
随着人工智能和模拟的融合加速了科学发现,需要一种方法来衡量和排名构建世界超级计算机人工智能模型的速度和吞吐量。 MLPerfHPC 现在已经进入第三次迭代,它已经成为使用传统上在超级计算机上执行的工作负载来衡量系统性能的行业标准。
同行评审的行业标准基准是评估 HPC 平台的关键工具, NVIDIA 相信,获得可靠的性能数据将有助于指导未来 HPC 架构师的设计决策。 MLPerf 基准测试由 MLCommons 开发,使组织能够在传统上在超级计算机上执行的一组重要工作负载上评估 AI 基础设施的性能。
MLPerfHPC 基准测试测量了三种采用机器学习技术的高性能仿真的训练时间和吞吐量。
这篇文章介绍了 NVIDIA MLPerf 团队为优化每个基准和度量以获得最佳性能所采取的步骤。除了 MLPerf HPC v1.0 中的优化之外,我们还将重点关注 MLPerfHPC v2.0 中的优化。
CosmoFlow
CosmoFlow 训练应用程序基准测试的每个实例加载约 8 TB 的训练数据和约 1 TB 的验证数据。这些包括 512K 个训练样本和 64K 个验证样本。每个示例都有一个 16 MB 的数据文件和一个 144 个字符的小标签文件。总共有 100 多万个小文件需要在培训开始之前加载到节点本地非易失性内存快车( NVMe )中。
在 MLPerf HPC v1.0 中,这导致数据分级对于强规模和弱规模的情况都需要大量时间。对于弱规模的情况,每个实例从文件系统加载超过 100 万个文件会给共享磁盘系统带来额外的压力。
对于用于弱规模提交的实例数量,这会导致相对于实例数量的分段性能的非线性降级。这些问题以多种方式解决,概述如下。
NVMe 上的数据暂存
对于 NVIDIA MLPerf HPC v1.0 提交的单个强训练实例分析表明,仅使用了 Selene Lustre 文件系统最大理论读取带宽的一小部分。转移输入数据集时,节点上的存储网络接口卡( NIC )也是如此。
在培训的阶段阶段,分配的 CPU 资源完全用于从共享文件系统向节点本地 NVMe 存储源数据。增加专用于分段的线程,并并行分段训练和验证数据,将分段时间减少了约 75% 。这相当于分段的速度提高了约 4 倍,并使端到端的总时间减少了 40% ,从而实现了强大的规模。
数据压缩
加载许多小文件本质上是低效的。在 CosmoFlow 中,有超过 100 万个文件,每个文件有 144 个字节。为了进一步提高暂存性能,将关联的数据和标签提前脱机合并到一个压缩文件中。
与从磁盘转移数据并行,文件将在本地解压缩到计算节点磁盘上。这将从磁盘读取的文件数量减少了 50% ,从磁盘传输的总数据减少了约 85% ,最终为强规模场景提供了额外的 13% 的暂存速度。这将使大规模提交的总体培训时间提高 7% 。
