图形神经网络 (GNN) 彻底改变了图形结构数据的机器学习。与传统神经网络不同,GNN 擅长捕捉图形中的复杂关系,为从社交网络到化学领域的应用程序提供动力支持。在节点分类和边链预测等场景中,GNN 可预测图形节点的标签,并决定节点之间的边是否存在。
在单个前向或反向通道中处理大型图形会非常耗费计算资源和内存。
大规模 GNN 训练的工作流通常从子图形采样开始,以便使用 mini-batch 训练。这包括收集特征,以便在子图形中捕捉所需的上下文信息。随后,提取的特征和子图形将用于神经网络训练。在这一阶段,GNN 能够整合信息并实现节点知识的迭代传播。
但是,处理大型图形会带来挑战。在社交网络或个性化推荐等场景中,图形可能包含大量节点和边缘,每个节点都携带大量特征数据。
节点特征数据每个顶点的大小可能达到几千字节,因此节点特征数据的总大小可以轻松超过图形拓扑数据的大小。对于大型工作负载而言,有时需要使用大容量 (key,value) 存储。
本文介绍了 RAPIDS cuGraph 库中的新功能 WholeGraph.WholeGraph 是一种类型的图形存储,可与 PyG、cuGraph-PyG、DGL、cuGraph-DGL,和 cuGraph-Ops 来加速大规模 GNN 训练。
为什么选择 WholeGraph?
WholeGraph 提供由多个内存 (例如固定主机内存和设备内存) 支持的大容量、高性能存储抽象,这种灵活性使得 WholeGraph 能够使用适用于特定任务或系统配置的合适内存类型优化性能。
WholeGraph 存储可跨多个节点的多个 GPU 覆盖。远程内存访问使用 NVIDIA NVLink P2P 内存访问或使用 NCCL 进行批量传输。
此外,借助本地 PyTorch 支持和与 torch DistributedDataParallel 模式的兼容性,WholeGraph 可在多个 GPU 上高效分配训练流程,从而增强大规模图形数据集的可扩展性和内存优化。
WholeGraph 的作用
WholeGraph 旨在帮助训练大规模 GNN.WholeGraph 提供了一种名为 WholeMemory 的底层存储结构 .WholeMemory 是一种类似于张量的存储结构 .WholeMemory 可以高效地组织和操作多维数据,类似于深度学习框架中的张量。
此外,它还提供多 GPU 支持,因此非常适合 NVIDIA DGX A100 服务器等 NVLink 系统。通过使用 cuGraph、cuGraph-Ops、cuGraph-DGL、cuGraph-PyG、上游 DGL 和 PyG,您可以轻松构建 GNN 应用。
WholeMemory
WholeMemory 可视为多个 GPU 上显存的完整 (即整体) 视图。无论底层数据如何存储在多个 GPU 上,WholeMemory 都会公开显存实例的把握。
