协同学习 (FL) 受到加速采用的原因在于其分布式、保护隐私的特性。在医疗健康和金融服务等领域,协同学习 (FL) 作为一种隐私增强技术,已成为技术堆栈的关键组成部分。
在本文中,我们讨论了 FL 及其优势,深入探讨了联邦学习为何如此受欢迎。此外,我们还介绍了 NVIDIA FLARE 2.4.0 版本中引入的三个关键特征,这些特征有助于从集中式机器学习过渡到联邦学习,并通过流式传输 API 增强大型语言模型 (LLM) 支持。此外,我们还展示了各种参数调整任务。
最新版本的 FLARE 扩展了 FL 工作流模式,为研究人员提供更多工作流程自定义选项。我们分享了医疗健康、银行、金融服务和保险 (BFSI) 领域的不同用例,以展示 FL 应用程序在生产环境中或通过示例。
分布式数据时代的联邦学习
FL 是一种机器学习方法,允许在分布式设备上进行模型训练和数据分析,同时保护本地数据的私密性。与传统的集中式训练相比,FL 允许在本地进行模型训练,并仅共享模型更新而不是原始数据,从而实现协同学习,而不会损害数据治理和隐私。
虽然 FL 面临通信延迟和确保模型一致性等挑战,但它在隐私保护、效率和安全方面具有显著优势。
NVIDIA FLARE(NVIDIA 联邦学习应用程序运行时环境)是一个广泛采用的开源联邦学习框架,它提供了多种机器学习和深度学习算法的示例。FLARE 具有强大的安全特性、先进的隐私保护技术,并且提供了一个灵活的、与模型无关的架构。
FLARE 在各个维度上具有许多优势,因此在数据分布和隐私是首要问题的场景中,它是一种强大的方法。
随着对数据隐私法规的担忧日益增加,以及对更多数据的需求,以训练更先进的机器学习模型,对隐私增强技术(PET),包括联邦学习(FL)和机密计算,在近几年出现了显著增长。
以下是一些主要优势:
- 隐私保护
- 数据多样性
- 合规性
- 安全性
隐私保护
模型在本地进行训练。在 FLARE 中,只共享模型更新或模型差异,而私人数据则保留在客户端。通过安全的聚合来保护模型更新期间的信息泄露。
数据多样性
客户数据的多样性对于稳健的模型开发至关重要。这种多样性尤其包括来自罕见事件的数据,可避免偏差并使模型能够借助 FLARE 有效学习。
合规性
随着数据隐私保护意识的增强,越来越多的组织和政府颁布规定来保护个人数据。例如,欧盟的 通用数据保护条例(GDPR) 和中国的 个人信息保护法(PIPL)。这些法规严格限制了个人数据在不同地区之间的传输。
此外,还有行业特定的法律法规,如 HIPAA(健康保险可移植性和负责任性法案),旨在保护用户的个人数据不被泄露。FLARE 通过将计算引入数据,而不是移动数据,成为实现 AI 计划的关键,从而避免了违反这些法规的风险。
安全性
FLARE 提供了分布式安全执行。本地机构 (银行、医院等) 可以选择添加特定于组织的额外安全检查或策略
借助 NVIDIA FLARE 轻松实现联邦学习
如何快速利用 FL 并使用 LLM 构建多模态基础模型已成为许多政府机构、金融机构、医疗健康和药物研发行业的热门话题。
在 FLARE 2.4.0 版本中,我们引入了新功能,使开发联邦学习变得非常简单,包括客户端 API。通过少量代码更改,您可以在几分钟(而非几天)内轻松将预先存在的集中式深度学习代码转换为联邦学习代码。
以下代码示例展示了在使用客户端 API 进行客户端训练时的常见模式:
# import nvflare client API
import nvflare.client as flare
# initialize NVFlare client API
flare.init()
# run continuously when launching once
while flare.is_running():
# receive FLModel from NVFlare
input_model = flare.receive()
# loads model from NVFlare
net.load_state_dict(input_model.params)
# perform local training and evaluation on received model
{existing centralized deep learning code} ...
