深度学习模型需要大量数据才能产生准确的预测,随着模型规模和复杂性的增加,这种需求日益迫切。即使是大型数据集,例如拥有 100 多万张图像的著名 ImageNet ,也不足以在现代计算机视觉任务中实现最先进的结果。
为此,需要使用数据增强技术,通过对数据引入随机干扰(如几何变形、颜色变换、噪声添加等),人为地增加数据集的大小。这些干扰有助于生成预测更稳健的模型,避免过度拟合,并提供更好的精度。
在医学成像任务中,数据扩充至关重要,因为数据集最多只包含数百或数千个样本。另一方面,模型往往会产生需要大量 GPU 内存的大激活,特别是在处理 CT 和 MRI 扫描等体积数据时。这通常会导致在小数据集上进行小批量的培训。为了避免过度拟合,需要更精细的数据预处理和扩充技术。
然而,预处理通常对系统的整体性能有重大影响。这在处理大输入的应用程序中尤其如此,例如体积图像。由于 NumPy 等库的简单性、灵活性和可用性,这些预处理任务通常在 CPU 上运行。
在某些应用中,例如医学图像的分割或检测,由于数据预处理通常在 CPU 中执行,因此训练期间的 GPU 利用率通常不理想。解决方案之一是尝试完全重叠数据处理和训练,但并不总是那么简单。
这样的性能瓶颈导致了鸡和蛋的问题。由于性能原因,研究人员避免在他们的模型中引入更高级的增强,并且由于采用率较低,库不会将精力放在优化预处理原语上。
GPU 加速解决方案
通过将数据预处理卸载到 GPU ,可以显著提高具有大量数据预处理管道的应用程序的性能。 GPU 在此类场景中通常未得到充分利用,但可用于完成 CPU 无法及时完成的工作。其结果是更好的硬件利用率,最终更快的培训。
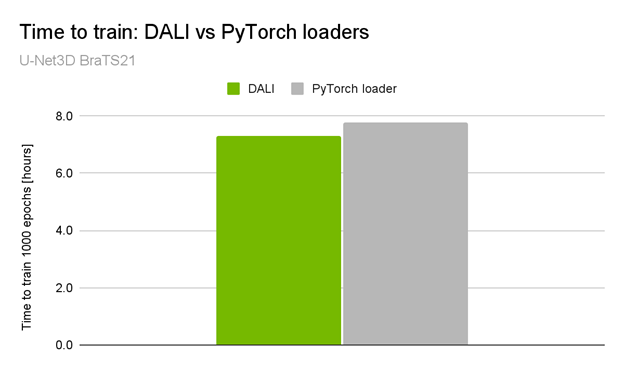
就在最近, NVIDIA 在 MICCAI 2021 脑肿瘤分割挑战中获得 10 个顶级排名中的 3 个 ,包括获胜的解决方案。获胜的解决方案通过加快系统的 preprocessing pipeline 速度,使 GPU 利用率高达 98% ,并将总训练时间减少了约 5% ( 30 分钟)(图 1 )。
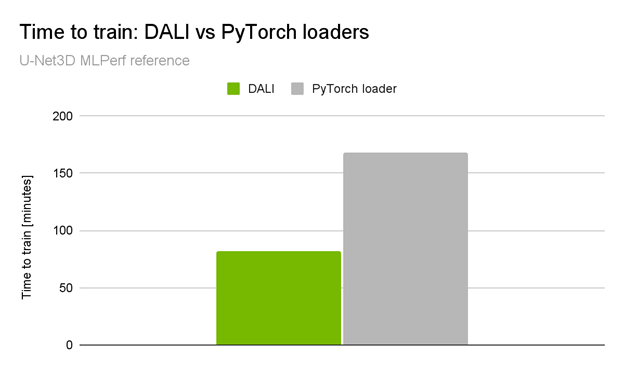
当你查看NVIDIA 提交的[VZX333 ]时,这种差异变得更加显著。它使用了与BraTS21获奖解决方案相同的网络体系结构,但具有更复杂的数据加载管道和更大的输入量(KITS19数据集)。与本机管道相比,性能提升是令人印象深刻的2倍端到端培训加速(图2)。
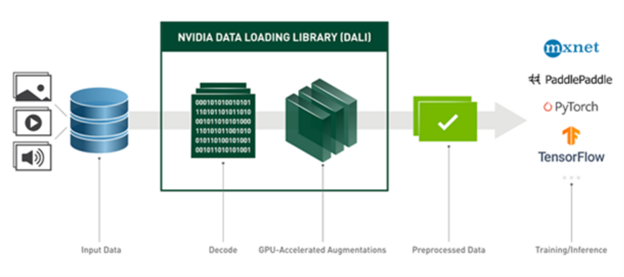
这是由 NVIDIA 数据加载库( DALI ) 实现的。 DALI 提供了一组 GPU 加速构建块,使您能够构建完整的数据处理管道,包括数据加载、解码和扩充,并将其与所选的深度学习框架集成(图 3 )。
体积图像操作
最初, DALI 是作为图像分类和检测工作流的解决方案开发的。后来,它被扩展到其他数据域,如音频、视频或体积图像。有关体积数据处理的更多信息,请参阅 3D Transforms 或 NumPy 读卡器 .
