
With computation shifting from the CPU to faster GPUs for AI, ML and HPC applications, IO into and out of the GPU can become the primary bottleneck to the overall application performance.
NVIDIA created Magnum IO GPUDirect Storage (GDS) to streamline data movement between storage and GPU memory and remove performance bottlenecks in the platform, like being forced to store and forward data through a buffer in CPU memory.
GDS boosts bandwidth, reduces latency, and eases the burden on CPU utilization by enabling direct memory access (DMA) between local NVMe storage or remote storage behind a NIC and GPU memory. Performance benefits of 2.5x, 8x, and 9x have been observed on deep learning inference, data analytics visualization, and video analytics respectively from GDS itself on DGX platforms.

Bringing acceleration to a wide variety of customer applications and frameworks across the spectrum of deployed platforms involves a constellation of partnerships. Our objective is to enable the entire breadth of the rich data storage ecosystem consisting of almost 180 software and hardware vendors and more than 2500 contributors. For more information, see the SNIA website.
This post outlines the GDS ecosystem of partnerships and shares recent results from our partners.
GDS ecosystem
NVIDIA seeks to have an open ecosystem with a growing set of partnerships with vendors, framework developers, and end customers. Since the 1.0 product launch of GPUDirect Storage, an ecosystem of partner vendors has developed as depicted in Table 1.
Items within each category are listed in order of chronological appearance. Items not yet released and those that are in development are in italics. Items that are highlighted in yellow have data that’s new since the last GDS post published in this series.
| Vendor partners | Frameworks and applications | Systems software |
| File systems – DDN EXAScaler – Weka FS – VAST NFSoRDMA – EXT4 via NVMe or NVMoF drivers from MLNX_OFED – IBM Spectrum Scale (GPFS) – DELL Technologies PowerScale – NetApp/SFW/BeeGFS – NetApp/NFS – HPE Cray ClusterStor Lustre Block systems – Excelero – ScaleFlux smart storage | Storage -HDF5 – ADIOS – OMPIO Deep learning – PyTorch – MXNet Data analytics – cuDF – DALI – Spark – cuSIM/Clara – NVTabular Databases – HeteroDB for PostgreSQL acceleration Visualization – IndeX | – Ubuntu 18.04 – Ubuntu 20.04 – RHEL 8.3 – RHEL 8.4 – DGX BaseOS Compatibility mode only: – Debian 10 – RHEL7.9 – CentOS 7.9 – Ubuntu 18.04 (desktop) – Ubuntu 20.04 (desktop) – SLES 15.2 – OpenSUSE 15.2 |
| Contributions to a repo | Systems vendors | Media vendors |
| Readers – Serial HDF5 – IOR Containers – PyTorch/DALI Samples – Transparent threading – Buffer agnostic | – Dell – Hitachi – HPE – IBM – Liqid – Pavilion | – Kioxia – Micron – Samsung – Western Digital |
Vendor partners
We have several different kinds of vendor partners, and their offerings are at different levels of maturity. Vendor partners fall into two categories: those directly involved in GDS software enablement and those who provide system and component solutions.
GDS enablement partners at general availability
This section covers partners who actively enabled NVIDIA GPUDirect Storage into software stacks that they own, met the NVIDIA basic functional and performance criteria, and integrated it into a production solution that is at general availability.

- DDN integrated GDS into their Lustre-based EXAScaler parallel file system. They are working with the community to upstream GDS enablement to the open-source distribution.
- Dell Power Scale is an optimized implementation of NFS.
- IBM Spectrum Scale, formerly known as GPFS, is a widely used distributed parallel file system in HPC, data, and AI.
- The VAST parallel distributed file system pioneered offering NFS over RDMA (NFSoRDMA) with multipathing. VAST has also enabled GDS in NFSoRDMA in nconnect, to be available in the upstream version in the future.
- Weka integrated GDS in their own Weka FS parallel distributed file system.
Solutions and component providers at general availability
Several vendors are at a general availability level of support for GDS. Some provide a software solution that makes code changes to enable GDS, while others are component or system vendors on which GDS has been or will be exercised.
Vendors providing hardware or GDS characterization data
NVIDIA and our NPN and GPUDirect Storage partners have worked closely to qualify the full functionality of GDS. They also quantify the measured performance gains using a combination of their hardware and software solutions combined with the best GPU acceleration technologies that NVIDIA brings. These include the following.
