Deep learning models require vast amounts of data to produce accurate predictions, and this need becomes more acute every day as models grow in size and complexity. Even large datasets, such as the well-known ImageNet with more than a million images, are not sufficient to achieve state-of-the-art results in modern computer vision tasks.
For this purpose, data augmentation techniques are required to artificially increase the size of a dataset by introducing random disturbances to the data, such as geometric deformations, color transforms, noise addition, and so on. These disturbances help produce models that are more robust in their predictions, avoid overfitting, and deliver better accuracy.
In medical imaging tasks, data augmentation is critical because datasets contain mere hundreds or thousands of samples at best. Models, on the other hand, tend to produce large activations that require a lot of GPU memory, especially when dealing with volumetric data such as CT and MRI scans. This typically results in training with small batch sizes on a small dataset. To avoid overfitting, more elaborate data preprocessing and augmentation techniques are required.
Preprocessing, however, often has a significant impact on the overall performance of the system. This is especially true in applications dealing with large inputs, such as volumetric images. These preprocessing tasks are typically run on the CPU due to simplicity, flexibility, and availability of libraries such as NumPy.
In some applications, such as segmentation or detection in medical images, the GPU utilization during training is usually suboptimal as data preprocessing is usually performed in the CPU. One of the solutions is to attempt to overlap data processing and training fully, but it is not always that simple.
Such a performance bottleneck leads to a chicken and egg problem. Researchers avoid introducing more advanced augmentations into their models due to performance reasons, and libraries don’t put the effort into optimizing preprocessing primitives due to low adoption.
GPU acceleration solution
You can improve the performance of applications with heavy data preprocessing pipelines significantly by offloading data preprocessing to the GPU. The GPU is typically underutilized in such scenarios but can be used to do the work that the CPU cannot complete in time. The result is better hardware utilization, and ultimately faster training.
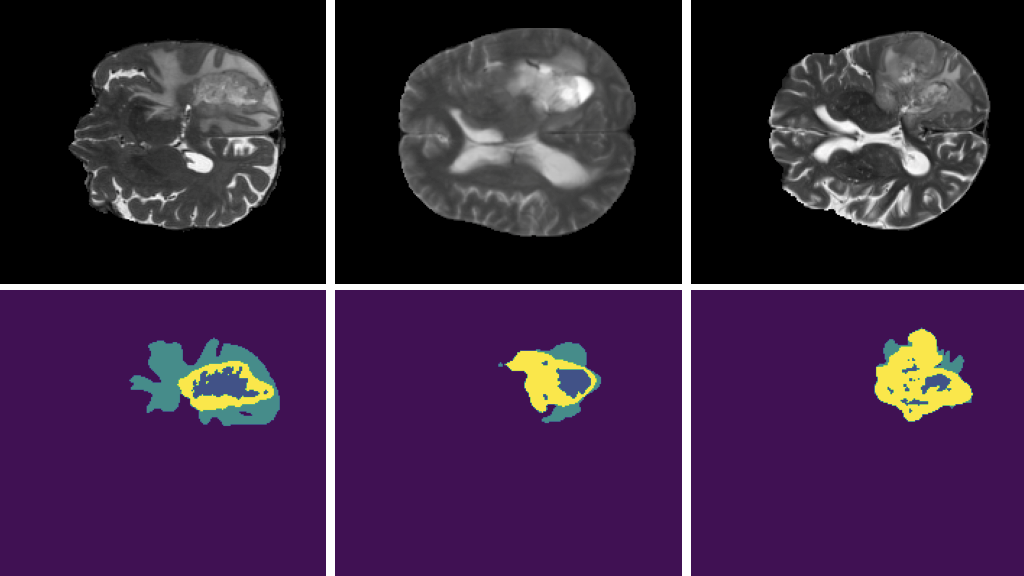
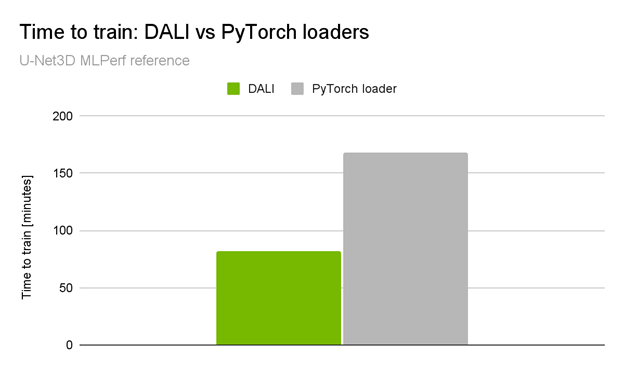
Just recently, NVIDIA took 3 out of 10 top places in the MICCAI 2021 Brain Tumor Segmentation Challenge, including the winning solution. The winning solution managed to reach a GPU utilization as high as 98% and reduced the total training time by around 5% (30 minutes), by accelerating the preprocessing pipeline of the system (Figure 1).