因为多个 GPU 共享 WholeMemory,因此每个 GPU 都需要访问 WholeMemory 空间,因此必须进行地址映射 .WholeMemory 提供三种地址映射模式:连续、分块和分布式。
连续模式:每个 GPU 的所有显存都会映射到每个 GPU 的单一连续显存地址空间中。GPU 可以使用单个指针和偏移来直接访问显存,就像使用常规设备显存一样。软件无法区分这种模式。硬件将处理 P2P 显存访问所需的通信。
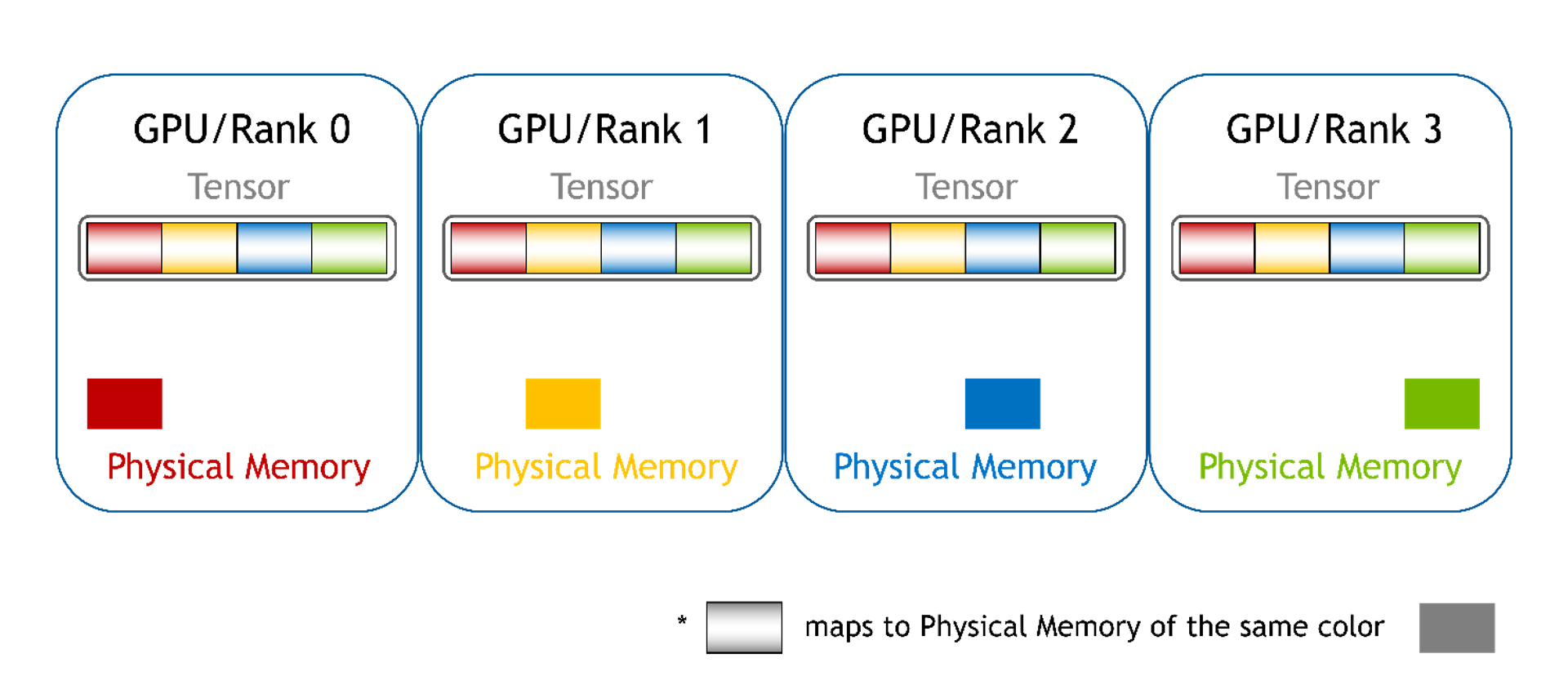
分块:每个 GPU 的显存都映射到不同的显存块中,每个 GPU 都有一个块。对于 PyTorch,这可以是一个张量列表。在此,我们仍然可以使用指针和偏移来访问数组元素,但是有多个指针 (每个块有一个指针)。用户必须根据全局偏移来选择正确的指针,并且必须为选择的显存块计算新的本地偏移值。
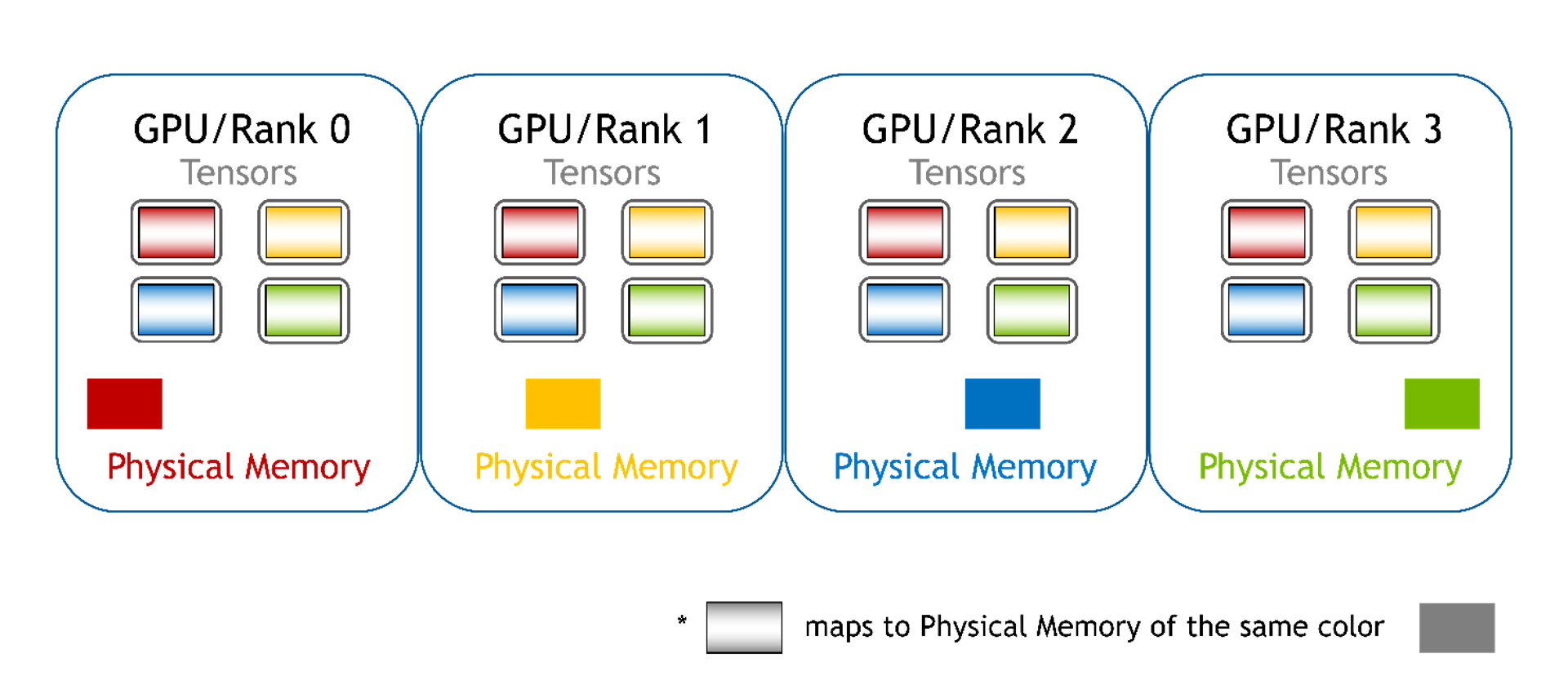
分布式:其他 GPU 的内存未映射到当前 GPU,也不支持直接访问。在此模式下,用户无法再使用指针访问数组元素,必须使用 WholeMemory 提供的函数访问数组元素。此类 WholeMemory 模式可用于创建多节点存储。
总而言之,连续模式提供简单的内存访问,块模式提供了高效管理内存的方法,而分布式模式允许多节点存储,但需要额外协调来访问跨 GPU 的数据。每种模式都有自己的优缺点,具体取决于应用程序和系统配置的特定要求。
除了使用 GPU 显存,WholeMemory 还支持使用固定主机显存。主机显存可以通过两种方式进行固定:一种是连续固定,允许多个进程共享相同的显存;另一种是分布式固定,适用于跨多个节点运行的应用。
WholeMemory 嵌入
与大规模 GNN 训练类似,收集节点特征需要耗费大量时间。此外,在可训练特征的节点特征 (嵌入) 数据中,需要读取和写入访问。为了帮助加速特征收集或更新可训练特征,WholeGraph 为特征存储引入了 WholeMemory 嵌入。
与 WholeMemory Tensor 对象相比,WholeMemory Embedding 具有以下两个额外特性:
- 首先,WholeMemory Embedding 支持缓存。它可以在多 GPU 或多节点运行中在本地 GPU 或本地节点中存储常用特征。或者,它可以在设备内存中存储主机存储。
- 第二个特性是对可训练特征的稀疏优化器的支持。借助稀疏优化器,仅会更新受影响的特征,从而加快训练过程。
WholeMemory 框架集成
尽管几乎所有功能都以 Python 对象或函数的形式公开,但与深度学习框架无缝集成可为开发者提供便利,因此 WholeMemory 提供了 dlpack capsule,可将 WholeMemory 对象转换为适用于深度学习框架的张量。支持的转换方法取决于 WholeMemory 的地址映射模式类型。