这种方法实现了超过 900 GB / s 的读取带宽,用于大规模场景的数据分段。
在运行多个实例时增加有效带宽
有关其他算法详细信息,请参阅 2021 MLPerf HPC 提交文件 MLPerf HPC v1.0: Deep Dive into Optimizations Leading to Record-Setting NVIDIA Performance 中的 DeepCam 解释。
当同时运行多个实例时,对于弱伸缩性,每个实例必须在其本地节点上存储训练和验证数据的副本。今年, NVIDIA 提交的文件为 CosmoFlow 实施了分布式分级机制。
所有节点,无论与哪个实例关联,都会从共享文件系统加载一部分总数据( 1 / N ,其中 N 是节点总数,在本例中为 512 )。考虑到已经讨论过的优化,这只需要几秒钟。
然后,每个节点使用MPI_Allgather将从远程存储加载的数据分发给需要数据的其他节点。这种分布发生在较高带宽上 InfiniBand Fabric 。换句话说,通过此优化,以前通过存储网络进行的大部分数据传输被卸载到 InfiniBand Fabric 。由于分布了分段,对于弱规模场景,分段时间随实例数量(至少多达 128 个实例)线性扩展。
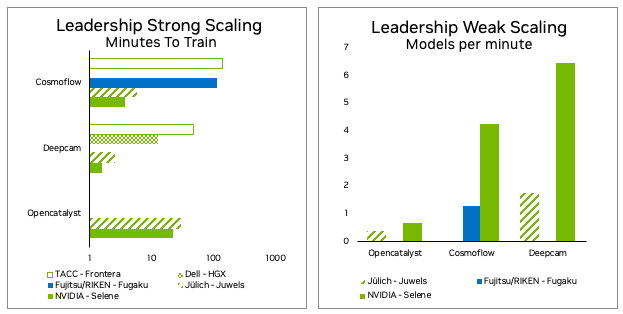
对于 1.0 版的提交,运行了 32 个实例,每个实例的数据量约为 9 TB 。这需要 10.76 分钟才能获得约 460 GB / s 的有效带宽。
在今年的提交中,运行了 128 个实例,每个实例的数据量约为 9 TB ,总的数据量需要 6.7 分钟。这意味着在 1.6 倍的时间内将输入数据分段为 4 倍的实例数,从而产生约 2900 GB / s 的有效带宽,有效带宽增加 6.5 倍。有效带宽假设从文件系统转移的总数据量与给定数量实例的非分布式算法相同。
较小的实例大小用于弱规模训练
所有的分段改进都使单个实例的大小得以减小,从而实现了弱扩展(因此并行实例的数量更大),而在实施优化之前存在的存储访问瓶颈是不可能实现的。在 v1.0 中, 32 个实例(每个实例有 128 个 GPU )导致了分段时间的非线性扩展。实例数量的增加导致了转移时间的超线性增加。
如果没有对许多实例进行有效分段的改进,分段时间将继续随着实例的数量呈超线性增长,导致数据分段所花费的时间比实际训练的时间更长。
通过上述优化,弱规模提交的实例数量从 32 个增加到 128 个,每个实例使用四个节点,而不是 MLPerf HPC v1.0 中的 16 个节点。在 v2.0 中,分段在更短的时间内完成,同时将弱规模提交同时运行的模型数量增加了 4 倍。
CUDA 图形和图形捕获
CUDA 图允许启动由一系列内核组成的单个图,而不是从 CPU 向 GPU 单独启动每个内核。该特性最大限度地减少了 CPU 在每次迭代中的参与,通过最小化延迟(尤其是对于强缩放场景)显著提高了性能。
CUDA 图形支持最近添加到 PyTorch 中。有关详细信息,请参见 Accelerating PyTorch with CUDA Graphs 。 PyTorch 中的 CUDA 图形支持导致 CosmoFlow 在强缩放场景中的端到端性能提高约 15% ,这对延迟和抖动最为敏感。
OpenCatalyst
GPU 负载平衡
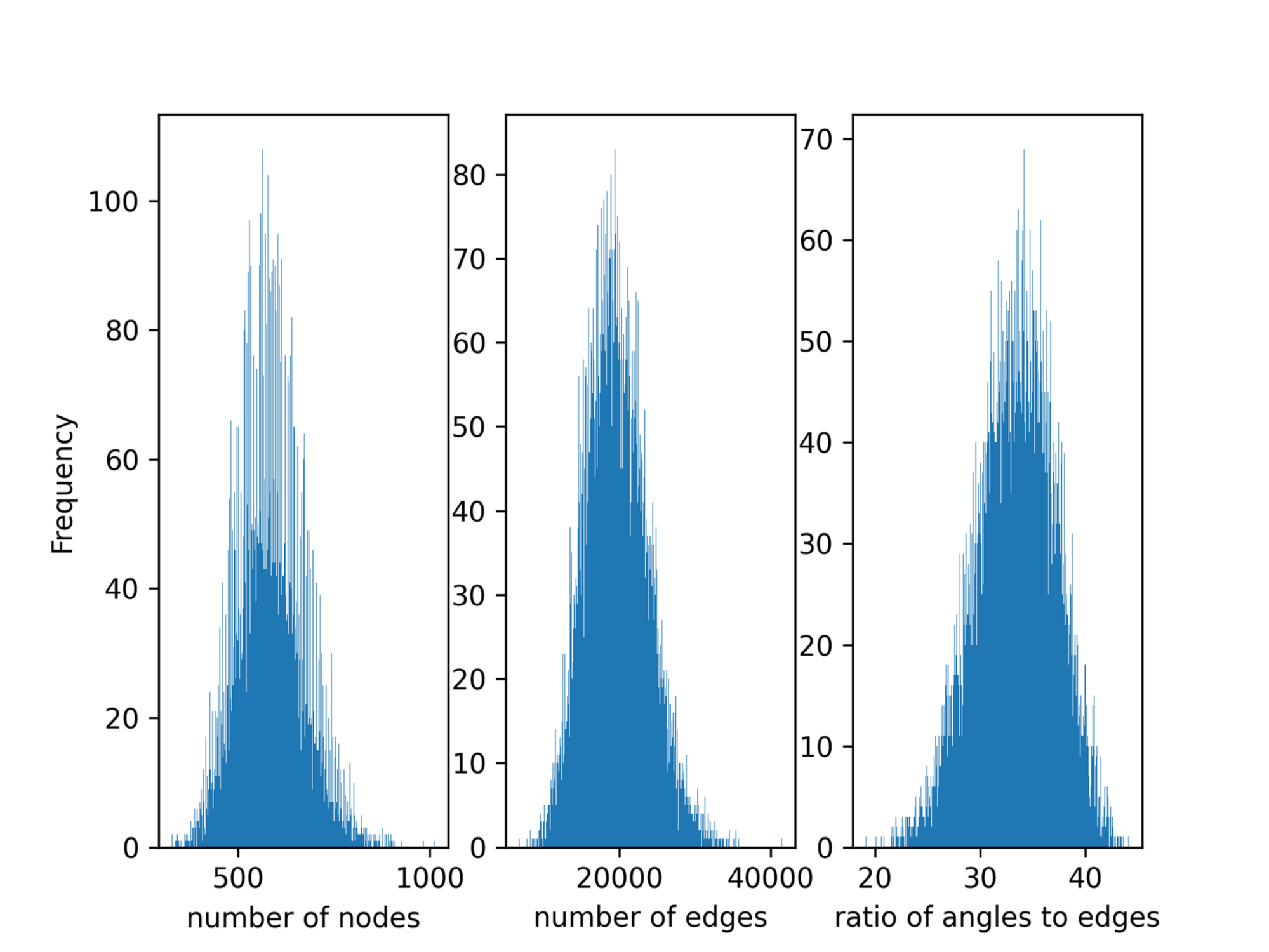
数据并行在每个 GPU 之间平均分割全局批处理。然而,默认情况下,数据并行任务分区不考虑批处理中的负载不平衡。由于不同分子的原子数、边缘数和从分子中获得的图中的三重态有很大差异(图 2 ),因此一批样品之间的 Open Catalyst 中存在负载不平衡。
这种不平衡导致多 GPU 设置中的大同步开销。对于强缩放场景,这导致 32% 的计算时间被浪费。劳伦斯伯克利国家实验室( LBNL )在 MLPerf HPC v1.0 中引入了一种算法来平衡 GPU 上的负载,这在本轮 NVIDIA 提交的文件中被采用。
该算法首先对训练数据进行预处理,以获得每个样本的边缘数。在采样阶段,给每个 GPU 局部样本的索引,并执行全局ALLgather以获得全局样本的索引。
然后,全局样本按照边的数量进行排序,并分布在工人之间,以便每个 GPU 处理尽可能接近相等数量的边。该算法很好地平衡了工作负载,但引入了很大的通信开销,特别是当应用程序扩展到更多时 GPU 。这与 LBNL 在 v1.0 中提交的 Open Catalyst 中使用的算法相同。
NVIDIA 还改进了 v2.0 中的采样功能。负载平衡采样器通过在开始时获取全局批处理中所有样本的索引,避免了全局( GPU 间)通信。如前所述,样本按边数排序,并划分为不同的桶,以便每个桶具有相同的近似边数。最后,每个工作人员都会得到一个包含与其全局排名相对应的样本索引的桶。
使用 nvFuser 和 cuGraph 操作的内核融合
从 MLCommons GitHub 下载的原始 OpenCatalyst 模型中有超过 10K 个内核。 PyTorch 的深度学习编译器 nvFuser 是一种常见的优化方法,它使用实时( JIT )编译将多个操作融合到一个内核中。该方法减少了内核数量和全局内存事务。