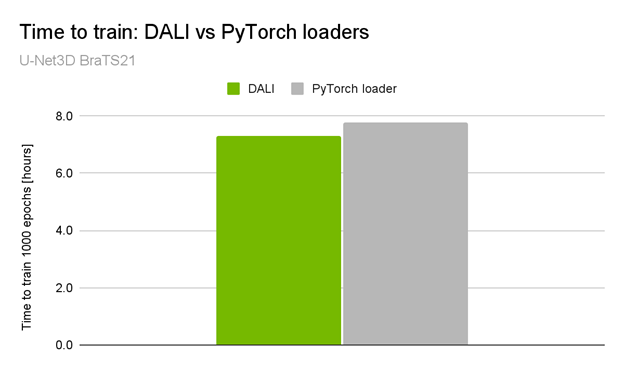
This difference becomes more significant when you look at the NVIDIA submission for the MLPerf UNet3D benchmark. It used the same network architecture as in the BraTS21 winning solution but with a more complex data loading pipeline and larger input volumes (KITS19 dataset). The performance boost is an impressive 2x end-to-end training speedup when compared with the native pipeline (Figure 2).
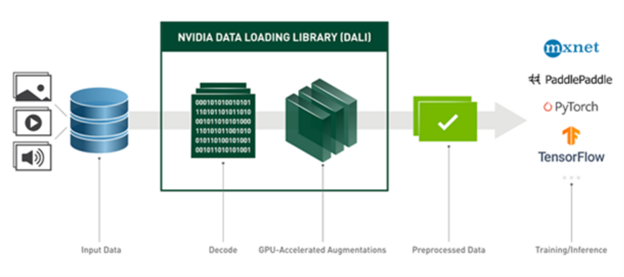
This was made possible by NVIDIA Data Loading Library (DALI). DALI provides a set of GPU-accelerated building blocks, enabling you to build a complete data processing pipeline that includes data loading, decoding, and augmentation, and to integrate it with a deep learning framework of choice (Figure 3).
Volumetric image operations
Originally, DALI was developed as a solution for images classification and detection workflows. Later, it was extended to cover other data domains, such as audio, video, or volumetric images. For more information about volumetric data processing, see 3D Transforms or Numpy Reader.
DALI supports a wide range of image-processing operators. Some can also be applied to volumetric images. Here are some examples worth mentioning:
- Resize
- Warp affine
- Rotate
- Random object bounding box
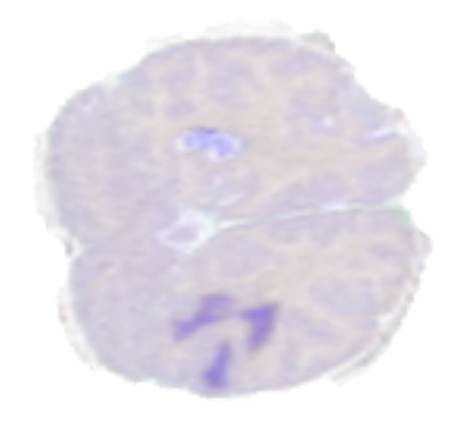
To showcase some of the mentioned operations, we use a sample from the BraTS19 dataset, consisting of MRI scans labeled for brain tumor segmentation. Figure 4 shows a two-dimensional slice extracted from a brain MRI scan volume, where the darker region represents a region labeled as an abnormality.