# construct output FLModel
output_model = flare.FLModel(
params=net.cpu().state_dict(),
metrics={"accuracy": accuracy},
meta={"NUM_STEPS_CURRENT_ROUND": steps},
)
# send model back to NVFlare
flare.send(output_model)
了解这些易于使用的 API 的关键是,几乎所有的 FL 算法都涉及以下步骤:
- 从聚合器或同级客户端接收全局模型。
- (可选) 评估模型。
- 更新本地模型,并使用多次训练执行本地模型训练。
- 将新更新的本地模型发送回聚合器或其他对等客户端。
FLARE 客户端 API 可轻松实现以下操作:
flare.init:初始化。flare.receive:接收模型。flare.send:返回模型。flare.is_running:检查是否已完成整体训练。
借助这些 API,您无需重构现有代码或编写新类。只需在现有代码相关部分中插入 API 命令,即可在几分钟内完成代码转换。
对于 PyTorch Lightning,更改简单得多。应用修补程序到训练器实例:
flare.patch(trainer):向训练器添加回调函数,以执行flare.receive和flare.send功能。
模型可以存储在数据结构中,FLModel.
class FLModel:
def __init__(
self,
params_type: Union[None, str, ParamsType] = None,
params: Any = None,
optimizer_params: Any = None,
metrics: Optional[Dict] = None,
start_round: Optional[int] = 0,
current_round: Optional[int] = None,
total_rounds: Optional[int] = None,
meta: Optional[Dict] = None,
):
数据结构经过精心设计,通用性强,不会引入任何特定于 FLARE 的概念或结构,仅包含数据科学家已经了解的概念:
params:权重参数optimizer_params:优化器参数meta:元数据。
这个新的客户端 API 简化了从 FL 过渡的过程,对最终用户来说是一个变革性的举措。
要了解客户端 API 及其用法,请查阅 ML 到 FL 示例,并阅读 客户端 API 文档。此外,还有更多示例,包括分步教程系列,这些教程使用客户端 API 编写 训练脚本。
