To parallelize sequential User-Defined Functions (UDFs) on GPUs, the function must be applied independently across keys and have a high cardinality grouping key.
The sessionization UDF is transformed using Numba into two parts: creating session boundaries and assigning unique session flags, both of which can be executed in parallel on GPUs.
Using Dask-cuDF Dataframe and invoking the transformed UDF on each partition results in a significant speedup, achieving a 100x improvement over pure Python, from 17.7s to 14.3 ms.
The speedup is achieved by leveraging the power of NVIDIA GPUs and utilizing libraries like RAPIDS, Numba, and Dask to maximize performance.
AI-generated content may summarize information incompletely. Verify important information. Learn more
Motivation
Custom “row-by-row” processing logic (sometimes called sequential User-Defined Functions) is prevalent in ETL workflows. The sequential nature of UDFs makes parallelization on GPUs tricky. This blog post covers how to implement the same UDF logic using RAPIDS to parallelize computation on GPUs and unlock 100x speedups.
Introduction
Typically, sequential UDFs revolve around records with the same grouping key. For example, analyzing a user’s clicks per session on a website where a session ends after 30 minutes of inactivity. In Apache Spark, you’d first cluster on user key, and then segregate user sessions using a UDF like in the example below. This UDF uses multiple CPU threads to run sequential functions in parallel.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
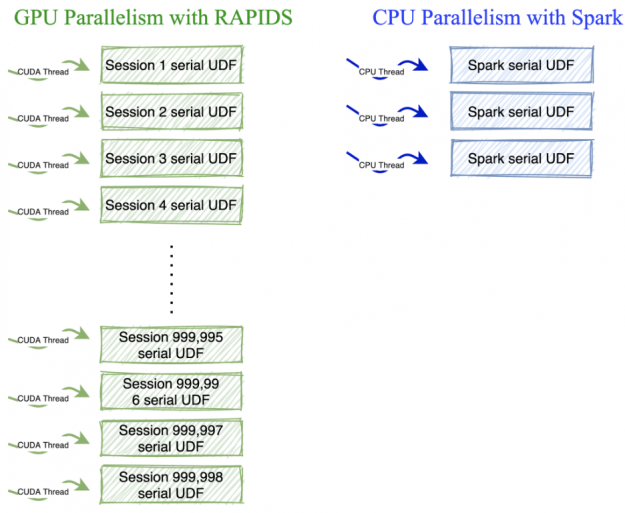
Dask-CUDA clusters use a single process and thread per GPU, so running a single sequential function won’t work for this model. To run serial functions on the hundreds of CUDA cores available in GPUs, you can take advantage of the following properties:
The function can be applied independently across keys.
The grouping key has high cardinality (there are a high number of unique keys)
Let’s look at how you can use Numba to transform our sessionization UDF for use on GPUs. Let’s break the algorithm into two parts.
Figure 1: Comparison b/w execution on CPUs and GPUs for the UDF.
Part 1. Session change flag
With this function, we create session boundaries. This function is embarrassingly parallel so that we can launch threads for each row of the dataframe.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
For session analysis, we have to set a unique session flag across all the rows that belong to that session for each user. This function is serial at the session level, but as we have many sessions (approx 18 M) in each dataframe, we can take advantage of GPU parallelism by launching threads for each session.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
We invoke the above functions on each partition of a dask-cudf dataframe using a map_partition call. The main logic of the code above is still similar to pure python while providing a lot of speedups. A similar serial function in pure python takes about `17.7s` vs. `14.3 ms` on GPUs. That’s a whopping 100x speedup.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
When working with serial user-defined functions that operate on many small groups, transforming the UDF using numba, as shown above, will maximize performance on GPUs. Thus, with the power of numba, Dask, and RAPIDS, you can now supercharge the map-reduce UDF ETL jobs to run at the speed of light.
Want to start using Dask and RAPIDS to analyze big data at the speed of light? Check out the RAPIDS Getting Started webpage, with links to help you download pre-built Docker containers or install directly via Conda.
About Vibhu Jawa
Vibhu Jawa is a software engineer and data scientist on the RAPIDS team at NVIDIA, where his efforts are focused on building GPU-accelerated data science products. Prior to NVIDIA, Vibhu completed his M.S at Johns Hopkins where his research was focused on Natural Language Processing and building interpretable machine learning models for healthcare.
About Ayush Dattagupta
Ayush Dattagupta is a software engineer on the RAPIDS team at NVIDIA, where he primarily works on accelerating data science workflows on the GPU. Prior to NVIDIA, Ayush received his M.S. degree in Computer Science from UCLA.