为了将像素转换为可操作的洞察力,计算机视觉依赖于 深度学习 来提供对环境的理解。目标检测是一种常用的技术来识别帧中的单个对象,例如识别人或汽车。虽然对象检测对于某些应用程序是有益的,但是当您希望在像素级理解对象时,它就不够了。
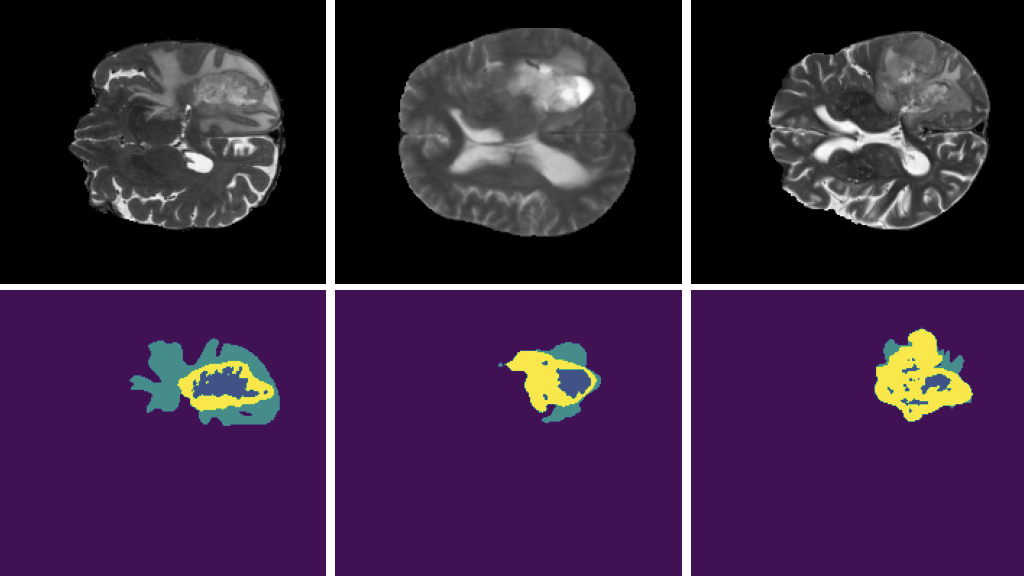
实例分割是一种流行的计算机视觉技术,它有助于在像素级识别帧中多个对象的每个实例。除了边界框之外,实例分段还创建了一个细粒度的分段掩码。分割有助于在对象和背景之间进行描绘,例如在 AI 驱动的绿色屏幕中,您希望模糊或更改帧的背景,或者分割帧中的道路或天空。或者你可能想在显微镜下找出制造缺陷或细胞核分割。图 1 显示了对检测到的对象进行分段掩码的示例。

转移学习是训练专门的深层神经网络( DNN )模型的常用方法。 NVIDIA 转移学习工具包 ( TLT )使转移学习变得更加容易,这是一个零编码框架,用于训练精确和优化的 DNN 模型。随着 tlt2 . 0 的发布, NVIDIA 使用 面具 R-CNN 增加了对实例分段的训练支持。你可以训练面具 R-CNN 模型使用几个 ResNet 主干之一。 NGC 中提供了为 ResNet10 / 18 / 50 / 101 训练的预训练权重,可以作为迁移学习的起点。
在这篇文章中,我将向您展示如何使用 TLT 训练一个 90 级 COCO Mask R-CNN 模型,并使用 TensorRT 将其部署到 NVIDIA DeepStream SDK 上。您将学习如何访问和使用来自 NGC 的预训练模型,以最小的工作量训练 Mask R-CNN 模型,并将其部署到 GPU 上进行推理。这些步骤可用于构建任何自定义掩码 R-CNN 模型。
Mask R-CNN 与 DeepStream SDK 本机集成, DeepStream SDK 是一个用于构建智能视频分析应用程序的流分析工具包。有关 Mask R-CNN 如何与 DeepStream 集成的更多信息,请参阅 使用 NVIDIA DeepStream 5 . 0 构建智能视频分析应用程序(已为 GA 更新) 。
用 COCO 训练面具 R-CNN 模型
Mask R-CNN 是 2017 年推出的两阶段目标检测和分割模型。由于其模块化设计,它是一个优秀的体系结构,适用于各种应用。在本节中,我将引导您通过可复制的步骤从 NGC 和一个开源 COCO 数据集获取预训练的模型,然后使用 TLT 训练和评估模型。
要开始,请设置一个 NVIDIA NGC 帐户,然后拉出 TLT 容器:
docker pull nvcr.io/nvidia/tlt-streamanalytics:v2.0_py3
接下来,下载经过预训练的模型。使用 NGC 命令列出可用型号:
ngc registry model list nvidia/tlt_instance_segmentation:*
要下载所需的模型,请使用以下命令。在这篇文章中,我使用了 ResNet50 主干网,但是您可以自由使用任何受支持的主干网。
ngc registry model download-version nvidia/tlt_instance_segmentation:resnet50 --dest $model_path
整个工作流包括以下步骤:
- 准备数据。
- 正在配置规范文件。
- 训练模特。
- 验证模型。
- 导出模型。
- 使用 DeepStream 部署。
准备数据
maskr-CNN 希望有一个 COCO 格式的用于培训、验证和注释的图像目录。 TFRecords 用于管理数据并帮助加快迭代速度。为了下载 COCO 数据集并将其转换为 TFRecords , TLT 容器中的 Mask R-CNN iPython 笔记本提供了一个名为 download_and_preprocess_coco.sh 的脚本。如果使用的是自定义数据集,则必须先将注释转换为 COCO ,然后再将其与 TLT 一起使用。有关更多信息,请参见 COCO data format。
下载 COCO 数据集并转换为 TFRecords :