在 LLM 时代的联邦学习
LLM 的主要特征是其庞大的规模,通常包含数十亿个参数。联邦学习需要用户将其本地模型参数发送到位于不同地区或国家的模型聚合器,以构建全局模型。在这种情况下,有效地在网络上传输这种庞大的模型需要一个强大的框架。为了解决这一挑战,FLARE 开发了专为此类任务打造的流 API。
流式传输 API
LLM 的大小可能很大,例如,7B 参数模型大约为 14 GB。要在网络上传输这些大型对象,您必须克服不同通信协议带来的限制。
为支持 LLM,FLARE 2.4.0 版本引入了流式传输 API,以便帮助超过 gRPC 设置的 2 GB 大小限制的对象进行传输。新增的流式传输层旨在处理大型对象,使您能够将大型模型划分为 100 万个数据块并将其流式传输到目标。
借助此流式传输 API,您可以跨区域 (如美国到印度) 和各种云提供商 (如 Azure 到 AWS) 传输不同大小的模型。我们使用 128 GB 对象进行负载测试。
想了解更多相关信息,请参阅 nvflare.fuel.f3.stream_cell 模块 和 大型模型 的说明。
联邦 LLM 参数调优
FLARE 2.4.0 版本展示了 使用 NVIDIA NeMo 的 LLM 示例,演示了如何在联邦设置中执行提示调整、监督调整和参数效率调整。
提示调整
提示调整是用于训练语言模型的技术,尤其是用于针对特定任务或领域微调模型的技术。相比于从头开始训练整个模型,提示调整重点是调整模型在推理或生成期间接收到的提示或指令。
联邦提示调整允许用户在本地进行模型提示调整,然后在全局范围内聚合参数。
在这个示例中,我们利用了提示学习的特点,展示了如何将LLM(大型语言模型)调整应用于特定的下游任务,如金融情绪预测。示例中展示的提示学习技术是p-tuning,即在LLM中加入一个小提示编码器网络,用于生成虚拟令牌,从而引导模型朝着下游任务预期的输出方向发展。
欲了解更多信息,请查阅 使用 NeMo 进行快速学习。
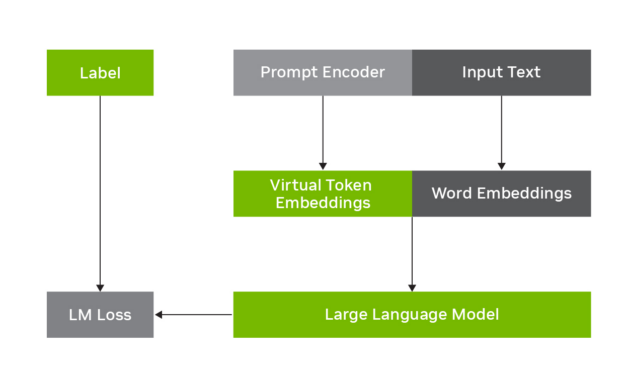
图 1 展示了 p-tuning 如何用于 LLM 的调整。它涉及冻结 LLM 并学习预测与原始输入文本相结合的虚拟标记嵌入。
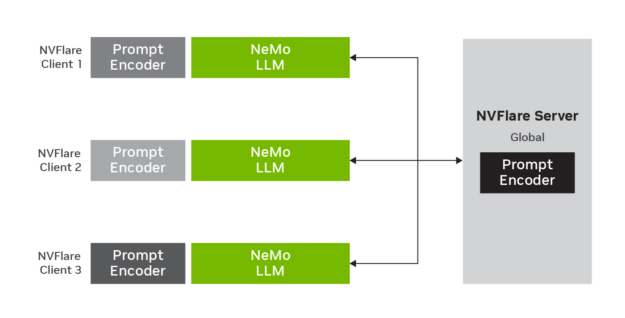
图 2 展示了联邦学习环境中 p-tuning 如何与 LLM 配合使用 .LLM 参数保持不变,但提示编码器参数在 FLARE 服务器上进行训练、更新和聚合。