System vendor partners who provide full end-to-end solutions using other GDS-enabled solutions, such as those available in MLNX_OFED, include the following:

- DDN
- Dell Technologies
- Hewlett Packard Enterprise
- IBM
- Pavilion
- VAST
Component vendors who we’ve worked most closely with include the following:

- Kioxia
- Micron
- Samsun
- ScaleFlux
Vendors expressing interest
Other vendors who have expressed strong interest in GDS include the following:
- Hitachi
- Liqid
- Western Digital
GDS enablement partners in development
Some partners have offerings that are available for your evaluation, but which have not yet reached maturity for general availability:

- The BeeGFS parallel distributed file system is commonly used in HPC. System Fabric Works has been working on the GDS enablement for BeeGFS in conjunction with NetApp.
- Excelero NVMesh transforms NVMe drives across any network into enterprise-grade protected shared storage that supports any local or distributed file system.
- HPE contributed to the upstreaming of its GDS-enabled Lustre parallel distributed file system code used in the Cray ClusterStor E1000 Storage System.
- NetApp is currently working on enabling server-side NFSoRDMA, so they can take advantage of others’ GDS enabling of NFS on the client side.
Vendor proof points with GDS
Since the last GDS post from NVIDIA, there have been several developments with new data. We share a sampling of these in this post as proof points that demonstrate the benefits and generality of GPUDirect Storage.
Configurations
GDS can add value from skipping the CPU bounce buffer on a variety of platforms, whether it’s a DGX system from NVIDIA or a third-party OEM platform. As noted in a previous post, Accelerating IO in the Modern Data Center: Magnum IO Storage, when a NIC-PCIe switch-GPU data path is available without going through the CPU, there’s a 2x difference in theoretical peak bandwidth available from GDS, though actual gains can be much larger in practice.
Within a DGX, the data path for some NIC slots must go past a CPU, while for others the direct NIC-PCIe switch-GPU path is available that bypasses the CPU. Figure 2 shows a labeled picture of the back of a DGX A100.
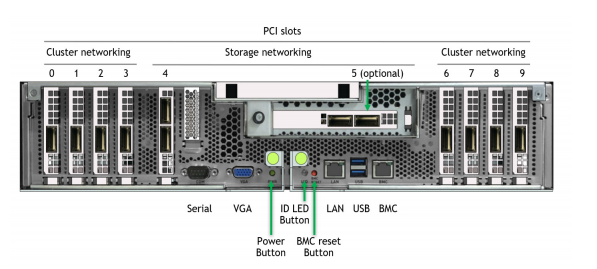
There are two configurations in which storage performance can be evaluated on a DGX A100. The approved standard configuration dedicates two “north-south” (toward the edge of the data center) NICs in slots 4 and 5 that are connected to the user management plane and external storage planes, and eight “east-west” (within the cluster) NICs in slots 0-3 and 6-9 that are connected to the inter-node compute plane.
We are moving toward enabling high-bandwidth storage to be accessible using the eight east-west NICs, thereby creating a converged compute-storage plane, pending the completion of QoS evaluations. For now, we call that an experimental configuration.
Previously presented partner data
Since the first GDS post, NVIDIA has publicly presented other vendor data. That included numbers from DDN EXAScaler, Pavilion NFSoRDMA, VAST NFSoRDMA, and Weka FS. Using the experimental 8-NIC configuration on a DGX A100, we’ve seen vendor-supplied bandwidths in the range of 152 to 178 GiB (186 GB/s) with GDS. Without GDS, they’ve reported bandwidths in the range of 40-103 GiB/s.
Moving forward, NVIDIA requests that any partners’ performance reporting for DGX systems report performance that includes 8-NIC data should also include the characterization on two north-south NICs. That data is not all in yet and so is not presented here. It’s our policy not to make direct performance comparisons across vendor partners.
VAST Data on Ethernet
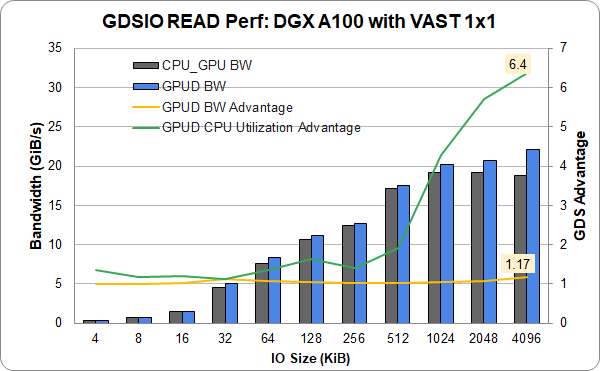
VAST Data Universal Storage was previously reported on InfiniBand. They’ve provided new results with a single (slot 4) NIC and 1 GPU in a DGX A100 with a VAST entry-level 1×1 configuration using Ethernet instead of InfiniBand. Ethernet shows full functionality and comparable performance. Achieving over 22 GiB/s from a single link is approaching maximal performance. This shows that GDS is equally applicable to Ethernet in addition to InfiniBand.
