_amd64.deb apt-key add /var/nv-tensorrt-repo-ubuntu1804-cuda11.0-trt8.0.0.3-ea-20210423/7fa2af80.pub apt-get update apt-get install -y libnvinfer8 libnvinfer-plugin8 libnvparsers8 libnvonnxparsers8 apt-get install -y libnvinfer-bin libnvinfer-dev libnvinfer-plugin-dev libnvparsers-dev apt-get install -y tensorrt # Verify TRT 8.0.0 installation dpkg -l | grep TensorRT
Simple TensorRT example
Following are the four steps for this example application:
- Convert the pretrained image segmentation PyTorch model into ONNX.
- Import the ONNX model into TensorRT.
- Apply optimizations and generate an engine.
- Perform inference on the GPU.
Importing the ONNX model includes loading it from a saved file on disk and converting it to a TensorRT network from its native framework or format. ONNX is a standard for representing deep learning models enabling them to be transferred between frameworks.
Many frameworks such as Caffe2, Chainer, CNTK, PaddlePaddle, PyTorch, and MXNet support the ONNX format. Next, an optimized TensorRT engine is built based on the input model, target GPU platform, and other configuration parameters specified. The last step is to provide input data to the TensorRT engine to perform inference.
The application uses the following components in TensorRT:
- ONNX parser: Takes a converted PyTorch trained model into the ONNX format as input and populates a network object in TensorRT.
- Builder: Takes a network in TensorRT and generates an engine that is optimized for the target platform.
- Engine: Takes input data, performs inferences, and emits inference output.
- Logger: Associated with the builder and engine to capture errors, warnings, and other information during the build and inference phases.
Convert the pretrained image segmentation PyTorch model into ONNX
After you have successfully installed the PyTorch container from the NGC registry and upgraded it with TensorRT 8.0, run the following commands to download everything needed to run this sample application (example code, test input data, and reference outputs). Then, update the dependencies and compile the application with the makefile provided.
>> sudo apt-get install libprotobuf-dev protobuf-compiler # protobuf is a prerequisite library >> git clone --recursive https://github.com/onnx/onnx.git # Pull the ONNX repository from GitHub >> cd onnx >> mkdir build && cd build >> cmake .. # Compile and install ONNX >> make # Use the ‘-j’ option for parallel jobs, for example, ‘make -j $(nproc)’ >> make install >> cd ../.. >> git clone https://github.com/parallel-forall/code-samples.git >> cd code-samples/posts/TensorRT-introduction Modify $TRT_INSTALL_DIR in the Makefile. >> make clean && make # Compile the TensorRT C++ code >> cd .. >> wget https://developer.download.nvidia.com/devblogs/speeding-up-unet.7z // Get the ONNX model and test the data >> sudo apt install p7zip-full >> 7z x speeding-up-unet.7z # Unpack the model data into the unet folder >> cd unet >> python create_network.py #Inside the unet folder, it creates the unet.onnx file
Convert the PyTorch-trained UNet model into ONNX, as shown in the following code example:
import torch
from torch.autograd import Variable
import torch.onnx as torch_onnx
import onnx
def main():
input_shape = (3, 256, 256)
model_onnx_path = "unet.onnx"
dummy_input = Variable(torch.randn(1, *input_shape))
model = torch.hub.load('mateuszbuda/brain-segmentation-pytorch', 'unet',
in_channels=3, out_channels=1, init_features=32, pretrained=True)
model.train(False)
inputs = ['input.1']
outputs = ['186']
dynamic_axes = {'input.1': {0: 'batch'}, '186':{0:'batch'}}
out = torch.onnx.export(model, dummy_input, model_onnx_path, input_names=inputs, output_names=outputs, dynamic_axes=dynamic_axes)
if __name__=='__main__':
main()
Next, prepare the input data for inference. Download all images from the Kaggle directory. Copy to the /unet directory any three images that don’t have _mask in their filename and the utils.py file from the brain-segmentation-pytorch repository. Prepare three images to be used as input data later in this post. To prepare the input_0. pb and ouput_0. pb files for use later, run the following code example:
import torch
import argparse
import numpy as np
