MLCommons 开发的 MLPerf 基准是组织衡量其机器学习模型跨工作负载培训性能的关键评估工具。 MLPerf Training v2.1- 这个以 AI 培训为重点的基准套件的第七次迭代测试了广泛流行的 AI 用例的性能,包括以下:
- 图像分类
- 物体检测
- 医学影像学
- 语音识别
- 自然语言处理
- 正式建议
- 强化学习
许多人工智能应用程序利用流水线中部署的多个人工智能模型。这意味着,人工智能平台必须能够运行当今可用的所有模型,并提供支持新模型创新的性能和灵活性。
NVIDIA AI platform 在此轮中提交了所有工作负载的结果,它仍然是唯一一个提交了所有 MLPerf 培训工作负载结果的平台。
![Diagram shows a user asking their phone to identify the type of flower in an image and the many AI models that may be used to perform this identification task across several domains[SBE1] : audio, vision, recommendation, and TTS.](https://developer-blogs.nvidia.com/wp-content/uploads/2022/11/model-use-case.png)
NVIDIA Hopper 可大幅提升性能
在这一轮中, NVIDIA 使用新的 H100 Tensor Core GPU 提交了其首个 MLPerf 训练结果,与首次提交的 A100 Tensor Core GPU 相比,性能提高了 6.7 倍,与最新的 A100 结果相比,性能提升了 2.6 倍。
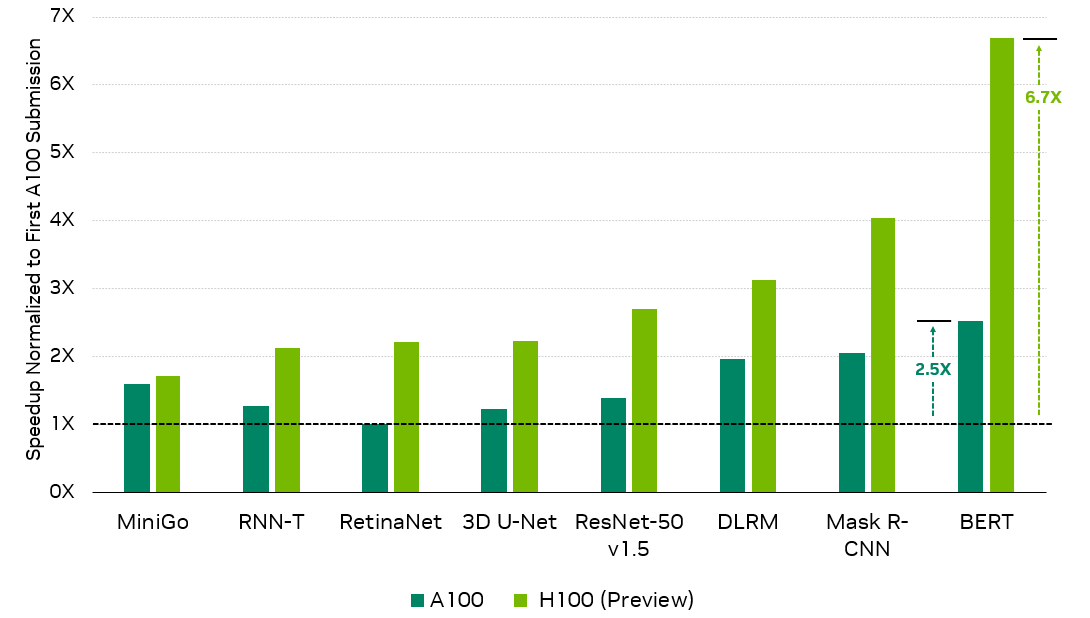
ResNet-50 v1.5 : 8x NVIDIA 0.7-18 , 8x NVIDIA 2.1-2060, 8x NVIDIA 2.1-2091 | BERT : 8x NVIDIA 0.7-19 , 8x NVVIDIA 2.1-2062, 8x NVIDIA 2.1-2091 | DLRM : 8x NVIDIA 0.7-17 , 8x NVID IA 2.1-2059, 8x NVIDIA 2.1-2091 |掩模 R-CNN : 8x NVVIDIA 0.7-19 , 8x NVID IA 2.1-2062, 8x NVIDIA 2.1-2091 | RetinaNet : 8x NVIDIA 2.0-2091 , 8x NVIDIA 2.1-2061, 8x NVIDIA 2.1-2091 | RNN-T : 8x NVVIDIA 1.0-1060 , 8x NVID IA 2.1-2061, 8x NVIDIA 2.1-2091 | Mini-Go : 8x NVVIDIA 0.7-20 , 8x NVID IA 2.1-2063, 8x NVIDIA 2.1-2091 | 3D U-Net : 8x NVIDIA 1.0-1059 , 8x NVID IA 2.1-2060, 8x NVIDIA 2.1-2091
第一个 NVIDIA A100 Tensor Core GPU 结果因 MLPerf Training 2.0 中引入的更高精度要求(如适用)而针对吞吐量标准化。
MLPerf 名称和徽标是商标。有关详细信息,请参阅 www.mlperf.org .