在这个示例中,我们利用了提示学习的特点,展示了如何将LLM(大型语言模型)调整应用于特定的下游任务,如金融情绪预测。示例中介绍的提示学习技术是p-tuning,即在LLM中加入一个小提示编码器网络,用于生成虚拟令牌,从而引导模型朝着下游任务预期的输出方向发展。
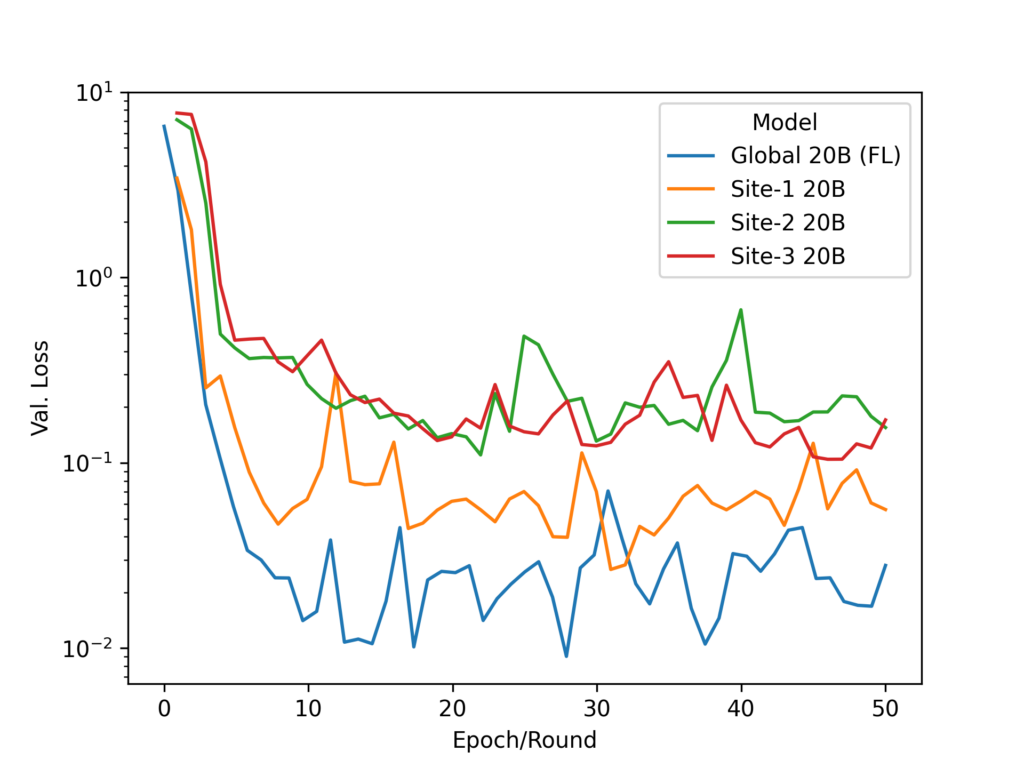
在联邦实现中,我们使用了 20B 参数模型。虽然 LLM 参数保持不变,但提示编码器参数在 FL 服务器上进行训练、更新和平均。
监督式微调
我们还利用了 NeMo 的 监督式微调(SFT) 功能,展示了如何在监督数据上微调整个模型,以学习如何遵循用户指定的指令。有关更多信息,请参阅 监督式微调。
三个客户端 13 亿 GPT 模型实验的示例可在三个 32 GB NVIDIA V100 GPU 或一个 80 GB NVIDIA A100 GPU 上执行。
由于 LLM 的模型规模较大,因此我们使用 FLARE 串流功能将模型分块传输。
参数效率的精细调整
参数高效微调 (PEFT) 是一种热门技术,用于高效微调 LLM,以便在各种下游任务中使用。
使用 PEFT 进行微调时,基础模型权重冻结,并将几个可训练的适配器模块注入模型,从而产生少量 (通常 <1%) 的可训练权重。
通过选择合适的适配器模块和注入点,PEFT 实现了与全量化训练相当的性能,同时计算和存储成本远低于全量化训练。我们使用 NeMo PEFT 方法,展示了如何将 LLM 适应下游任务,如金融情绪预测。
欲了解更多信息,请参阅 使用 NeMo 的参数高效微调 (PEFT)。
SFT 和 PEFT
我们还演示了 SFT 和 PEFT,以及SFT 训练器如何提升游戏玩家的游戏体验,并通过HuggingFace实现。此外,PEFT 库提供了更多相关信息。欲了解详情,请参阅使用 Hugging Face 的联邦 LLM SFT 和 PEFT。
我们的实验展示了如何利用Llama-2-7b-hf 模型,通过 FLARE 框架实现对 HuggingFace 模型的训练和调整,从而实现联邦 SFT 和 PEFT 的功能。
在本示例中,FLARE 网络上的 SFT 模型大小约为 27 GB,而 PEFT 模型大小约为 134 MB。大型模型会自动流式传输,无需手动调用流式传输 API。
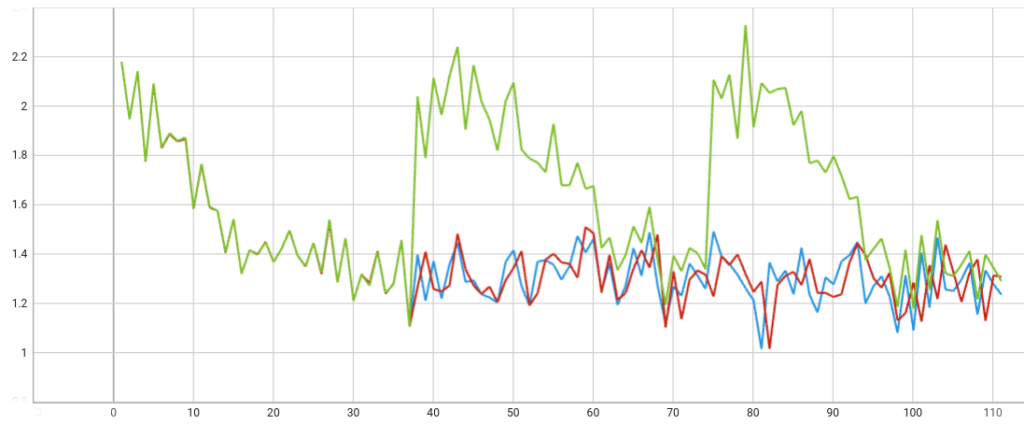
为确保 FLARE 与 HuggingFace 的训练器的正确行为,我们在三种设置下执行了单客户端实验 (图 4):
- 三次训练 (红色) 的本地训练
- 使用 FLARE 进行三轮联合训练 (蓝色),每轮一次训练