from torchvision import transforms
from skimage.io import imread
from onnx import numpy_helper
from utils import normalize_volume
def main(args):
model = torch.hub.load('mateuszbuda/brain-segmentation-pytorch', 'unet',
in_channels=3, out_channels=1, init_features=32, pretrained=True)
model.train(False)
filename = args.input_image
input_image = imread(filename)
input_image = normalize_volume(input_image)
input_image = np.asarray(input_image, dtype='float32')
preprocess = transforms.Compose([
transforms.ToTensor(),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0)
tensor1 = numpy_helper.from_array(input_batch.numpy())
with open(args.input_tensor, 'wb') as f:
f.write(tensor1.SerializeToString())
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model = model.to('cuda')
with torch.no_grad():
output = model(input_batch)
tensor = numpy_helper.from_array(output[0].cpu().numpy())
with open(args.output_tensor, 'wb') as f:
f.write(tensor.SerializeToString())
if __name__=='__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--input_image', type=str)
parser.add_argument('--input_tensor', type=str, default='input_0.pb')
parser.add_argument('--output_tensor', type=str, default='output_0.pb')
args=parser.parse_args()
main(args)
To generate processed input data for inference, run the following commands:
>> pip install medpy #dependency for utils.py file >> mkdir test_data_set_0 >> mkdir test_data_set_1 >> mkdir test_data_set_2 >> python prepareData.py --input_image your_image1 --input_tensor test_data_set_0/input_0.pb --output_tensor test_data_set_0/output_0.pb # This creates input_0.pb and output_0.pb >> python prepareData.py --input_image your_image2 --input_tensor test_data_set_1/input_0.pb --output_tensor test_data_set_1/output_0.pb # This creates input_0.pb and output_0.pb >> python prepareData.py --input_image your_image3 --input_tensor test_data_set_2/input_0.pb --output_tensor test_data_set_2/output_0.pb # This creates input_0.pb and output_0.pb
That’s it, you have the input data ready to perform inference.
Import the ONNX model into TensorRT, generate the engine, and perform inference
Run the sample application with the trained model and input data passed as inputs. The data is provided as an ONNX protobuf file. The sample application compares output generated from TensorRT with reference values available as ONNX .pb files in the same folder and summarizes the result on the prompt.
It can take a few seconds to import the UNet ONNX model and generate the engine. It also generates the output image in the portable gray map (PGM) format as output.pgm.
>> cd to code-samples/posts/TensorRT-introduction-updated >> ./simpleOnnx path/to/unet/unet.onnx fp32 path/to/unet/test_data_set_0/input_0.pb # The sample application expects output reference values in path/to/unet/test_data_set_0/output_0.pb ... ... : --------------- Timing Runner: Conv_40 + Relu_41 (CaskConvolution) : Conv_40 + Relu_41 Set Tactic Name: volta_scudnn_128x128_relu_exp_medium_nhwc_tn_v1 Tactic: 861694390046228376 : Tactic: 861694390046228376 Time: 0.237568 ... : Conv_40 + Relu_41 Set Tactic Name: volta_scudnn_128x128_relu_exp_large_nhwc_tn_v1 Tactic: -3853827649136781465 : Tactic: -3853827649136781465 Time: 0.237568 : Conv_40 + Relu_41 Set Tactic Name: volta_scudnn_128x64_sliced1x2_ldg4_relu_exp_large_nhwc_tn_v1 Tactic: -3263369460438823196 : Tactic: -3263369460438823196 Time: 0.126976 : Conv_40 + Relu_41 Set Tactic Name: volta_scudnn_128x32_sliced1x4_ldg4_relu_exp_medium_nhwc_tn_v1 Tactic: -423878181466897819 : Tactic: -423878181466897819 Time: 0.131072 : Fastest Tactic: -3263369460438823196 Time: 0.126976 : >>>>>>>>>>>>>>> Chose Runner Type: CaskConvolution Tactic: -3263369460438823196 ... ... INFO: [MemUsageChange] Init cuDNN: CPU +1, GPU +8, now: CPU 1148, GPU 1959 (MiB) : Total per-runner device memory is 79243264 : Total per-runner host memory is 13840 : Allocated activation device memory of size 1459617792 Inference batch size 1 average over 10 runs is 2.21147ms Verification: OK INFO: [MemUsageChange] Init cuBLAS/cuBLASLt: CPU +0, GPU +0, now: CPU 1149, GPU 3333 (MiB)
And that’s it, you have an application that is optimized with TensorRT and running on your GPU. Figure 2 shows the output of a sample test case.