此外,在其第五次 MLPerf 培训中, A100 继续在全套工作负载中提供优异的性能,与首次提交相比,由于广泛的软件优化,性能提高了 2.5 倍。
这篇文章详细介绍了 NVIDIA 为实现这些结果所做的工作。
BERT
对于这一轮 MLPerf ,我们对 BERT 提交的文件进行了若干优化,包括使用 FP8 格式,对 FP8 操作进行优化,减少 CPU 开销,以及对小规模应用序列打包。
与 NVIDIA transformer 引擎集成
MLPerf Training v2.1 中 BERT 提交的 关键优化之一是使用 NVIDIA Transformer Engine library. 。该库在 NVIDIA GPU 上加速 transformer models ,并利用 NVIDIA Hopper 第四代 Tensor Core 支持的 FP8 数据格式。
BERT FP8 输入用于完全连接的层,以及在单个内核中实现多头注意力的融合多头注意力内核。与 FP16 格式相比,使用 FP8 格式可以减少存储器和流式多处理器( SM )之间传输的数据量,从而缩短存储器访问时间。
与 NVIDIA Hopper 架构上的 FP16 格式相比,将 FP8 格式用于矩阵乘法的输入还利用了 FP8 格式更高的计算速率 GPU 。通过利用 FP8 格式,与在相同硬件上不使用 transformer 引擎相比, transformer Engine 将端到端训练时间缩短了 37% 。
transformer 引擎从用户那里提取出 FP8 张量类型。因此,编码器层的输入和输出处的张量格式保持为 FP16 。 FP8 使用的详细信息由编码器层内的 transformer 引擎库处理。
FP8 采用 E4M3 和 E5M2 格式,在 transformer 引擎中称为混合配方。有关 FP8 格式和配方的更多信息,请参见 Using FP8 with Transformer Engine 。
FP8 通用矩阵乘法层
transformer 引擎库具有自定义的融合内核实现,以加速常用的 NLP 和数据转换操作。
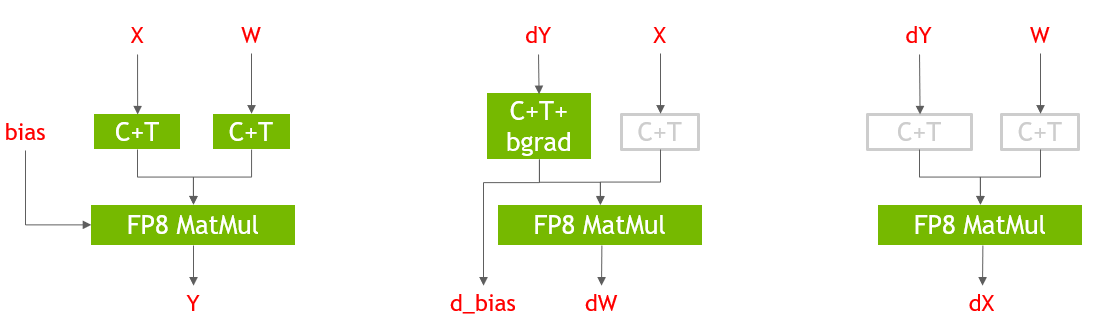
图 3 显示了 PyTorch 中 Linear 层的前向和后向传递的 FP8 实现。使用 transformer 引擎库提供的 Cast + Transpose ( C + T )融合内核将 GEM 层的输入转换为 FP8 , GEM 输出以 FP16 精度保存。 FP8 GEMM 层可使端到端培训时间提高 29% 。在图 3 中,灰色的 C ++操作是冗余的,仅用于说明目的。 FP8 GEMM 层使用 transformer Engine 库后端的 cuBLAS 库。
FP8 的效率更高,融合多头注意力
在这一轮中,我们根据 FlashAttention 算法实现了一种不同版本的融合多头注意力,它对 BERT 用例更有效。
此实现不写入前向通道中的 softmax 输出或丢弃掩码,以用于后向通道。相反,它重新计算后向通道中 softmax 输出,并使用直接来自前向通道的随机数生成器状态来重新生成后向通道的丢弃掩码。