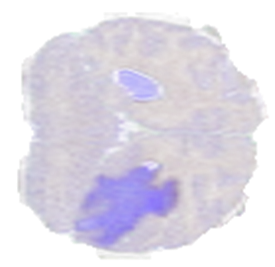
Resize operator
Resize upscales or downscales the image to a desired shape by interpolating the input pixels. The upscale or downscale is configurable for each dimension separately, including the selection of the interpolation method.
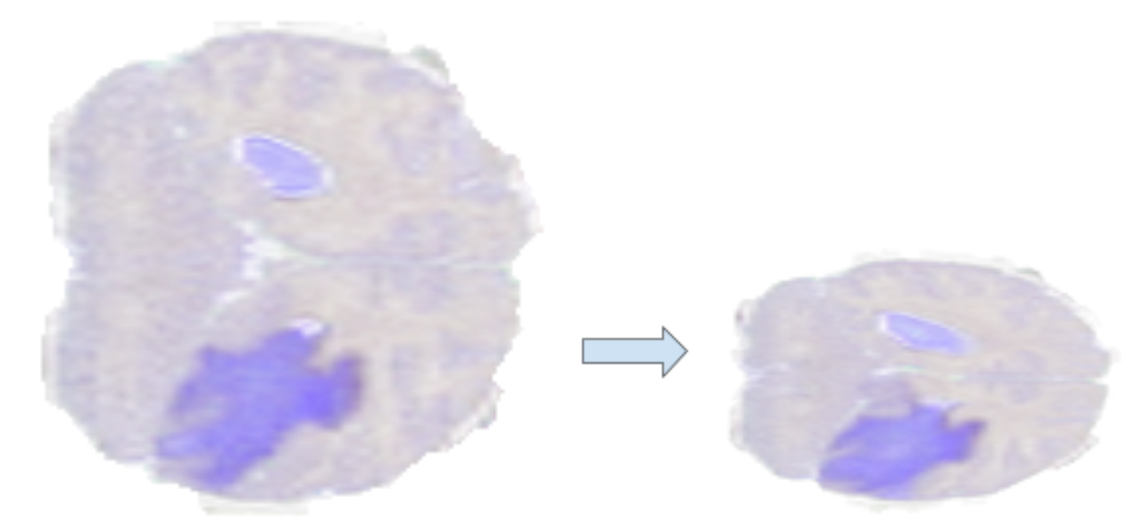
Warp affine operator
Warp affine applies a geometric transformation by mapping pixel coordinates from source to destination with a linear transformation.
\(Out(x,y,z)=In(xsrc,ysrc,zsrc)\)
Warp affine can be used to perform multiple transformations (rotation, flip, shear, scale) in one go.
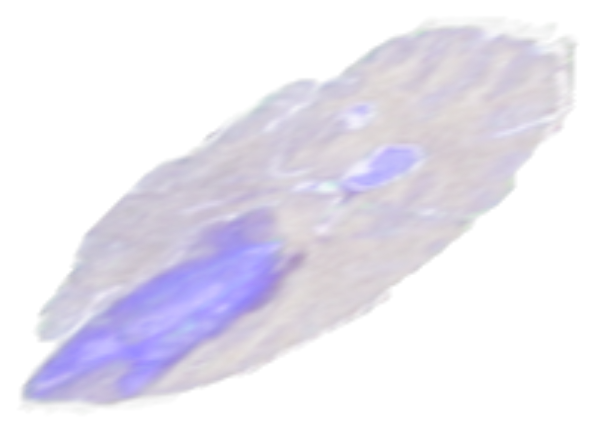
Rotate operator
Rotate allows you to rotate a volume around an arbitrary axis, provided as a vector, and an angle. It can also optionally extend the canvas so that the entire rotated image is contained in it. Figure 7 shows an example of a rotated volume.
Random object bounding box operator
Random object bounding box is an operator suited for detection and segmentation tasks. As mentioned earlier, medical datasets tend to be rather small, with target classes (such as abnormalities) occupying a comparatively small area. Furthermore, in many cases the input volume is much larger than the volume expected by the network. If you were to use random cropping windows for training, then the majority would not contain the target. This could cause the training convergence to slow down or bias the network towards false-negative results.
This operator selects pseudo-random crops that can be biased towards sampling a particular label. Connected component analysis is performed on the label map as a pre-step. Then, a connected blob is selected at random, with equal probability. By doing that, the operator avoids overrepresenting larger blobs.