bash download_and_preprocess_coco.sh $DATA_DIR
这将下载原始 COCO17 数据集并将其转换为$ DATA \ u DIR 中的 TFRecords 。
配置等级库文件
下一步是为培训配置 spec 文件。实验规范文件是必不可少的,因为它编译了实现一个好模型所需的所有超参数。 Mask R-CNN 规范文件有三个主要组件:顶层实验配置、 data_config 和 maskrcnn_config 。 spec 文件的格式是 protobuf text ( prototxt )消息,其每个字段可以是基本数据类型,也可以是嵌套消息。
顶层实验配置包括实验的基本参数,如学习速率、迭代次数、是否使用混合精度训练等。每个 num_steps_per_eval 值保存一个加密的检查点,然后对验证集运行求值。
此处为 8- GPU 培训作业设置 init_learning_rate 值。如果使用不同数量的 GPUs ,请按照线性缩放规则调整学习速率。
use_amp: False warmup_steps: 1000 checkpoint: "$PRETRAINED_MODEL_PATH" learning_rate_steps: "[60000, 80000, 90000]" learning_rate_decay_levels: "[0.1, 0.01, 0.001]" total_steps: 100000 train_batch_size: 3 eval_batch_size: 8 num_steps_per_eval: 10000 momentum: 0.9 l2_weight_decay: 0.00002 warmup_learning_rate: 0.0001 init_learning_rate: 0.02
data_config 值指定输入数据源和维度。 augment_input_data 仅在培训期间使用,建议用于实现更高的精度。 num_classes 值是基本真理中的类别数加上背景类的 1 。输入图像将调整大小并填充到 image_size ,同时保持纵横比。
data_config{
image_size: "(832, 1344)"
augment_input_data: True
eval_samples: 5000
training_file_pattern: "
$DATA_DIR/train*.tfrecord"
validation_file_pattern: "$DATA_DIR/val*.tfrecord"
val_json_file: "$DATA_DIR/annotations/instances_val2017.json"
num_classes: 91
skip_crowd_during_training: True
}
maskrcnn_config 值指定模型结构和损失函数相关的超参数。目前, Mask R-CNN 支持 TLT 中的所有 ResNet 主干。在这个实验中,您选择 ResNet50 作为主干,它的前两个卷积块被冻结,所有批处理规范化( BN )层都被冻结,正如 freeze_bn: True 和 freeze_blocks: "[0,1]" 所指定的那样。在一个冻结的任务层,不要改变一个卷积层的权重。这在迁移学习中尤其有用,因为一般特征已经在浅层中捕获。您不仅可以重用所学的功能,还可以减少培训时间。有关每个字段的详细信息,请参阅 TLT 入门指南 。
maskrcnn_config {
nlayers: 50
arch: "resnet"
freeze_bn: True
freeze_blocks: "[0,1]"
gt_mask_size: 112
# Region Proposal Network
rpn_positive_overlap: 0.7
rpn_negative_overlap: 0.3
rpn_batch_size_per_im: 256
rpn_fg_fraction: 0.5
rpn_min_size: 0.
# Proposal layer.
batch_size_per_im: 512
fg_fraction: 0.25
fg_thresh: 0.5
bg_thresh_hi: 0.5
bg_thresh_lo: 0.
# Faster-RCNN heads.
fast_rcnn_mlp_head_dim: 1024
bbox_reg_weights: "(10., 10., 5., 5.)"
# Mask-RCNN heads.
include_mask: True
mrcnn_resolution: 28
# training
train_rpn_pre_nms_topn: 2000
train_rpn_post_nms_topn: 1000
train_rpn_nms_threshold: 0.7
# evaluation
test_detections_per_image: 100
test_nms: 0.5
test_rpn_pre_nms_topn: 1000
test_rpn_post_nms_topn: 1000
test_rpn_nms_thresh: 0.7
# model architecture
min_level: 2
max_level: 6
num_scales: 1
aspect_ratios: "[(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)]"
anchor_scale: 8
# localization loss
rpn_box_loss_weight: 1.0
fast_rcnn_box_loss_weight: 1.0
mrcnn_weight_loss_mask: 1.0
}
训练模型
数据和等级库文件准备就绪后,可以使用以下命令开始培训:
tlt-train mask_rcnn -e $spec_file_path -r $experiment_dir -k $KEY --gpus N
使用更多 GPUs 进行培训可以让网络更快地接收更多数据,从而在开发过程中为您节省宝贵的时间。 TLT 支持 multi- GPU 训练,这样您就可以用多个 GPUs 并行训练模型。如果 自动混合精度 ( AMP )通过将 enable_amp 设置为 True 启用训练,与 F32 训练相比,您可以预期速度提升 20 – 50% 。在训练期间,一个详细的日志记录每五次迭代的训练损失和验证集上的评估指标。
throughput: 34.4 samples/sec ==================== Metrics ===================== FastRCNN box loss: 0.27979 FastRCNN class loss: 0.11633 FastRCNN total loss: 0.39612 L2 loss: 0.83087 Learning rate: 0.00014 Mask loss: 1.3277 RPN box loss: 0.03868 RPN score loss: 0.60576 RPN total loss: 0.64443 Total loss: 3.19912
如果由于任何原因,培训过程中断,您可以通过执行相同的命令来恢复培训。它会自动从上次保存的检查点提取。
评估模型
要评估模型,请使用以下命令:
tlt-evaluate mask_rcnn -e $spec_file_path -m $model_path -k $KEY
面具 R-CNN 报道可可的 检测评估指标 。例如, AP50 表示 IoU 设置为 50% 时的平均精度( AP )。
所有的检测框架都使用 mAP 作为一个共享的度量,采用了 Pascal VOC ,与 AP50 相当。该分类模型支持各种度量,包括 Top K 准确度、精确度和召回率以及混淆矩阵。
使用 8 GPUs 训练 100K 次迭代后,您可以观察到以下指标:
=========== Metrics =========== AP: 0.334154785 AP50: 0.539312243 AP75: 0.358969182 APl: 0.453923374 APm: 0.354732722 APs: 0.181649670 ARl: 0.661920488 ARm: 0.533207536 ARmax1: 0.297426522 ARmax10: 0.477609098 ARmax100: 0.503548384 ARs: 0.317135185 mask_AP: 0.307278961 mask_AP50: 0.505144179 mask_AP75: 0.325496018 mask_APl: 0.432014465 mask_APm: 0.327025950 mask_APs: 0.151430994 mask_ARl: 0.626315355 mask_ARm: 0.492682129 mask_ARmax1: 0.281772077 mask_ARmax10: 0.439913362 mask_ARmax100: 0.461205393 mask_ARs: 0.271702766
KPI 是通过对 NGC 的预训练模型进行微调获得的, NGC 最初是在开放图像数据集的子集上进行训练的。如果使用 ImageNet 预训练权重进行训练,或者使用更大的迭代次数进行训练,则 KPI MIG 将有所不同。
验证模型
现在您已经训练了模型,运行推断并验证预测。要用 TLT 直观地验证模型,请使用 tlt-infer 命令。 tlt-infer 命令支持对. tlt 模型和 TensorRT 引擎的推理。 tlt-infer 生成带有边框的带注释图像。或者,您还可以可视化分段掩码或以 cocojson 格式序列化输出元数据。例如,要使用. tlt 文件运行推理,请运行以下命令:
tlt-infer mask_rcnn -i $input_images_dir -o $annotated_images_dir -e $spec_file -m $tlt_model -l $json_label -t $threshold --include_mask
图 2 所示的原始图像与图 3 中所示的带注释图像进行了比较。如您所见,该模型对与 COCO 训练数据不同的图像是鲁棒的。


导出模型
推断吞吐量和创建有效模型的速度是部署 深度学习 应用程序的两个关键指标,因为它们直接影响上市时间和部署成本。 TLT 包括一个 tlt-export 命令,用于导出和准备 TLT 模型以进行部署。 tlt-export 命令可以选择性地生成校准缓存,以便以 INT8 精度运行推断。有关详细信息,请参见 用 NVIDIA TensorRT 部署深度神经网络 。
模型导出为. etlt (加密的 TLT )文件。文件可由 DeepStream 软件开发工具包 使用,它解密模型并将其转换为 TensorRT 引擎。导出模型将训练过程与推理分离,并允许转换到 TLT 环境外的 TensorRT 引擎。 TensorRT 引擎特定于每个硬件配置,应该为每个唯一的推理环境生成。
例如,要在 INT8 中导出模型,请使用以下命令:
tlt-export mask_rcnn -m $model_path -o $int8_etlt_file -e $spec_file -k $KEY --cal_image_dir $calibration_image_dir --batch_size N --batches $num_cal_batches --cal_cache_file $calibration_table --cal_data_file $calibration_data_cache --data_type int8
这将生成一个 INT8 校准表和. etlt 文件。要将模型量化为 INT8 ,必须提供一个要在其上进行校准的数据集,该数据集由 --cal_image_dir 和 --cal_data_file 参数提供。这些参数指定校准所需的图像目录和 tensorfile 。 tensorfile 中的批处理数是从 batches 和 batch_size 值获得的。确保 --cal_image_dir 中提到的目录中至少有 (batch_size * batches) 个映像。
使用 DeepStream 部署
在 DeepStream 中集成 Mask R-CNN 模型很简单,因为 DeepStream 5 . 0 默认支持实例分段网络。 SDK 中提供了模型的配置文件和标签文件。这些文件可以用于生成的模型以及您自己的训练模型。在 GitHub 中提供了一个在一个类数据集上训练的样本掩码 R-CNN 模型。默认情况下,配置和标签文件应该适用于该模型。对于您在这篇文章中培训的模型,需要进行一些小的修改。
从 正在下载 和 installing 启动 DeepStream SDK 。自述文件中提供了使用 DeepStream 运行 TLT 模型的说明:
/opt/nvidia/deepstream/deepstream-5.0/samples/configs/tlt_pretrained_models
下面是运行 Mask R-CNN 模型的关键配置文件:
/opt/nvidia/deepstream/deepstream-5.0/samples/configs/tlt_pretrained_models/deepstream_app_source1_mrcnn.txt /opt/nvidia/deepstream/deepstream-5.0/samples/configs/tlt_pretrained_models/config_infer_primary_mrcnn.txt
/deepstream_app_source1_mrcnn.txt 文件是 deepstream 应用程序使用的主要配置文件。此文件配置整个视频分析管道的参数。有关详细信息,请参见 引用应用程序配置 。有关 DeepStream 中 Mask R-CNN 推理管道的更多信息,请参见 使用 NVIDIA DeepStream 5 . 0 构建智能视频分析应用程序(已为 GA 更新) 。
/config_infer_primary_mrcnn.txt 文件是一个推理配置文件,用于设置掩码 R-CNN 推理的参数。此文件由主 deepstream_app_source1_mrcnn.txt 配置调用。以下是根据模型修改的关键参数:
tlt-model-key= tlt-encoded-model= labelfile-path= int8-calib-file= infer-dims= num-detected-classes=<# of classes if different than default>
下面是一个例子:
[property] gpu-id=0 net-scale-factor=0.017507 offsets=123.675;116.280;103.53 model-color-format=0 tlt-model-key= tlt-encoded-model= output-blob-names=generate_detections;mask_head/mask_fcn_logits/BiasAdd parse-bbox-instance-mask-func-name=NvDsInferParseCustomMrcnnTLT custom-lib-path=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_infercustomparser.so network-type=3 ## 3 is for instance segmentation network labelfile-path= int8-calib-file= infer-dims= num-detected-classes=<# of classes if different than default> uff-input-blob-name=Input batch-size=1 0=FP32, 1=INT8, 2=FP16 mode network-mode=2 interval=0 gie-unique-id=1 no cluster 0=Group Rectangles, 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering) MRCNN supports only cluster-mode=4; Clustering is done by the model itself cluster-mode=4 output-instance-mask=1
它在 SDK 中提供的剪辑上运行。要尝试自己的源代码,请在 /deepstream_app_source1_mrcnn.txt 中修改 [source0] 。
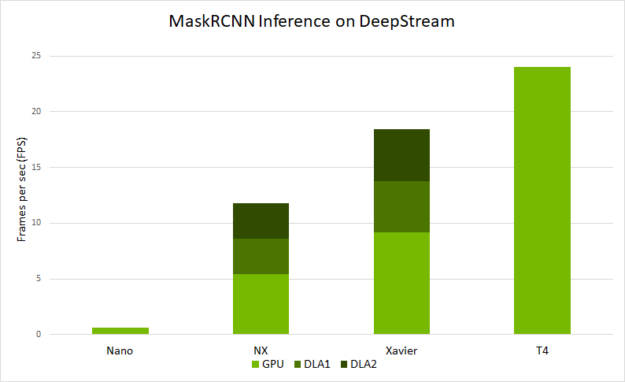
图 4 显示了在不同平台上使用 deepstream-app 可以预期的端到端性能。性能以 deepstream-app 处理的每秒帧数( FPS )来衡量。
- 推理分辨率为 1344 × 832
- 在 NVIDIA Jetson Nano 和 DLAs 上,它的批处理大小为 1 。
- 在 Jetson AGX Xavier 和 Xavier NX 上,运行的批处理大小为 2 。
- 在 T4 上,它以批大小 4 运行。
结论
在这篇文章中,您学习了如何使用 maskr-CNN 架构和 TLT 训练实例分割模型。这篇文章展示了使用 NGC 的一个预先训练过的模型的开源 COCO 数据集,使用 TLT 进行训练和优化,然后使用 deepstreamsdk 将模型部署到边缘。
您可以应用这些步骤来训练和部署您自己的自定义网络。训练可以在多个 GPUs 上进行,以并行运行并加快训练速度。也可以生成 INT8 校准文件,以 INT8 精度运行推断。以 INT8 精度运行可以提高边缘设备的推理性能。
有关更多信息,请参阅以下资源:
- 迁移学习工具包 和预训练车型
- DeepStream 软件开发工具包
- 使用 NVIDIA DeepStream 5 . 0 构建智能视频分析应用程序(已为 GA 更新) 项目
- TLT 开发者论坛 或 DeepStream 开发者论坛 用于提问或反馈
- Jetson 开发者社区项目 使用 TLT 和 DeepStream