为了实现这一点, NVIDIA 修改了模型脚本,以在 PyTorch 中启用 JIT 。优化的融合内核也在cuGraph-ops中实现,通过 RAPIDS framework 暴露。借助nvFuser和cuGraph-ops,内核总数可以减少 90% 以上。
融合小型 GEMM 以提高 GPU 利用率
在原始计算图中,有许多小的通用矩阵乘法( GEMM ),它们是顺序执行的,不能使 GPU 饱和。这些小的 GEMM 操作可以被融合以减少内核的数量并提高 GPU 的利用率。应用了三种 GEMM 融合——填充、配料和水平融合——如下所述。为了实现这些融合,对模型脚本进行了唯一的更改。
Packing – 多个线性层共享相同的输入。一个大型 GEM 被用来替换一组小型 GEM 。

Batching – 几个线性层彼此没有依赖性。这些线性层被捆绑到批处理操作中,以提高并行度。
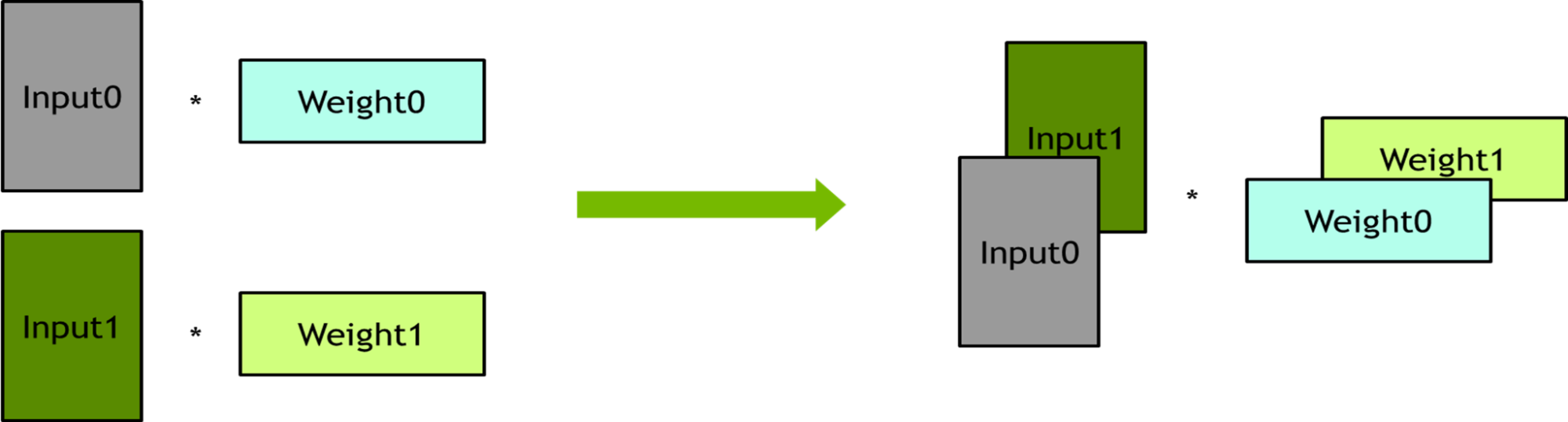
Horizontal fusion –
输出减少的公式可以表示为w1 x 01 + w2 x 02 + w3 x 03 + w4 x 04 + w5 x 05,正好匹配矩阵的分块乘法,可以将它们打包在一起。

消除三元组上的冗余计算
在原始计算图中,每个边缘特征被扩展为三元组,然后每个三元组执行元素乘法。三元组的数量大约是边数的 30 倍,这会导致大量的冗余计算。为了去除多余的计算,首先对边缘特征执行元素乘法,然后将其扩展为执行三元组的边缘特征。
管道优化
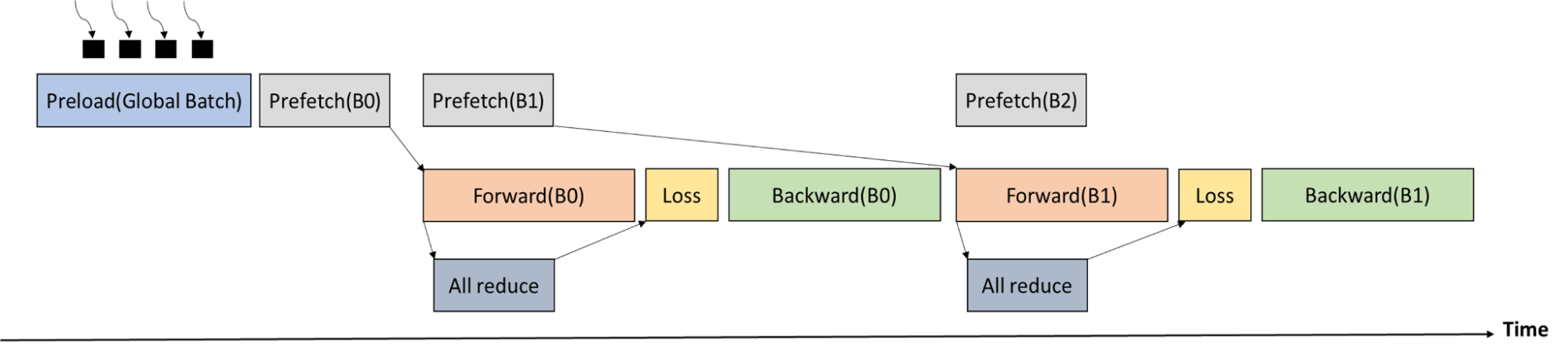
在丢失阶段之前,需要在所有工作人员之间进行ALLReduce通信,以获得当前全局批次中的原子总数。由于前向传递的执行时间比ALLReduce的执行时间长,因此可以很好地重叠通信。
图 6 显示了培训过程时间表。全局批处理首先由多个进程加载到 CPU 内存中。Memcpy从 CPU 存储器到 GPU 存储器和ALLReduce(以获得全局批中的原子数)与前向传递重叠。
数据暂存
Open Catalyst 基准测试的训练数据为 300 GB ,一个 DGXA100 节点的系统内存为 2048 GB 和 256 个线程(每个套接字 128 个线程,每个节点两个套接字)。结果,可以在开始时将整个训练数据预加载到 CPU 存储器中。无需在每个训练步骤中将迷你批次从磁盘加载到 CPU 内存。
为了加速数据预加载, NVIDIA 启动了 256 个进程,每个进程加载 300 / 256 (~ 1.2 ) GB 的训练数据集。完成预加载大约需要 10s ~ 15s ,相对于端到端训练时间而言,这是微不足道的。