- 对于分布式全内存,无法映射至远程内存。仅可将本地内存转换为 dlpack capsule,然后转换为深度学习 (DL) 框架的张量。
- 对于分块的全内存,可以映射至远程内存。从所有秩中的内存块可以转换为一个 dlpack 容器列表,并导入到 DL 框架中作为一个张量列表。
- Continuous WholeMemory 具有完整的功能,并且将内存映射到单个连续内存地址空间中。这可以转换为单个 dlpack capsule,并通过 DL 框架作为单个张量导入。张量与 DL 框架中的其他张量几乎相同,但存储在多个 GPU 上。张量由多个进程共享,并且可以非常大。
入门指南
首先,您需要安装 WholeGraph 软件包,可以使用 conda 进行安装,也可以从源代码安装
安装
若要使用 conda 进行安装,只需运行:
> conda install -c rapidsai pylibwholegraph
要从源代码构建,首先,从 GitHub 获取代码:
> git clone https://github.com/rapidsai/wholegraph.git
接下来,前往 WholeGraph 目录并运行 build.sh 脚本。该脚本将从源中构建并安装在该包中。请务必确保所有要求已安装为文档。
> cd wholegraph
> bash build.sh
使用 WholeGraph
在讨论使用 WholeGraph 的场景时,我们将以 1.11 亿篇论文的 ogbn-papers100M 数据集为例。该数据集由 Microsoft Academic Graph 提供,每个节点都包含了 128 维的特征嵌入。在这个示例中,WholeGraph 用于存储特征嵌入表。
要使用 WholeGraph,我们必须将数据转换为 WholeGraph 读取的二进制格式。假设特征嵌入位于名为 feat_array 的 numpy 数组中,则可以通过以下命令完成:
…
with open('feat_data.bin', 'wb') as f:
feat_array.tofile(f)
数据存储在名为feat_data.bin我们可以使用 WholeGraph 加载该数据集并训练 GNN 模型 .ogbn-papers100M 数据集的完整预处理脚本可以在 GitHub 中找到。
在使用 WholeGraph 之前,需要初始化 WholeGraph 多进程环境:
import pylibwholegraph.torch as wgth
wgth. init_torch_env(world_rank, world_size, local_rank, local_size)
下一步是创建一个定义创建 WholeMemory 所使用的 GPU 集的通信器。例如,在本地计算机节点上创建一个通信器,包含所有 GPU:
local_comm = get_local_node_communicator()
