Researchers from Facebook developed a deep learning system that can replicate the music it hears and play it back as if it were Mozart, Beethoven, or Bach. This is the first time researchers have produced high fidelity musical translation between instruments, styles, and genres.
“Humans have always created music and replicated it – whether it is by singing, whistling, clapping, or, after some training, playing improvised or standard musical instruments. This ability is not unique to us, and there are many other vocal mimicking species that are able to repeat a music from hearing,” the researchers wrote in their research paper.
Using eight NVIDIA Tesla V100 GPUs and the cuDNN-accelerated PyTorch deep learning framework, the team trained their system on six types of classical music domains including: Mozart’s 46 symphonies, Haydn’s 27 string quartets, J.S Bach’s cantatas for orchestra, J.S Bach’s organ works, Beethoven’s 32 piano sonatas, and J.S Bach’s keyboard works. The training took eight days and included thousands of samples from the domains.
The method is based on a multi-domain WaveNet autoencoder, which NVIDIA wrote about last month. The researchers mention that the domain-independent encoder allows them to translate even from musical domains that were not seen during training.
“We slightly modify the WaveNet equations so that their architecture would fit the inference-time CUDA kernels provided by NVIDIA,” the researchers stated.
The same GPUs used during training are also used for inference.
“Our results present abilities that are, as far as we know, unheard of. Asked to convert one musical instrument to another, our network is on par or slightly worse than professional musicians. Many times, people find it hard to tell which is the original audio file and which is the output of the conversion that mimics a completely different instrument,” the researchers said.
The team says their work could open the way for other high-level tasks such as transcription of music and automatic composition of music.
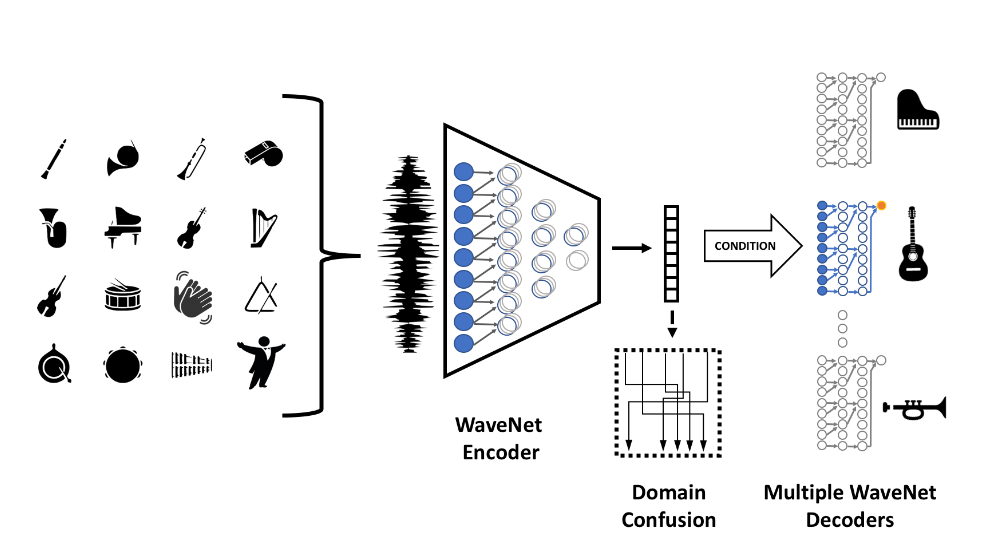
“Our network is able to successfully process unseen musical instruments or other sources such as whistles. On the output side, relatively high-quality audio is produced and new instruments can be added without retraining the entire network.”
The paper was published on ArXiv today.
Read more >
AI-Generated Summary
- Researchers from Facebook developed a deep learning system that can replicate music it hears and play it back in the style of famous composers like Wolfgang Amadeus Mozart, Ludwig van Beethoven, or Johann Sebastian Bach.
- The system was trained on six types of classical music domains using eight NVIDIA Tesla V100 GPUs and the cuDNN-accelerated PyTorch deep learning framework, taking eight days to train on thousands of samples.
- The team claims their work could lead to other high-level tasks such as transcription of music and automatic composition of music, and their network can successfully process unseen musical instruments and produce relatively high-quality audio.
AI-generated content may summarize information incompletely. Verify important information. Learn more