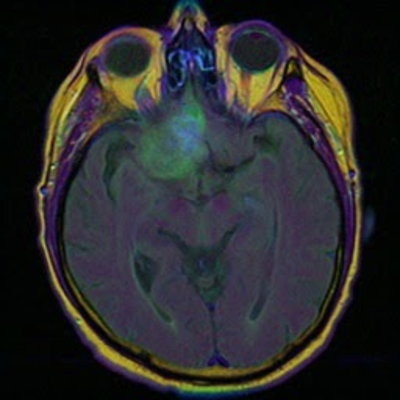

(2a): Original MRI input image 
(2b): Segmented ground truth from test dataset 

(2c): Predicted segmented image using TensorRT
Here are a few key code examples used in the earlier sample application.
The main function in the following code example starts by declaring a CUDA engine to hold the network definition and trained parameters. The engine is generated in the SimpleOnnx::createEngine function that takes the path to the ONNX model as input.
// Declare the CUDA engine
SampleUniquePtr<nvinfer1::ICudaEngine> mEngine{nullptr};
...
// Create the CUDA engine
mEngine = SampleUniquePtr<nvinfer1::ICudaEngine> (builder->buildEngineWithConfig(*network, *config));
The SimpleOnnx::buildEngine function parses the ONNX model and holds it in the network object. To handle the dynamic input dimensions of input images and shape tensors for U-Net model, you must create an optimization profile from the builder class, as shown in the following code example.
The optimization profile enables you to set the optimum input, minimum, and maximum dimensions to the profile. The builder selects the kernel that results in the lowest runtime for input tensor dimensions and which is valid for all input tensor dimensions in the range between the minimum and maximum dimensions. It also converts the network object into a TensorRT engine.
The setMaxBatchSize function in the following code example is used to specify the maximum batch size that a TensorRT engine expects. The setMaxWorkspaceSize function allows you to increase the GPU memory footprint during the engine building phase.
bool SimpleOnnx::createEngine(const SampleUniquePtr<nvinfer1::IBuilder>& builder)
{
// Create a network using the parser.
const auto explicitBatch = 1U << static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(explicitBatch));
...
auto parser= SampleUniquePtr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, gLogger));
auto parsed = parser->parseFromFile(mParams.onnxFilePath.c_str(), static_cast<int>(nvinfer1::ILogger::Severity::kINFO));
auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
auto profile = builder->createOptimizationProfile();
profile->setDimensions("input.1", OptProfileSelector::kMIN, Dims4{1, 3, 256, 256});
profile->setDimensions("input.1", OptProfileSelector::kOPT, Dims4{1, 3, 256, 256});
profile->setDimensions("input.1", OptProfileSelector::kMAX, Dims4{32, 3, 256, 256});
config->addOptimizationProfile(profile);
...
// Setup model precision.
if (mParams.fp16)
{
config->setFlag(BuilderFlag::kFP16);
}
// Build the engine.
mEngine = SampleUniquePtr<nvinfer1::ICudaEngine>(builder->buildEngineWithConfig(*network, *config));
...
return true;
}
After an engine has been created, create an execution context to hold intermediate activation values generated during inference. The following code shows how to create the execution context.
// Declare the execution context
SampleUniquePtr<nvinfer1::IExecutionContext> mContext{nullptr};
...
// Create the execution context
mContext = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
This application places inference requests on the GPU asynchronously in the function launchInference shown in the following code example. Inputs are copied from host (CPU) to device (GPU) within launchInference. The inference is then performed with the enqueueV2 function, and results copied back asynchronously.
The example uses CUDA streams to manage asynchronous work on the GPU. Asynchronous inference execution generally increases performance by overlapping compute as it maximizes GPU utilization. The enqueueV2 function places inference requests on CUDA streams and takes as input runtime batch size, pointers to input and output, plus the CUDA stream to be used for kernel execution. Asynchronous data transfers are performed from the host to the device and the reverse using cudaMemcpyAsync.
void SimpleOnnx::launchInference(IExecutionContext* context, cudaStream_t stream, vector<float> const& inputTensor, vector<float>& outputTensor, void** bindings, int batchSize)
{
int inputId = getBindingInputIndex(context);
cudaMemcpyAsync(bindings[inputId], inputTensor.data(), inputTensor.size() * sizeof(float), cudaMemcpyHostToDevice, stream);
context->enqueueV2(bindings, stream, nullptr);
cudaMemcpyAsync(outputTensor.data(), bindings[1 - inputId], outputTensor.size() * sizeof(float), cudaMemcpyDeviceToHost, stream);
}
Using the cudaStreamSynchronize function after calling launchInference ensures GPU computations complete before the results are accessed. The number of inputs and outputs, as well as the value and dimension of each, can be queried using functions from the ICudaEngine class. The sample finally compares reference output with TensorRT-generated inferences and prints discrepancies to the prompt.
For more information about classes, see the TensorRT Class List. The complete code example is in simpleOnnx_1.cpp.
Batch your inputs
This application example expects a single input and returns output after performing inference on it. Real applications commonly batch inputs to achieve higher performance and efficiency. A batch of inputs that are identical in shape and size can be computed in parallel on different layers of the neural network.
Larger batches generally enable more efficient use of GPU resources. For example, batch sizes using multiples of 32 may be particularly fast and efficient in lower precision on Volta and Turing GPUs because TensorRT can use special kernels for matrix multiply and fully connected layers that leverage Tensor Cores.
Pass the images to the application on the command line using the following code. The number of images (.pb files) passed as input arguments on the command line determines the batch size in this example. Use test_data_set_* to take all the input_0.pb files from all the directories. Instead of reading just one input, the following command reads all inputs available in the folders.
Currently, the downloaded data has three input directories, so the batch size is 3. This version of the example profiles the application and prints the result to the prompt. For more information, see the next section, Profile the application.
>> ./simpleOnnx path/to/unet/unet.onnx fp32 path/to/unet/test_data_set_*/input_0.pb # Use all available test data sets. ... INFO: [MemUsageChange] Init cuDNN: CPU +1, GPU +8, now: CPU 1148, GPU 1806 (MiB) : Total per-runner device memory is 79243264 : Total per-runner host memory is 13840 : Allocated activation device memory of size 1459617792 Inference batch size 3 average over 10 runs is 4.99552ms
To process multiple images in one inference pass, make a couple of changes to the application. First, collect all images (.pb files) in a loop to use as input in the application:
for (int i = 2; i < argc; ++i)
input_files.push_back(string{argv[i]});
Next, specify the maximum batch size that a TensorRT engine expects using the setMaxBatchSize function. The builder then generates an engine tuned for that batch size by choosing algorithms that maximize its performance on the target platform. While the engine does not accept larger batch sizes, using smaller batch sizes at runtime is allowed.
The choice of maxBatchSize value depends on the application as well as the expected inference traffic (for example, the number of images) at any given time. A common practice is to build multiple engines optimized for different batch sizes (using different maxBatchSize values), and then choosing the most optimized engine at runtime.
When not specified, the default batch size is 1, meaning that the engine does not process batch sizes greater than 1. Set this parameter as shown in the following code example:
builder->setMaxBatchSize(batchSize);
Profile the application
Now that you’ve seen an example, here’s how to measure its performance. The simplest performance measurement for network inference is the time elapsed between an input being presented to the network and an output being returned, referred to as latency.
For many applications on embedded platforms, latency is critical while consumer applications require quality-of-service. Lower latencies make these applications better. This example measures the average latency of an application using timestamps on the GPU. There are many ways to profile your application in CUDA. For more information, see How to Implement Performance Metrics in CUDA C/C++ .
CUDA offers lightweight event API functions to create, destroy, and record events, as well as calculate the time between them. The application can record events in the CUDA stream, one before initiating inference and another after the inference completes, shown in the following code example.
In some cases, you might care about including the time it takes to transfer data between the GPU and CPU before inference initiates and after inference completes. Techniques exist to pre-fetch data to the GPU as well as overlap compute with data transfers that can significantly hide data transfer overhead. The function cudaEventElapsedTime measures the time between these two events being encountered in the CUDA stream.
Use the following code example for latency calculation within SimpleOnnx::infer:
// Number of times to run inference and calculate average time
constexpr int ITERATIONS = 10;
...
bool SimpleOnnx::infer()
{
CudaEvent start;
CudaEvent end;
double totalTime = 0.0;
CudaStream stream;
for (int i = 0; i < ITERATIONS; ++i)
{
float elapsedTime;
// Measure time it takes to copy input to GPU, run inference and move output back to CPU.
cudaEventRecord(start, stream);
launchInference(mContext.get(), stream, mInputTensor, mOutputTensor, mBindings, mParams.batchSize);
cudaEventRecord(end, stream);
// Wait until the work is finished.
cudaStreamSynchronize(stream);
cudaEventElapsedTime(&elapsedTime, start, end);
totalTime += elapsedTime;
}
cout << "Inference batch size " << mParams.batchSize << " average over " << ITERATIONS << " runs is " << totalTime / ITERATIONS << "ms" << endl;
return true;
}
Many applications perform inferences on large amounts of input data accumulated and batched for offline processing. The maximum number of inferences possible per second, known as throughput, is a valuable metric for these applications.
You measure throughput by generating optimized engines for larger specific batch sizes, run inference, and measure the number of batches that can be processed per second. Use the number of batches per second and batch size to calculate the number of inferences per second, but this is out of scope for this post.
Optimize your application
Now that you know how to run inference in batches and profile your application, optimize it. The key strength of TensorRT is its flexibility and use of techniques including mixed precision, efficient optimizations on all GPU platforms, and the ability to optimize across a wide range of model types.
In this section, we describe a few techniques to increase throughput and reduce latency from applications. For more information, see Best Practices for TensorRT Performance.
Here are a few common techniques:
- Use mixed precision computation
- Change the workspace size
- Reuse the TensorRT engine
Use mixed precision computation
TensorRT uses FP32 algorithms for performing inference to obtain the highest possible inference accuracy by default. However, you can use FP16 and INT8 precision for inference with minimal impact on the accuracy of results in many cases.
Using reduced precision to represent models enables you to fit larger models in memory and achieve higher performance given lower data transfer requirements for reduced precision. You can also mix computations in FP32 and FP16 precision with TensorRT, referred to as mixed precision, or use INT8 quantized precision for weights, activations, and execute layers.
Enable FP16 kernels by setting the setFlag(BuilderFlag::kFP16) parameter to true for devices that support fast FP16 math.
if (mParams.fp16)
{
config->setFlag(BuilderFlag::kFP16);
}
The setFlag(BuilderFlag::kFP16) parameter indicates to the builder that a lower precision is acceptable for computations. TensorRT uses FP16 optimized kernels if they perform better with the chosen configuration and target platform.
With this mode turned on, weights can be specified in FP16 or FP32, and are converted automatically to the appropriate precision for the computation. You also have the flexibility of specifying 16-bit floating point data type for input and output tensors, which is out of scope for this post.
Change the workspace size
TensorRT allows you to increase GPU memory footprint during the engine building phase with the setMaxWorkspaceSize parameter. Increasing the limit may affect the number of applications that could share the GPU at the same time. Setting this limit too low may filter out several algorithms and create a suboptimal engine. TensorRT allocates just the memory required even if the amount set in IBuilder::setMaxWorkspaceSize is much higher. Applications should therefore allow the TensorRT builder as much workspace as they can afford. TensorRT allocates no more than this and typically less.
This example uses 1 GB, which lets TensorRT pick any algorithm available.
// Allow TensorRT to use up to 1 GB of GPU memory for tactic selection constexpr size_t MAX_WORKSPACE_SIZE = 1ULL << 30; // 1 GB worked well for this example ... // Set the builder flag config->setMaxWorkspaceSize(MAX_WORKSPACE_SIZE);
Reuse the TensorRT engine
When building the engine, the builder object selects the most optimized kernels for the chosen platform and configuration. Building the engine from a network definition file can be time-consuming and should not be repeated each time you perform inference, unless the model, platform, or configuration changes.
Figure 3 shows that you can transform the format of the engine after generation and store on disk for reuse later, known as serializing the engine. Deserializing occurs when you load the engine from disk into memory and continue to use it for inference.