初始化 WholeGraph 多进程环境和创建通信器的两个步骤可以合并为一个调用,从而创建两个最常用的通信器。一个是本地机器节点上的所有 GPU 通信器,另一个是所有机器节点上的所有 GPU 通信器。
global_comm, local_comm = wgth.init_torch_env_and_create_wm_comm(
world_rank, world_size, local_rank, local_size)
然后,可以创建 WholeMemory 嵌入,以存储节点特征。以下代码片段在本地计算机节点的所有 GPU 上创建嵌入表。在本例中,WholeMemory 类型是分块。我们不需要缓存或稀疏优化器,因此不需要指定相关参数。
node_feat_wm_embedding = wgth.create_embedding_from_filelist(
local_comm,
"continuous",
"cuda",
os.path.join(node_feat_path, "node_feat.bin"),
torch.float,
128
创建 WholeMemory 嵌入后,我们使用 gather 方法来收集特征。indices和gathered_feature都是 PyTorch 张量。
gathered_feature = node_feat_wm_embedding.gather(indices)
除了使用 WholeMemory Embedding 对象外,我们还可以通过调用 WholeMemory Embedding 的 get_embedding_tensor 方法获取 WholeMemory Tensor 对象:
node_feat_wm_tensor = node_feat_wm_embedding. get_embedding_tensor()
不同类型的 WholeMemory 张量可以映射到 PyTorch 张量或张量。
例如,连续 WholeMemory Tensor 可通过以下方式映射到单个 PyTorch Tensor:
node_feat_pytorch_tensor = node_feat_wm_tensor. get_global_tensor()
在这里,node_feat_pytorch_tensor是 PyTorch Tensor,任何 PyTorch 运算符都可以直接使用它,而底层存储可能是多个 GPU 上的内存。
WholeMemory 嵌入表都可以用于 GNN 训练,GitHub。
总结
WholeGraph 提供了简单的实施方式,通过更少的代码更改简化了多 GPU 或多节点存储设置。此外,RAPIDS 团队还在 WholeGraph 中不断添加新功能并优化性能,欢迎阅读此博客文章,详细了解 WholeGraph 的基准测试,用于收集功能和 GNN 端到端训练任务。
您可以通过以下链接访问WholeGraph GitHub,并可以在该页面提交问题和问题。