这种方法更有效,特别是当由于寄存器压力降低而使用 FP8 输入和输出时。其结果是端到端培训时间提高了 8% 。
使用数据集打包最小化开销
以前,对于小规模,我们使用了一种非填充策略,以最小化因序列长度和额外填充而产生的开销。
另一种方法是 pack 以几乎完全填充批处理矩阵的方式对序列进行处理,使得额外的填充可以忽略,同时在迭代期间保持缓冲区大小不变。
在我们的最新提交中,我们使用了序列打包算法来预处理中小规模( 64 GPU 或更少) NVIDIA Hopper 提交的训练数据。这与前几轮中采用的 1024 GPU 及更大规模的技术类似。
将 CPU 预处理与 GPU 操作重叠,以提高训练时间
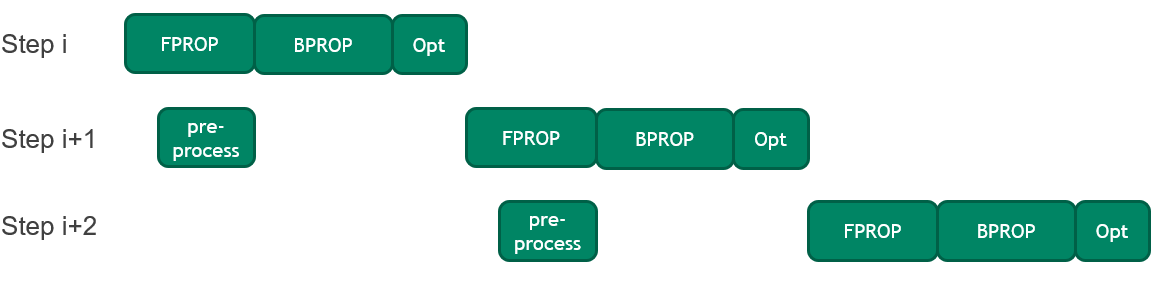
BERT 中的每个训练步骤都涉及在将 CPU 上的输入序列(也称为小批量)复制到 GPU 之前对其进行预处理。
在这一轮中,引入了一种优化方法,将当前小批量的前向传递执行与下一个小批量的预处理相结合。这种优化减少了闲置 GPU 时间,这在 GPU 执行速度加快时尤为重要。它使端到端培训时间提高了 2% 。
针对 H100 优化的新超参数和批量大小
凭借基于 NVIDIA Hopper 架构的新型 H100 Tensor Core GPU ,吞吐量随着本地批量大小的增长而增长。因此,我们增加了每批加速器的大小,并相应地优化了训练超参数。
ResNet-50 型
在这一轮 MLPerf 中,我们将卷积和内存绑定操作的融合扩展到外延融合之外,并提高了池化操作的性能。
Conv BN fprop 融合
ResNet-50 模型由 Conv- > BN- > Relu- > Conv- > BN- > Relu 模式组成,当执行内存绑定规范化层时,导致 Tensor 核心闲置。
在 MLPerf 培训 2.1 中,BatchNorm分为BatchNorm Stats计算和BatchNorm Apply。
NVIDIA GPU 的可编程性使我们能够在上一次卷积的尾波中融合统计数据计算,并在下一次卷积主循环中融合fuse Apply。
然而,对于权重梯度计算,这意味着必须通过融合wgrad中的BatchNorm Apply和ReLu来重新计算输入。使用 cuDNN 中的新的高性能内核,这一特性为小规模带来了 4.2% 的端到端加速。
更快的池操作
ResNet-50 模型在主干和分类器块中采用maxPool和AvgPool操作。通过使用 cuDNN 中的新图形 API ,并利用 NVIDIA H100 Tensor Core GPU 中更高的 DRAM 带宽,我们将池化操作速度提高了 3 倍以上。这导致 MLPerf Training v2.1 的速度提高了 3% 以上。
视网膜网
本轮 MLPerf 中 RetinaNet 的主要优化是改进 NVCOCO 库中的分数计算,以消除最大规模提交的 CPU 瓶颈。其他优化包括新的融合、扩展 CUDA 图的范围以减少 CPU 开销,以及使用 DALI 库来改进评估阶段的数据预处理。
NVCOCO :加速得分
随着 GPU 执行速度的加快,在 CPU 上执行的代码部分可能会限制性能。在每 GPU 执行的工作量较小的大范围内尤其如此。
目前,评估阶段的 mAP 度量计算在 CPU 上运行,这是我们之前提交的最大规模中的性能瓶颈。
在这一轮 MLPerf 中,我们优化了此评估计算,以消除 CPU 瓶颈,并使 GPU 优化发挥作用。这尤其有助于最大规模的提交。
C ++扩展也在 NVIDIA cocoapi 中进一步优化。对于其 mAP 度量计算,我们将 COCO 的性能比 original cocoapi implementation 提高了 3 倍,总体性能提高了 20 倍。这些优化主要集中于文件 I / O 、内存访问和负载平衡。
我们将 pybind11 替换为本机 C NumPy PyModules ,作为 Python 和 C ++之间的接口。通过在 C ++端直接读取 JSON 文件并与 Python 对象的 C Python 指针交互,我们消除了以前可能存在的深度副本。
此外,循环转换(如循环融合和循环重新排序)显著提高了多线程的缓存位置和内存访问效率。
我们在 OpenMP 中添加了更多的并行区域,以利用额外的并行性,并调整了任务调度,以更好地实现线程间的负载平衡。
度量计算中的这些优化总体上在 160 节点规模上实现了约 60% 的端到端性能改进。从关键路径中消除 CPU 瓶颈也使我们能够将最大规模从 160 个节点增加到 256 个节点。尽管实现目标精度所需的时间增加了,但这将使总训练时间减少约 30% 。
COCO 优化的总端到端加速是 2.3 倍。
扩展 CUDA 图:无同步 Adam 优化器
CUDA Graphs 提供了一种在没有 CPU 干预的情况下启动多个 GPU 内核的机制,从而减轻了 CPU 开销。
在 MLPerf Training v2.0 中, CUDA 图形在我们的 RetinaNet 提交中被广泛使用。然而,由于优化器实现中的 CPU- GPU 同步,梯度缩放和 Adam 优化器步骤被排除在图形捕获的区域之外。
在提交的 MLPerf Training v2.1 中, Adam 优化器进行了修改,以实现无同步操作。这使我们能够进一步扩展 CUDA 图的范围并减少 CPU 开销。
附加 cuDNN 运行时融合
除了先前提交的 MLPerf 中使用的 conv-bias-relu 融合外,通过使用 cuDNN 运行时融合,在 RetinaNet 主干中使用了 conv-scale-bias-relu-fusion 。这使我们能够避免内核启动延迟和数据移动,从而实现 1.5% 的端到端加速。
评估期间使用 NVIDIA DALI
在训练通行证中取得了显著的提速,从而增加了评估阶段所花费的时间比例。
NVIDIA DALI 以前在培训期间使用,但在评估期间未使用。为了解决相对较慢的评估迭代时间,我们使用 DALI 来有效地加载和预处理数据。
面罩 R-CNN
在这一轮 MLPerf 中,除了改进 Mask R-CNN 不同块的并行化之外,我们启用了新的内核融合,并减少了训练迭代中的 CPU 开销。
更快的 JSON 解释器
从 ujson 切换到 orjson 将 COCO 2017 注释文件的加载时间缩短了约 1.5 秒。
更快的评估和 NVCOCO 优化
我们使用为 RetinaNet 解释的 NVCOCO 改进,将所有 Mask R-CNN 配置的端到端时间缩短了约 2 秒。平均而言,这些优化将每个历元的评估时间减少约 2 秒,但只有最后一次评估在端到端时间内公开。
优化后的 NVCOCO 库是一个即时替代品,使最终用户可以直接使用优化。
矢量化批量 ROI 对齐
感兴趣区域( ROI )对齐执行双线性插值,这需要大量的数学工作。由于这项工作对于所有通道都是相同的,因此在通道维度上进行矢量化可将所需的工作量减少约 4 倍。
计算启动配置的方式也进行了更改,以避免启动超出需要的 CUDA 线程。
综合这些努力, ROI Align 正向传播的性能提高了约 5 倍。
在模型代码中展示更多的并行性
与大多数模型一样, Mask R-CNN 包含了许多可以并行执行的代码段。例如,遮罩水头损失计算涉及计算多个提案的损失,其中每个提案的损失可以独立计算。
我们通过识别这些可以并行化的部分并将它们放在单独的 CUDA 流上,实现了 3-5% 的加速。
删除更多 CPU- GPU 同步
在没有使用 CUDA 图的代码部分, GPU 内核从 CPU 代码启动。 CPU 代码主要执行簿记任务,如管理内存、跟踪指针和索引等。
如果 CPU 代码不够快, GPU 内核将在下一个内核启动之前完成并处于空闲状态。将 CPU 性能提高到代码的 CPU 部分比 GPU 部分运行得更快的程度对于最大化训练性能至关重要。这需要一定量的 CPU 提前运行。
CPU- GPU 同步防止了这一点,因为它们会使 CPU 保持空闲状态,直到当前 GPU 工作完成,因此删除 CPU- GPU 同步对训练性能也至关重要。
我们在过去的几轮提交中使用 NVIDIA A100 Tensor Core GPU 完成了这项工作。然而, NVIDIA H100 Tensor Core GPU 提供的显著性能提高需要删除更多这些 CPU- GPU synchronization 。
这对 NVIDIA A100 Tensor Core GPU 的结果影响很小,因为 CPU 开销不像 Mask R-CNN 上的 GPU 。然而,对于 32- GPU 配置,它将 H100 Tensor Core GPU 的性能提高了 25-30% 。
RPN 和 FPN 中的运行时融合
在前几轮中,我们使用cudnn v8 API 为 Mask R-CNN 的 ResNet-50 主干执行运行时融合,从而加快了代码的速度。
在这一轮中, RetinaNet 利用先前的工作将运行时融合扩展到 RPN 和 FPN 模块,进一步将端到端性能提高约 2% 。
AI 性能提高 6.7 倍
基于 NVIDIA Hopper 架构的 NVIDIA H100 GPU 为 NVIDIA AI 平台带来了下一个巨大的性能飞跃。与首次提交的 A100 GPU 相比,它的性能提高了 6.7 倍。
仅通过软件改进, A100 GPU 在最新一轮中的性能就比首次提交的高出 2.5 倍,展示了 NVIDIA AI 平台持续的全栈创新。
用于 NVIDIA MLPerf 提交的所有软件都可以从 MLPerf 存储库中获得,您可以复制我们的基准测试结果。我们不断将这些前沿的 MLPerf 改进融入到我们的深度学习框架容器中。这些容器是 available on NGC ,我们用于 GPU 优化应用程序的软件中心。