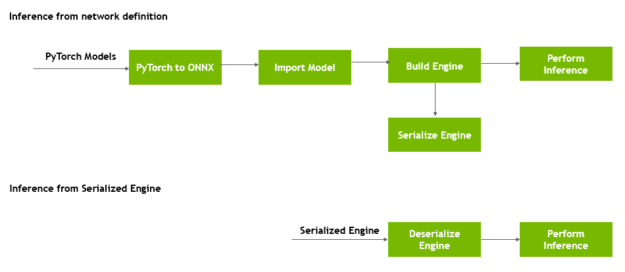
The runtime object deserializes the engine.
The SimpleOnnx::buildEngine function first tries to load and use an engine if it exists. If the engine is not available, it creates and saves the engine in the current directory with the name unet_batch4.engine. Before this example tries to build a new engine, it picks this engine if it is available in the current directory.
To force a new engine to be built with updated configuration and parameters, use the make clean_engines command to delete all existing serialized engines stored on disk before re-running the code example.
bool SimpleOnnx::buildEngine()
{
auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger));
string precison = (mParams.fp16 == false) ? "fp32" : "fp16";
string enginePath{getBasename(mParams.onnxFilePath) + "_batch" + to_string(mParams.batchSize)
+ "_" + precison + ".engine"};
string buffer = readBuffer(enginePath);
if (buffer.size())
{
// Try to deserialize engine.
SampleUniquePtr<nvinfer1::IRuntime> runtime{nvinfer1::createInferRuntime(gLogger)};
mEngine = SampleUniquePtr<nvinfer1::ICudaEngine>(runtime->deserializeCudaEngine(buffer.data(), buffer.size(), nullptr));
}
if (!mEngine)
{
// Fallback to creating engine from scratch.
createEngine(builder);
if (mEngine)
{
SampleUniquePtr<IHostMemory> engine_plan{mEngine->serialize()};
// Try to save engine for future uses.
writeBuffer(engine_plan->data(), engine_plan->size(), enginePath);
}
}
return true;
}
You’ve now learned how to speed up inference of a simple application using TensorRT. We measured the earlier performance on NVIDIA TITAN V GPUs with TensorRT 8 throughout this post.
Next steps
Real-world applications have much higher computing demands with larger deep learning models, more data processing needs, and tighter latency bounds. TensorRT offers high-performance optimizations for compute- heavy deep learning applications and is an invaluable tool for inference.
Hopefully, this post has familiarized you with the key concepts needed to get amazing performance with TensorRT. Here are some ideas to apply what you have learned, use other models, and explore the impact of design and performance tradeoffs by changing parameters introduced in this post.
- The TensorRT support matrix provides a look into supported features and software for TensorRT APIs, parsers, and layers. While this example used C++, TensorRT provides both C++ and Python APIs. To run the sample application included in this post, see the APIs and Python and C++ code examples in the TensorRT Developer Guide.
- Change the allowable precision with the parameter setFp16Mode to true/false for the models and profile the applications to see the difference in performance.
- Change the batch size used at run time for inference and see how that impacts the performance (latency, throughput) of your model and dataset.
- Change the maxbatchsize parameter from 64 to 4 and see different kernels get selected among the top five. Use nvprof to see the kernels in the profiling results.
One topic not covered in this post is performing inference accurately in TensorRT with INT8 precision. TensorRT can convert an FP32 network for deployment with INT8 reduced precision while minimizing accuracy loss. To achieve this goal, models can be quantized using post training quantization and quantization aware training with TensorRT. For more information, see Achieving FP32 Accuracy for INT8 Inference using Quantization Aware Training with TensorRT.
There are numerous resources to help you accelerate applications for image/video, speech apps, and recommendation systems. These range from code samples, self-paced Deep Learning Institute labs and tutorials to developer tools for profiling and debugging applications.
- Accelerating Deep Learning Inference with TensorRT 8.0 (webinar)
- TensorRT Quick Start guide
- Accelerating Inference with Sparsity using the NVIDIA Ampere Architecture and NVIDIA TensorRT
- Real-Time Natural Language Processing with BERT Using NVIDIA TensorRT
If you have issues with TensorRT, check the NVIDIA TensorRT Developer Forum to see if other members of the TensorRT community have a resolution first. NVIDIA Registered Developers can also file bugs on the Developer Program page.