DALI 支持多种图像处理操作员。有些还可以应用于体积图像。以下是一些值得一提的例子:
- Resize
- Warp affine
- Rotate
- 随机对象边界框
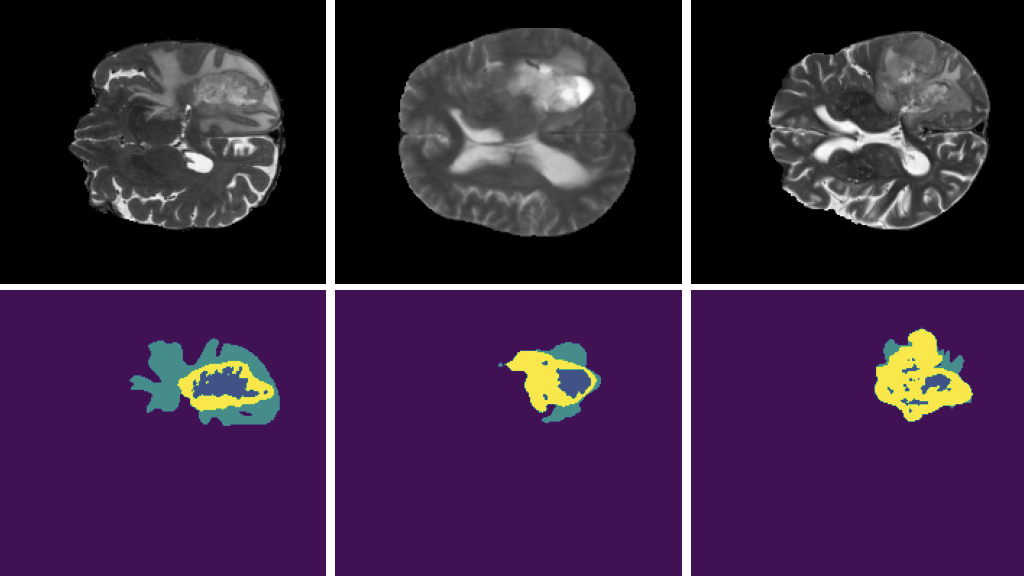
为了展示上述的一些操作,我们使用了来自 BraTS19 数据集的一个样本,该样本由标记为脑肿瘤分割的 MRI 扫描组成。图 4 显示了从脑 MRI 扫描体积中提取的二维切片,其中较暗的区域表示标记为异常的区域。
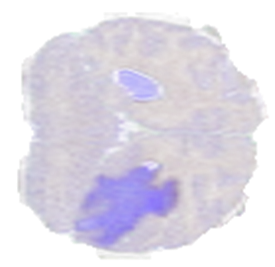
调整大小运算符
Resize 通过插值输入像素将图像放大或缩小到所需形状。可以分别为每个维度配置“高比例”或“低比例”,包括选择插值方法。
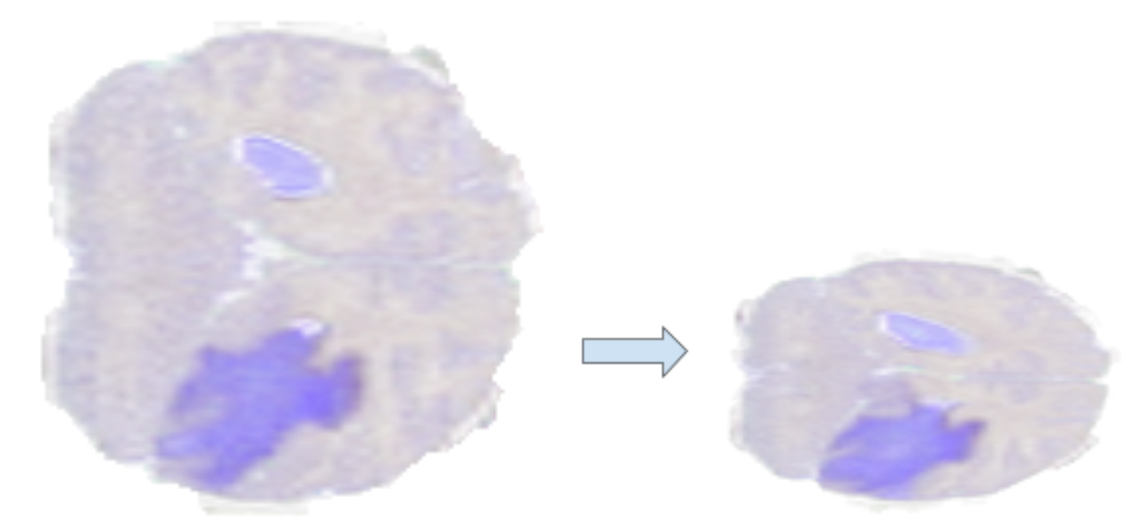
扭曲仿射算子
Warp affine 通过线性变换将像素坐标从源映射到目标,应用几何变换。
Warp affine 可用于一次性执行多个变换(旋转、翻转、剪切、缩放)。
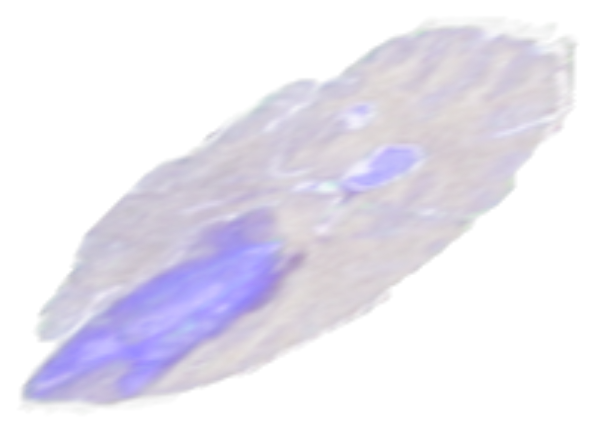
旋转运算符
Rotate 允许您绕任意轴旋转体积,该轴作为矢量和角度提供。它还可以选择性地扩展画布,使整个旋转图像包含在其中。图 7 显示了旋转体积的示例。
随机对象边界框操作符
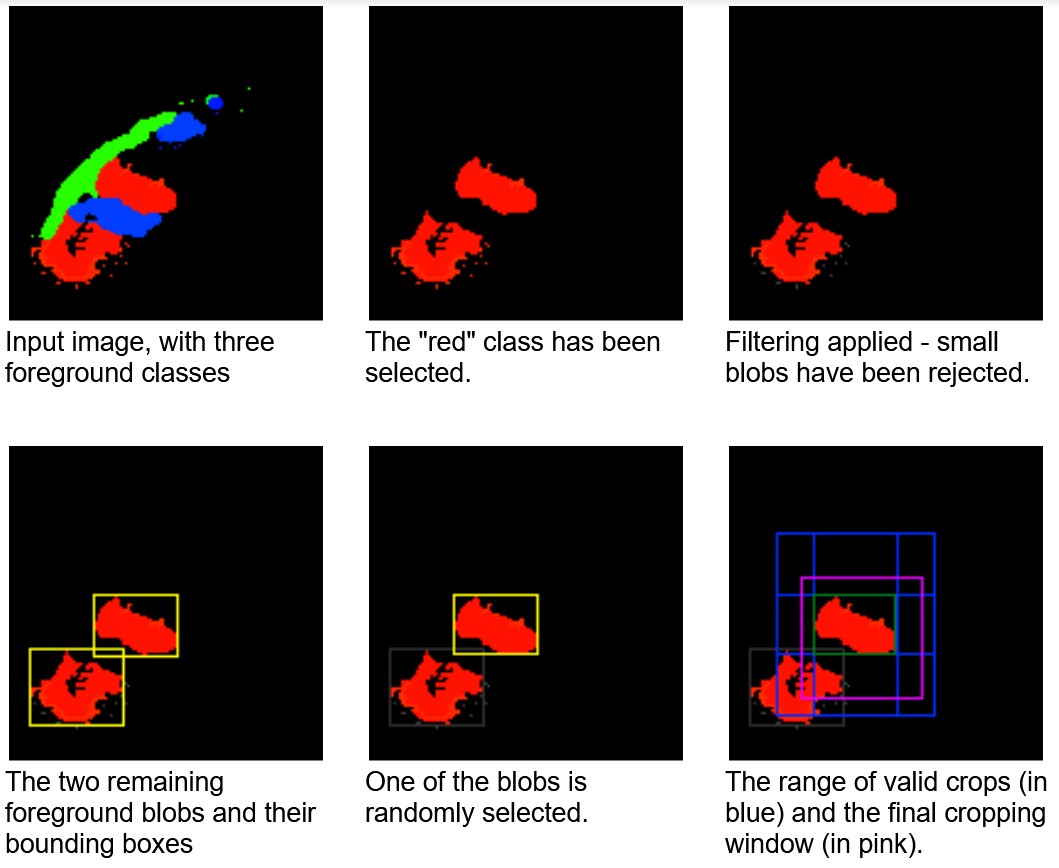
随机对象边界框 是一种适合于检测和分段任务的运算符。如前所述,医疗数据集往往相当小,目标类别(如异常)占据的区域相对较小。此外,在许多情况下,输入容量远大于网络预期的容量。如果要使用随机裁剪窗口进行训练,则大多数窗口不会包含目标。这可能导致训练收敛速度减慢或使网络偏向假阴性结果。
此运算符选择可能偏向于对特定标签采样的伪随机作物。连接组件分析是在标签图上执行的一个预步骤。然后,以相同的概率随机选择一个连接的 blob 。通过这样做,操作符可以避免过度呈现较大的斑点。
您还可以选择将选择限制为最大的 K 个 blob 或指定最小 blob 大小。选择特定 blob 时,将在包含给定 blob 的范围内生成随机裁剪窗口。图 8 显示了这个裁剪窗口选择过程。
学习速度的提高是非常显著的。在 KITS19 数据集上, nnU Net 在使用 随机对象边界框 运算符的测试运行时段中, 2134 达到与 3222 个随机裁剪时段相同的精度。
通常,查找连接组件的过程很慢,但数据集中的样本数可能很小。操作员可以配置为缓存连接的组件信息,以便仅在培训的第一个历元中计算。
自己加速
您可以下载预构建和测试的 DALI pip packages 的最新版本。 TensorFlow 、 PyTorch 和 MXNet 的 NGC 容器集成了 DALI 。您可以查看许多 例子 并阅读最新的 发布说明 ,以获取新功能和增强功能的详细列表。
了解 DALI 如何帮助您加速深度学习应用程序的数据预处理。访问的最佳位置是 NVIDIA DALI 文档 ,包括许多 示例和教程 。你也可以看我们的节目 GTC 2021 年谈 DALI . DALI 是一个开源项目,我们的代码可以在 /NVIDIA/DALI GitHub repo 上找到。我们欢迎您的反馈和贡献。