深度摄像头
正在加载数据
以前,透明内存数据加载器利用后台进程将数据本地缓存在动态随机存取存储器( DRAM )中。这会导致较大的开销,因此重新实现了加载程序以使用线程。
性能先前受到 Python 全局解释器锁( GIL )的限制。这次,基于 C ++的 IO 助手类被优化以释放 GIL 。这种方法允许背景加载与其他 CPU 工作重叠。同样的优化也应用于分布式数据分级器,以降低扩展分数,将端到端性能提高约 15% 。
完整迭代 CUDA 图捕获
与 MLPerf HPC v1.0 相比, CUDA 图捕获的范围扩展到了完全迭代、正向和反向传递、优化器和学习速率调度器步骤。为此, NVIDIA APEX 包中的无同步优化器 FusedMixedPrecisionLAMB 和 DistributedLAMB 用于弱和强缩放基准。
此外,所有 DeepCAM 学习速率调度器都被移植到 GPU 。通过增加 CUDA 图内执行的计算部分,减少了 CPU 执行可变性引起的设备之间的性能可变性。因此,横向扩展性能提高。
分布式优化器
为了提高强大的扩展性能,使用了 DistributedLAMB 优化器。该优化器特别适合于小的每 GPU 局部批量大小和大的规模,因为优化器成本在这种设置中更为显著。 DeepCAM 的端到端性能增量约为 3% 。
cuDNN 内核优化
DeepCAM 具有大量具有不同性能特征的计算内核。虽然 NVIDIA 在 v1.0 中改进了分组卷积的性能,但在 v2.0 中也改进了逐点卷积的性能。它们与分组卷积一起使用,以形成深度方向的可分离卷积。
MLPerf HPC v2.0 最终结果
人工智能正在改变高性能计算的科学方式。每年,都会建立新的、更精确的替代模型,并以足够的准确度大大超过基于物理的模拟。蛋白质折叠和 OpenFold 、 RoseTTAFold 和 AlphaFold 2 的出现已经被这种基于 AI 的方法彻底改变,使基于蛋白质结构的药物发现触手可及。
MLPerfHPC 反映了超级计算行业需要一种客观的、同行评审的方法来衡量和比较与 HPC 相关的用例的 AI 训练性能。
自 2021 MLPerf HPC v1.0 提交以来, NVIDIA 已经取得了重大进展。 Selene 超级计算机显示, NVIDI A A100 Tensor Core GPU 和 NVIDIA DGX-A100 SuperPOD 虽然已使用近三年,但仍然是 HPC 用例及以后 AI 培训的最佳系统。
有关详细信息,请参见 MLPerf HPC Benchmarks Show the Power of HPC+AI 。