- 使用 FLARE 进行三轮联邦学习,但每轮都会返回一个固定的全局模型 (绿色)
正如预期的那样,随着一些训练随机性,两个 PEFT 训练损失曲线保持一致。
由于 HuggingFace 训练器会追踪模型的训练状态,因此我们希望确保服务器上的全局模型正确加载,而不是重新使用本地记录)。如图所示,正确的固定全局模型已正确加载。每轮训练从相同的起点开始,这表明了预期的联邦学习行为。
扩展联邦学习工作流模式
一些研究人员更倾向于使用替代工作流模式,而不是前面描述的 FL 工作流。例如,群体学习 被认为是 FL 的分布式点对点协作学习模式的替代方案。同样,分割学习 和谈资学习 是 FL 的替代通信模式。
除此之外,以下是这些不同的通信模式之间的一些关键差异:
- 强调去中心化和点对点通信。
- 无用于模型聚合的静态服务器。
- 客户端通信是对等通信。
- 算法工作流程不同:
- 聚合器选择
- 客户端采样和分配 (广播到所有的 gossip 协议)
当您进一步查看时,“没有中央服务器”实际上意味着“没有静态聚合节点”。在大多数情况下,聚合节点位于 FL 服务器节点。
在许多 FL 框架中,服务器执行两种功能:
- 管理作业生命周期 (客户端站点的运行状况和作业状态监控)。
- 作为参与训练过程 (任务分配、模型初始化、聚合和获取分布式最终模型) 的聚合器。
通过在 FLARE 中分离这两个功能并启用直接点对点通信,工作流模式可以支持蜂群学习和谈资。
聚合器函数不一定位于 FL 服务器。您可以将其放入任何客户端节点。这基本上实现了聚合的去中心化。您只需使用 FL 服务器进行作业生命周期管理。
在 2.4.0 版本中,我们引入了客户端控制的工作流程,并启用了此功能。
安全消息
点对点客户端使用 TLS 加密进行消息交换,发件人使用从证书中接收到的接收者公钥加密消息,只有发件人和客户端才能查看消息。
如果客户端与消息没有直接连接,且消息通过服务器转发,则服务器无法解密消息。
以下是常用的客户端控制的工作流程类型:
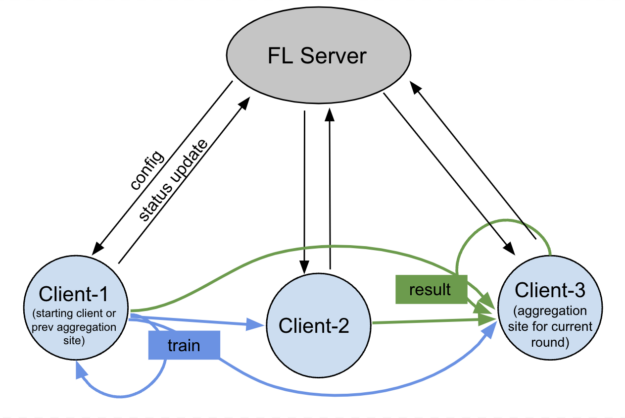
在图 5 中,FL 服务器启动训练作业,并监控整个作业生命周期。通信在客户端之间以点对点方式进行,FL 服务器不参与。
有些人希望将区块链网络用作蜂群学习的通信层,但这并不是蜂群学习的要求。关键在于,如果通过 FL 服务器路由消息,则必须确保聚合器无法解码消息。
联邦收益正在改变多个行业领域
FL 的采用速度加快,改变了医疗健康和 BFSI 等多个行业领域。
医疗健康
在医疗健康领域,FL 被用于医学影像分析,以预测临床结果,并且还有许多其他应用。