IBM Spectrum Scale
IBM Spectrum Scale (formerly GPFS) has a recent entry for their GA product. In their configuration, one ESS 3200 storage filer running IBM Spectrum Scale 5.1.1 delivered 71 GiB/s (77 GB/s). It was connected to two DGX A100s with a traditional storage network configuration, through NIC slots 4 and 5 with 4 HDR NICs. IO sizes were 1MB. As is normally the case, absolute performance rises with the number of threads used (Figure 4). Relative improvement of GDS compared to without GDS remains fairly stable with the number of threads, but it is clearly best with fewer threads.
Pavilion data results
Pavilion offers storage solutions for distributed parallel file systems, block, and object interfaces. It enables GDS with NFSoRDMA. Pavilion Data offers storage nodes which occupy four rack units (RU), supplying enough bandwidth that two of them can approximately saturate two NICs each on four DGX A100s or eight NICs on a single DGX A100. The results in Figure 5 are from an experimental configuration only, with version 2 of Pavilion’s software performing file accesses.
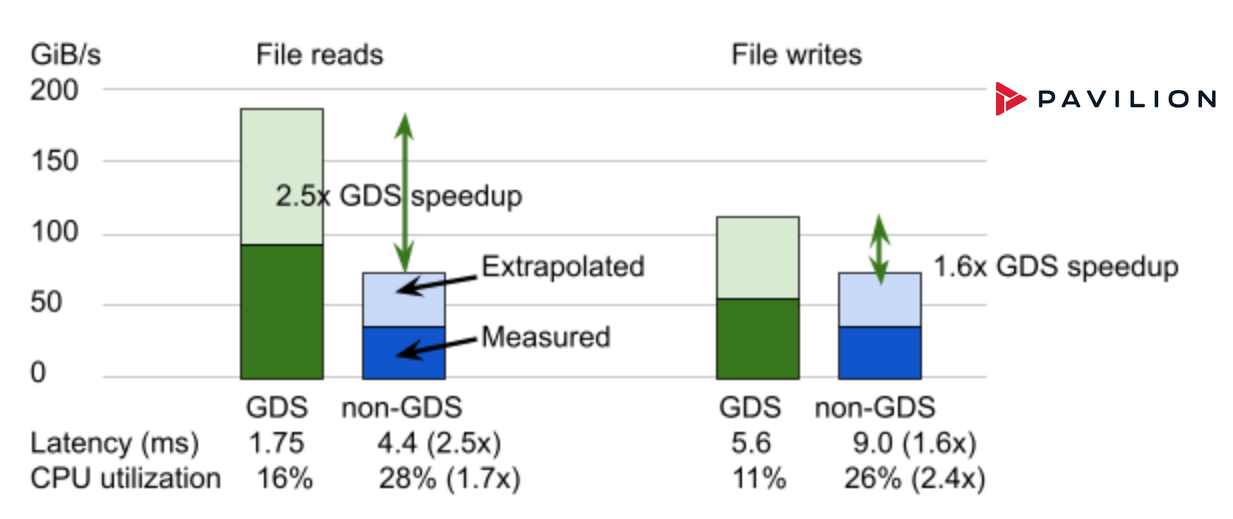
Liqid results
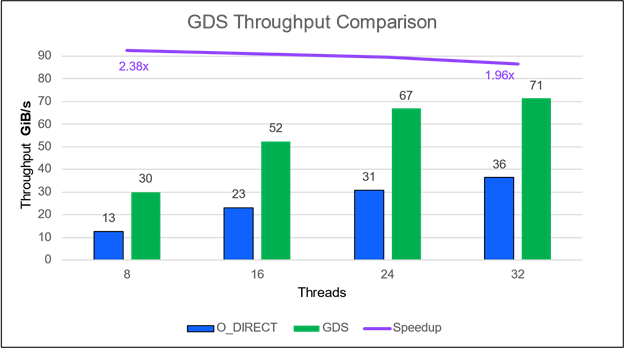
Recent measured performance on Liqid systems indicates that the PCIe-based P2P path is faster than NVMe-oF over Ethernet/InfiniBand. The P2P communication between GPU and SSDs integrated with GDS achieves up to 2900K IOPS which is a 16x improvement in throughput. Latency is improved 1.86x to 112 us from 712 us compared to the non-GDS path (Figure 6).
GPU to SSD w/ P2P Disabled
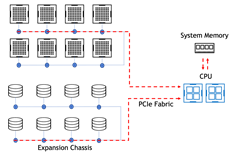
IOPS Latency: 712 us
GPU to SSD w/ P2P Enabled with GDS
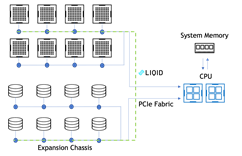
IOPS Latency: 112 us
Data was collected on three different configurations:
- Config #1: GPU-to-NVMe. Uses the Liqid fabric to connect all devices on the same PCIe fabric.
- Config #2: GPU-to-CPU-to-NVMe. Connects each of the GPU and NVMe drives directly to the CPU motherboard.
- Config #3: GPU-to-NIC-NIC-NVMe-oF. Uses the GPU to NVMe-oF (CX-5) to access remote NVMe over the network.
Here are the details of the configuration:
- Motherboard: AsROCK Rack ROME8D-2T, with AMD Epyc 7702p, 512GB DDR4 2933
- System software: Ubuntu Server 20.04.2, NVIDIA Driver Version 470.63.01, CUDA 11.4
- Liqid QD4500 equipped with Phison E16 800GB, Gen4 PCIe, 24 Port Management Switch (TORs) running Liqid v3.0, 24 Port Gen4 Data Switch (Astek)
- NVIDIA A100 40GB with PCIe Gen4 on the same PCIe switch as the LQS4500
- BIOS set ACS = Off, P2P enabled in Liqid.
Figure 6. Peer-to-peer (P2P) communication between GPU and SSD (or a NVMe drive) achieves orders of magnitude improvement in IOPS with GPUDirect Storage. GPUDirect Storage in Liqid Matrix expansion chassis enables direct P2P communication between GPU and SSDs achieving up to 1620% speedup in IOPS and 86% improvement in latency.
InfiniBand and Ethernet
While Infiniband is popular in traditional HPC systems, Ethernet has a wide presence in the enterprise data centers. GDS works ubiquitous on both Ethernet and IB. The key requirement is that the underlying system and remote filer support RDMA. This is possible with RoCE.
So how do the two compare? Here are some results from initial investigations. A thorough analysis of access to storage through scaled networks is out of scope for this post but is encouraged for those who’d like to make data-driven decisions about their network design.
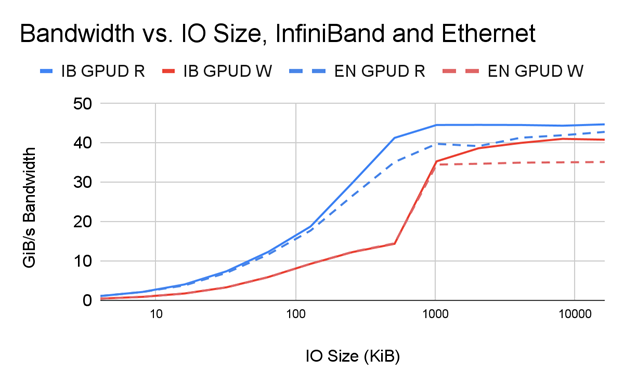
Figure 7 shows a side-by-side comparison of bandwidth as a function of IO size under the following conditions:
- Two NICs in a single PCIe tree are connected to one DDN AI400x filer using InfiniBand
- Two NICs in a single PCIe tree are connected to the same DDN AI400x filer using Ethernet
As you can see, performance is comparable between IB and Ethernet with GDS, which is obviously built on top of GPUDirect RDMA. IB up to a 1.17x performance advantage over Ethernet, especially at larger IO sizes where performance is highest and network speeds are most differentiated.
Community Lustre
Various vendors add their own value with respect to the community version of Lustre. But some of our customers are limited to using the OSS community Lustre. Can they also enjoy the goodness of GDS in a non-proprietary solution? The answer is yes!
Bandwidth, latency, and CPU utilization gains for GDS compared to without GDS are all similar to those of other GDS-enabled implementations. A per-release version of version 2.15 is available for download. Try it today!
Mix and match
We have an experimental cluster at NVIDIA that we call ForMIO (for Magnum IO), because it’s used to evaluate and vet various technologies that pertain to Magnum IO (MIO). DDN and Pavilion generously let us use their equipment for filers. Media vendors Kioxia, Micron, and Samsung generously contributed drives to populate some of those filers. We’re excited, since this is accelerating evaluations of DL frameworks and customer applications using GDS.
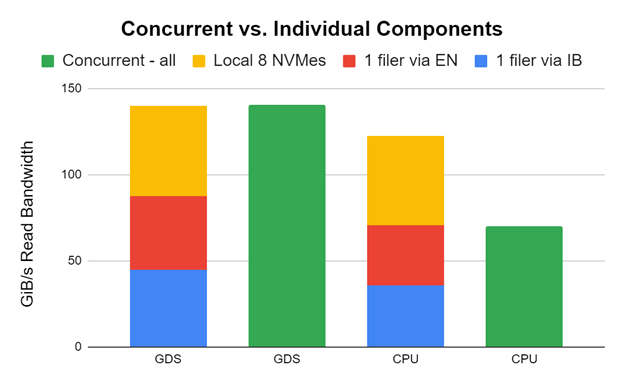
We tried something crazy and it worked! We hooked up one DDN AI400x with InfiniBand using two HDR200 NICs, one DDN AI400s with Ethernet with two HDR200 NICs, and eight local NVMes to a single DGX A100. We performed a run with the GDSIO performance evaluation tool across all.
The early and untuned results in Figure 8 show that storage bandwidth can be combined across these to supply bandwidth to applications. While we wouldn’t necessarily recommend this in practice, it’s cool to know that it’s possible. Thanks to DDN for supporting enabling this.
Performance of each of one DDN AI400x with InfiniBand using two HDR200 NICs, one DDN AI400s with Ethernet with two HDR200 NICs, and eight local NVMes are measured separately (red, blue, yellow) and concurrently (green) on a single DGX A100. The individual components are stacked on the left of each pair. The green bar shows performance when they are all run concurrently.
In the GDS case, performance matches perfectly, as the GPU targets are carefully selected to be non-interfering. In the non-GDS case that uses a bounce buffer in the CPU, there is congestion getting to and from the CPU that inhibits the concurrent performance. There’s a dramatic difference.
Summary
We encourage you to deploy production solutions based on products that are now at general availability, and to consider working emerging solutions into your next-generation systems. With GPUDirect Storage now at v1.0 general availability, more vendor partners are moving to GA status for GDS-enabled offerings. There are also a range of case studies that span storage frameworks, deep learning, seismic, data analytics, and databases.
Partnering on GDS
NVIDIA encourages engagement with vendor partners and customers with clear use cases. If you’re interested, reach out to our team. We would love to hear more about your forthcoming scaled end-to-end GDS-enabled storage solutions. We recommend the following resources to vendor partners who are ready to enable storage drivers with GDS:
- For end customers and OEMs, see the NVIDIA GPUDirect Storage Design Guide.
- For end customers, OEMs, and partners, see the NVIDIA GPUDirect Storage Overview Guide.
- For more information about programming with GDS, see the cuFile API Reference Guide.
- For more information about enabling GDS in a storage system or working through vendor partner support, see NVIDIA GPUDirect Storage O_DIRECT Requirements Guide.
- For general information, see the NVIDIA GPUDirect Storage documentation.
- For a video explanation, see the Accelerating Storage with Magnum IO and GPUDirect Storage GTC 2020 session.
We hope you can join the upcoming SC21 Birds of a Feature session, Accelerating Storage IO to GPUs.
Contributing to GDS
The GDS kernel driver described here, nvidia-fs.ko, is open source. In the MagnumIO/tree/main/gds GitHub repo, there is code checked into mainline or available as pull requests that the community has begun contributing, to accelerate development and to improve community-wide performance. Come be a part of the community and watch that space for new developments!
Acknowledgements
Thanks to the following vendors who granted or lent equipment for evaluation or who provided NVIDIA with performance characterization data of their own on their OEM platforms or with their components: DELL Technologies, DDN, Excelero, IBM, Kioxia, Micron, Pavilion, Samsung, ScaleFlux, VAST, and Weka.