You can also select to restrict the selection to the largest K blobs or specify a minimum blob size. When a particular blob is selected, a random cropping window is generated, within the range containing the given blob. Figure 8 shows this cropping window selection process.
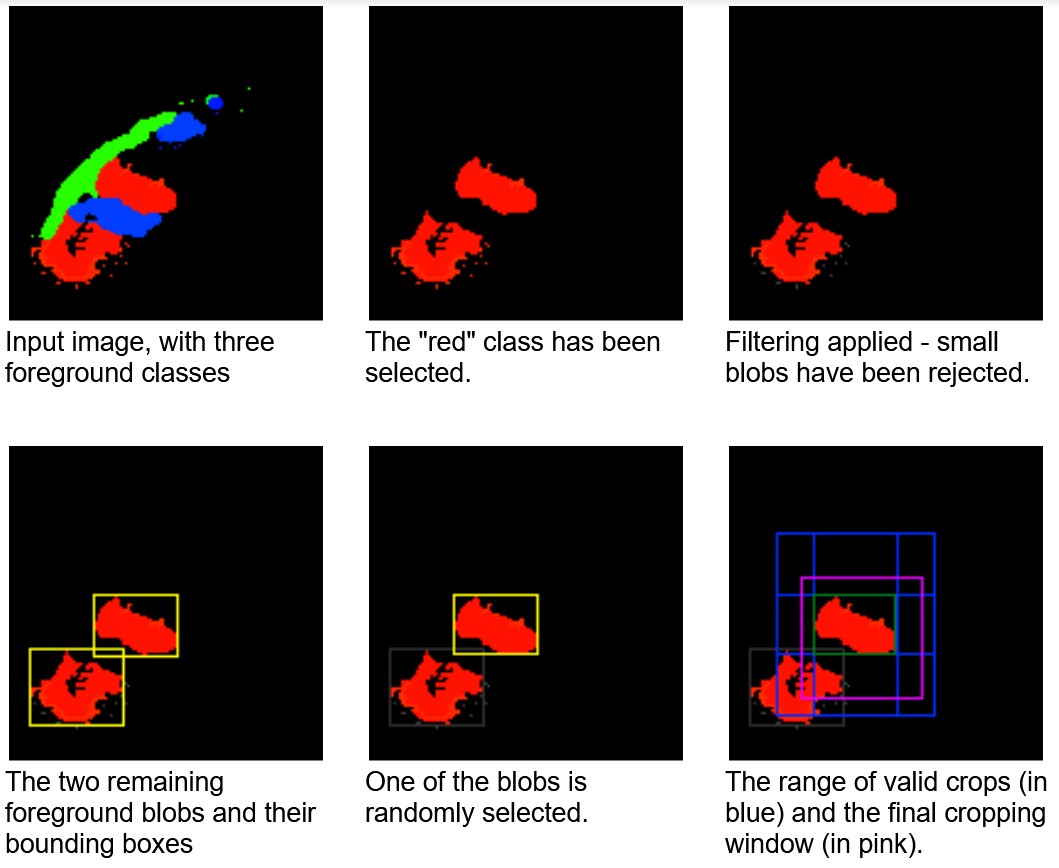
The gain in learning speed can be significant. On the KITS19 dataset, nnU-Net achieves the same accuracy in 2134 in the test run epochs with the Random object bounding box operator as in 3,222 epochs with random crop.
Typically, the process of finding connected components is slow, but the number of samples in the data set can be small. The operator can be configured to cache the connected component information, so that it’s only calculated during the first epoch of the training.
Accelerate on your own
You can download the latest version of the prebuilt and tested DALI pip packages. The NGC containers for TensorFlow, PyTorch, and MXNet have DALI integrated. You can review the many examples and read the latest release notes for a detailed list of new features and enhancements.
See how DALI can help you accelerate data preprocessing for your deep learning applications. The best place to access is the NVIDIA DALI Documentation, including numerous examples and tutorials. You can also watch our GTC 2021 talk about DALI. DALI is an open-source project, and our code is available on the /NVIDIA/DALI GitHub repo. We welcome your feedback and contributions.