NVIDIA Omniverse 平台的 FLIP 项目,由英国 AI 中心的价值基础医疗健康项目负责人伦敦国王学院领导,并得到 FLARE 的支持。该项目计划在2023年初在至少5家NHS医疗机构中部署。首批应用包括利用AI通过头部CT扫描诊断中风、帮助识别和诊断前列腺癌的算法,以及缩短心脏MRI扫描时间的软件。
Rhino Health 是一家专注于联邦计算的公司,由 FLARE 提供支持,致力于推动联邦计算的性能变革。欲了解更多信息,请访问 适用于医疗健康 AI 的联邦学习: NVIDIA 和 Rhino Health 加速研究协作(视频链接)。
罗氏(Roche)是一家专注于推进医学科学发展以改善人们生活的领先制药和诊断公司。该公司认识到了联邦学习的强大功能,并一直在与 NVIDIA 合作,改进联邦学习的各个方面。有关更多信息,请访问 使用 NVIDIA FLARE 通过联邦学习防止医疗健康数据泄露。
西门子医疗是一家领先的医疗技术公司,专注于提供医学影像、实验室诊断和体外诊断的先进解决方案。该公司使用 FLARE 和 Azure ML。
银行、金融服务和保险
随着各国和地区开发新的 AI 战略,FL 已成为必需品。
在 BFSI 中,关键应用程序包括欺诈检测。该模型基于来自不同银行或机构的各种客户档案和信用历史的见解而共同构建,而且不需要交换原始数据。对于遵守严格隐私法律或法规的机构而言,这一挑战尤为明显。
根据最新发布的金融服务业 AI 现状:2024 年趋势,欺诈检测是投资领域的热门 AI 用例之一,也是金融服务组织面临的重大安全挑战之一(见图 6)。


欺诈检测是金融服务领域的重要应用程序之一。有超过一半的受访者 (51%) 认为 AI 技术可以有效打击欺诈,因此将 FL 与零信任机密计算集成成为了解决这些挑战并提供可靠解决方案的关键方法。
在 NVFlare 2.4.0 中,我们开发了几个示例,展示了如何使用 FL:
总结
FL 正在快速发展 .FLARE 开发了一套功能套件,可帮助公司采用这项新技术。您可以在本帖子中找到比我们在本帖子中讨论的更多功能。
NVIDIA Omniverse 平台新增了 FLARE 功能,以及之前提到的:
- 为 MLFlow 和 Weights&Biases 提供实验追踪支持
- 安全增强功能,支持站点特定的自定义身份验证和授权
- 多格式配置
- 第三方集成模式
- 作业 CLI 和作业模板
- POC 命令升级
- 分步系列示例
NVIDIA 让您更轻松地将现有的 ML/DL 转换为 FL,增强 LLM 训练,并扩展工作流模式。
有关更多信息,请参阅以下资源: